







第一次写博客,不足之处请批评指正。
DB2分组函数ROLLUP和CUBE的使用
1. 初始化实验环境
1) 创建测试表group_test:
建表语句:create table group_test (group_id int not null,job varchar(10),name varchar(10),salaryint)
2) 初始化数据:
insert into group_test values (10,'Coding', 'Bruce',1000)
insert into group_test values (10,'Programmer','Clair',1000)
insert into group_test values (10,'Architect', 'Gideon',1000)
insert into group_test values (10,'Director', 'Hill',1000)
insert into group_test values (20,'Coding', 'Jason',2000)
insert into group_test values (20,'Programmer','Joey',2000)
insert into group_test values (20,'Architect', 'Martin',2000)
insert into group_test values (20,'Director', 'Michael',2000)
insert into group_test values (30,'Coding', 'Rebecca',3000)
insert into group_test values (30,'Programmer','Rex',3000)
insert into group_test values (30,'Architect', 'Richard',3000)
insert into group_test values (30,'Director', 'Sabrina',3000)
insert into group_test values (40,'Coding', 'Samuel',4000)
insert into group_test values (40,'Architect', 'Tina',4000)
insert into group_test values (40,'Director', 'Wendy',4000)
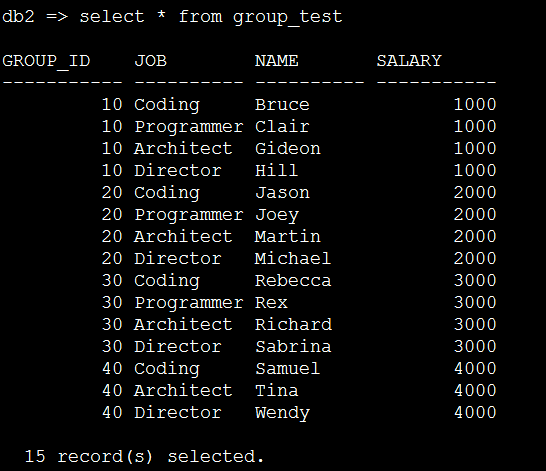
3) 初始化后数据情况如下:
select * from group_test
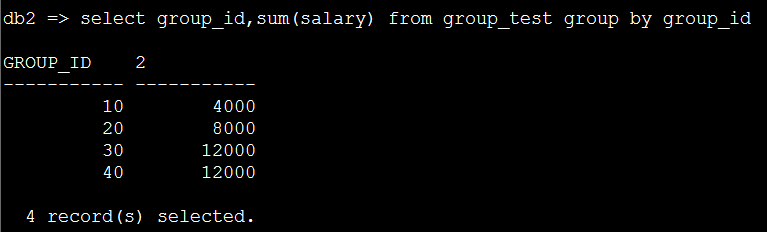
2. 先看一下普通分组的效果,对group_id进行普通的group by操作—按照小组进行分组
select group_id,sum(salary) from group_test group by group_id
3. DB2中ROLLUP和CUBE用法
DB2的GROUP BY语句除了最基本的语法之外,还支持ROLLUP和CUBE语句
如果是GROUP BY ROLLUP(A,B,C)的话,首先会对全表进行GROUP BY,然后对(A)进行GROUP BY,然后对(A,B)进行GROUP BY操作,最后对(A,B,C)进行GROUP BY操作。
如果是GROUP BY CUBE (A,B)的话,首先会对(B)进行GROUP BY,然后对全表进行GROUP BY,然后对(A)进行GROUP BY,最后对(A,B)进行GROUP BY操作。
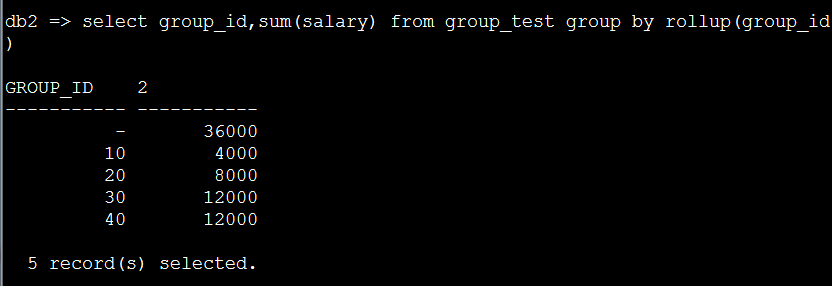
4. 对group_id进行普通的roolup一列的操作(最上面一行是分组统计结果)
select group_id,sum(salary) from group_test group by rollup(group_id)
5. 对group_id进行普通的cube一列的操作(最上面一行是分组统计结果)
select group_id,sum(salary) from group_test group by cube(group_id)
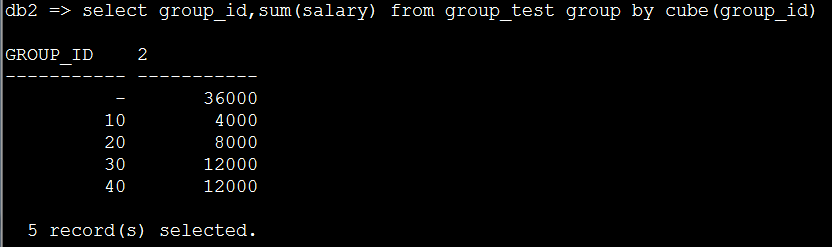
到目前为止还没看出来,rollup和cube的区别,别着急,下面就有了。
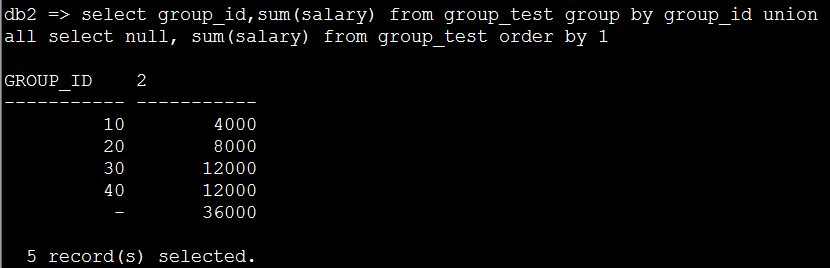
6. 用group by 语句翻译一下3、4的SQL语句如下:
select group_id,sum(salary) from group_test group by group_id union all select null,sum(salary) from group_test order by 1
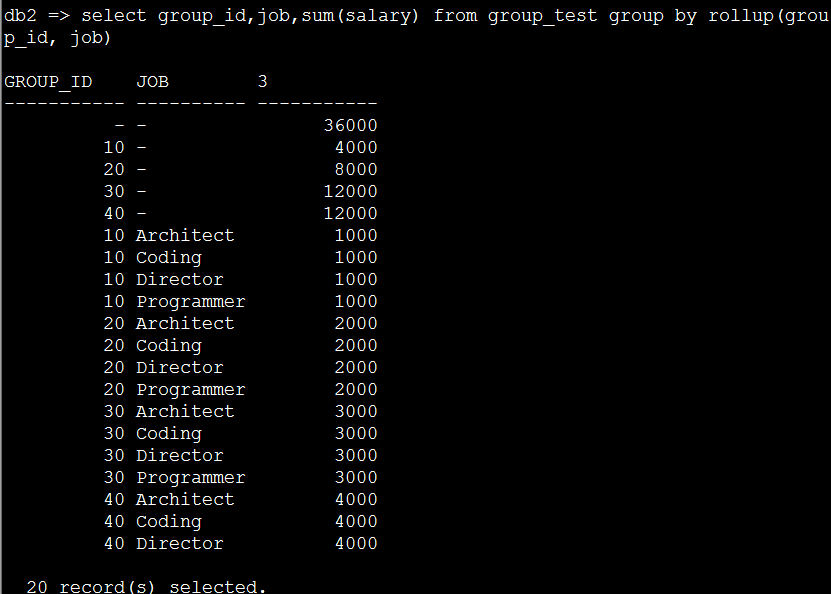
7. 看一个rollup两列的情况
select group_id,job,sum(salary) from group_test group by rollup(group_id, job)
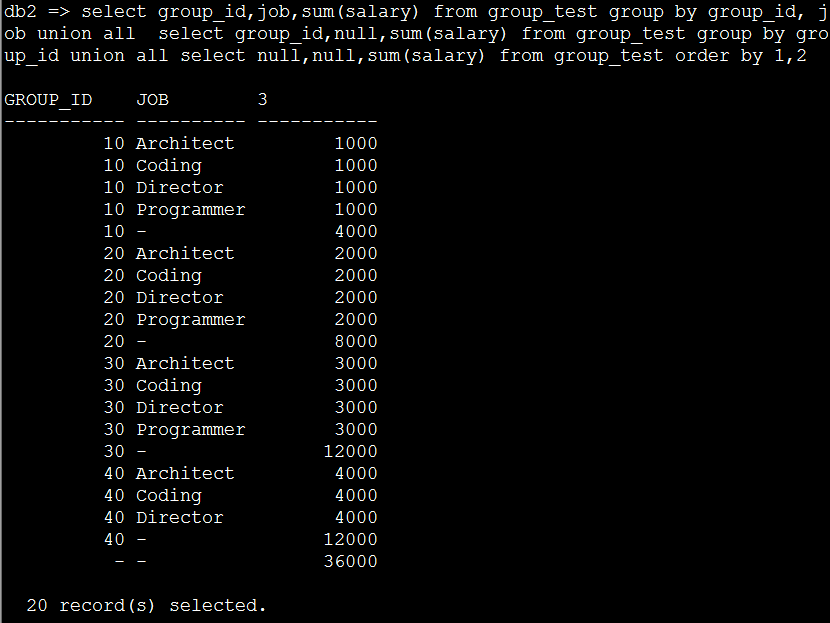
8. 用group by 语句翻译一下3、4的SQL语句如下:
select group_id,job,sum(salary) from group_test group by group_id, job union all select group_id,null,sum(salary) fromgroup_test group by group_id union all select null,null,sum(salary) fromgroup_test order by 1,2
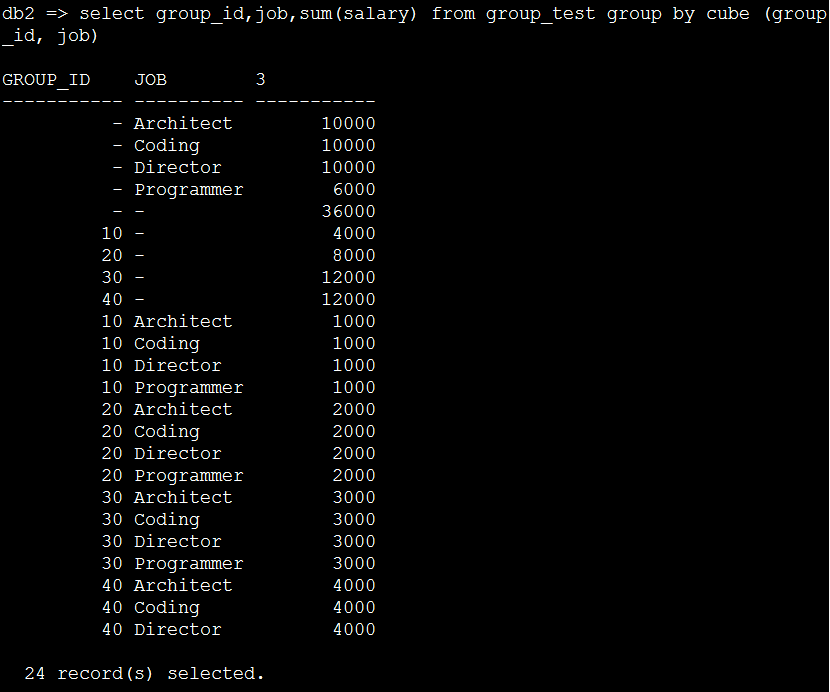
9. 看一个cube两列的情况
select group_id,job,sum(salary) from group_test group by cube (group_id, job)
10. GROUPING(COLUMN)使用
使用GROUPING()可以判断该行是数据库本来的行,还是统计产生的行。GROUPING值为0时说明这个值是数据库中本来的值,为1说明是统计的结果(也可以说该列为空时是1,不空时是0),根据这一特性,可以使显示结果更加人性化。
11. 加上GROUPING() 函数的效果(ROLLUP)
select group_id,job,grouping(GROUP_ID),grouping(JOB),sum(salary) from group_test groupby rollup(group_id, job)
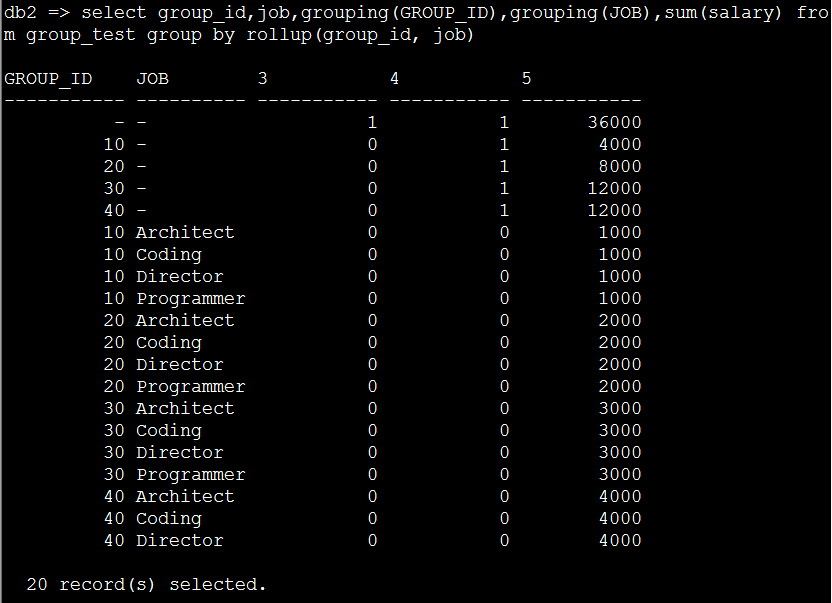
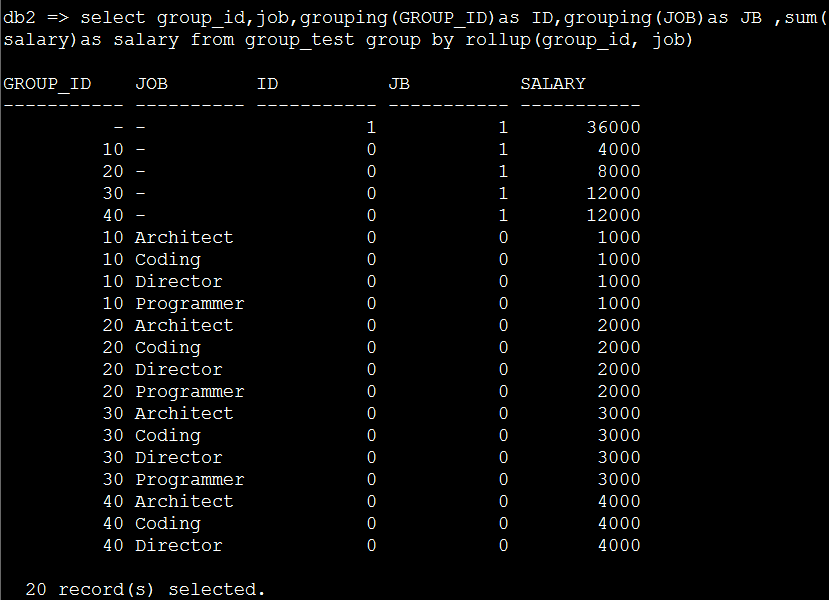
假名:selectgroup_id,job,grouping(GROUP_ID)as ID,grouping(JOB)as JB ,sum(salary)as salaryfrom group_test group by rollup(group_id, job)
12. 加上grouping函数的效果(CUBE)
select group_id,job,grouping(GROUP_ID),grouping(JOB),sum(salary) from group_test groupby cube(group_id, job)
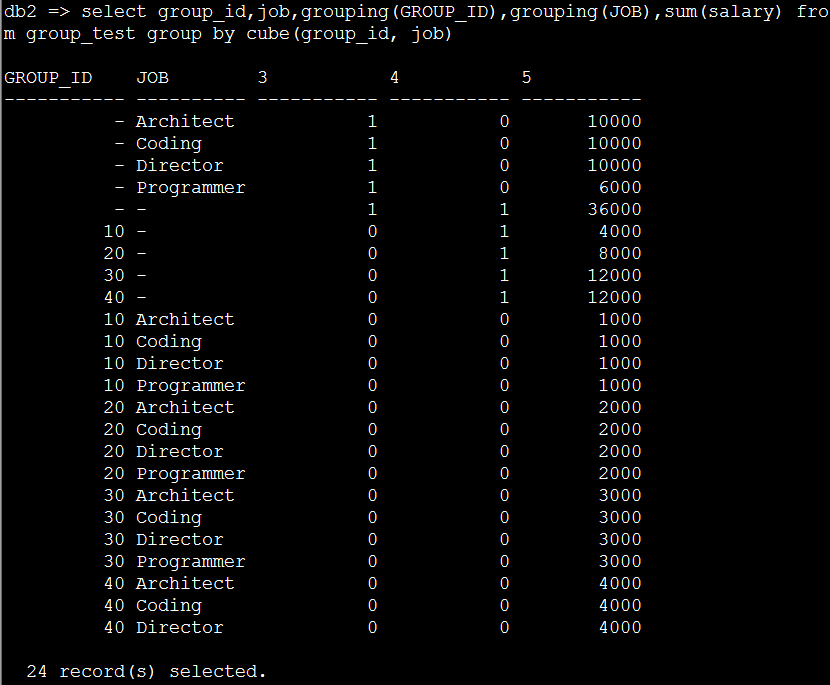
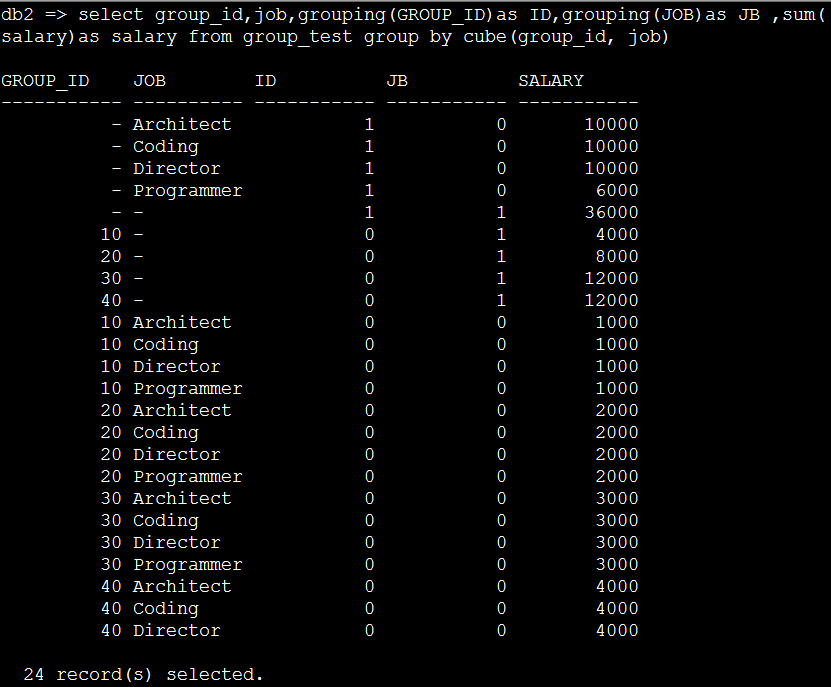
假名:select group_id,job,grouping(GROUP_ID)as ID,grouping(JOB)as JB,sum(salary)as salary from group_test group by cube(group_id, job)
13. 小结
ROLLUP和CUBE在数据统计和报表生成过程中带来极大的便利,而且效率比起来GROUP+UNION组合方式效率高很多。















 3840
3840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









