






本文着重介绍MapReduce详细的工作流程,这些知识可以让你更深刻的理解Mapreduce,编写高级的MapReduce项目。
MapReduce Job运行剖析
如果一个Job还没提交的话,可以通过运行submit()或者waitForCompletion()方法来运行一个MapReduce Job。在Hadoop 0.20及以上的版本中,mapred.job.tracker来确定Job执行的方式。如果这些配置为local(默认的),则用本地的Job Runner来运行程序,这些runner在一个单独的JVM中运行整个Job。这种设计是为了在小数据集上运行MapReduce程序。当然,若mapred.jon.tracker是一个由冒号分开的主机和端口,这个配置被解析为一个JobTracker地址,本地的runner则会提交job到该地址的JobTracker,具体的内容将会在下面说清楚。
在Hadoop 2.0中,有一种新的MapReduce实现方式,这种实现方式在一个叫YARN的系统是构建起来的。必须注意这个框架是用mapreduce.framwork.name来配置的。
- lcoal:本地的job runner;
- calssic:也叫MapReduce 1,用jobTracker和taskTracker;
- yarn:新的YARN框架
MapReduce 1
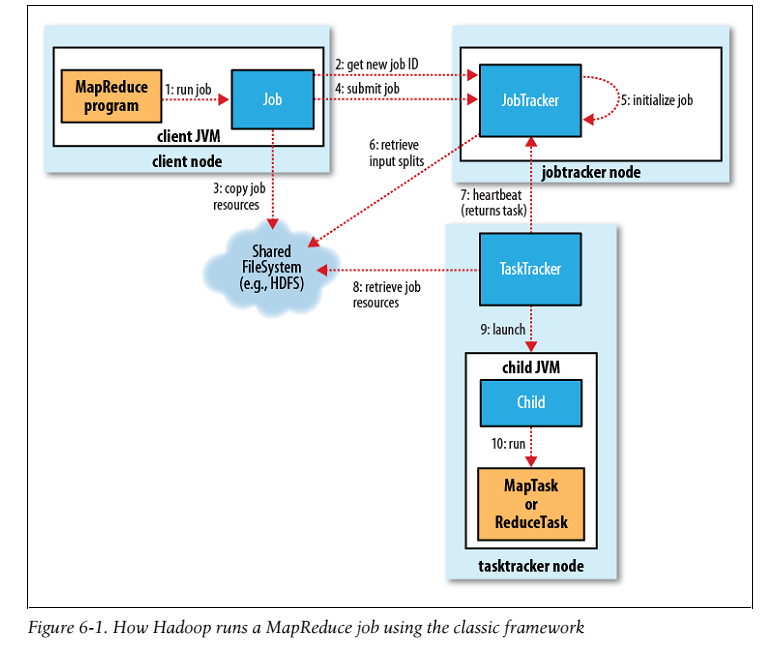
一个在MapReduce1 中运行的job的详细流程如图6-1所示,从大方面来说,有四个独立的模块:
- The Client 用来提交MapReduce Job;
- The jobTracker 用来协调Job工作的运行
- The taskTracker 运行被分割好的任务
- HDFS 用来在不同的模块间分享数据
Job Submit
首先调用Job的submit()方法会创建一个JobSummitter的实例,同时调用该实例的submitJobInternal()方法。(step1) 提交job之后,如果从上次提交到这次提交之间发生了改变,waitForCompletion()每秒钟向控制台提交job的进度。当job成功的完成了,会展示job counter,否则,引起job失败的错误的将会写到控制台。JobSummitter操作的job提交过程如下:
- 向jobTracker请求一个新的jobID(通过调用JobTracker的getNewJobId()方法)(step2)
- 核对该job的输出说明。例如,如果输出结果的文件夹没有被指定或者已经存在,那么该Job则不会提交,且抛出一个错误。
- 计算该Job的输入分割(input split),如果不能分割(输入文件的路径不存在),该job就不会被提交,且抛出一个错误。
- 复制需要运行该Job的资源到jobTracker的文件系统下的以jobID命名的文件下。包括 job JAR file,配置文件,计算好的输入分割。job JAR file 可以被快速复制,因此当运行Job的task时,taskracker可以通过集群访问这些复制的JAR file。 (step3)
- 告诉jobTracker,job已经准备好了,可以调用JobTracker的submitJob()。(step4)
Job初始化
当一个JobTracker收到一个调用它的submitJob() 请求,它将这个请求放入一个内部栈里面,在这个栈里面,JobTracker会找到该请求,并初始化。初始化时将会创建一个对象来表示job正在运行,该对象封装了它的任务,同时记录了任务的状态和进度。(step5)
为了创建一系列要运行的task,job scheduler 首先遍历HDFS中客户端计算的输入分割(input splits),(step6),然后为每一个分割创建map task,reduce task的数量是由Job中的mapred.reduce.tasks来配置的,可以通过setNumReduceTasks()来设置。同时给予每一个任务一个Id。还要创建两个task,设置任务(job setup task)和清除任务(job cleanup task).设置任务用来在map任务运行之前设置job,清除任务用来在所有的reduce任务之后清除一些配置和内容。OutputCommitter用来配置job中要运行的代码,默认的是FileOutputCommitter。对设置任务来说,它将要创建job最终的输出文件夹和task输出的临时文件夹。对清除任务来说,它将要删除task产生的临时文件。
任务分配
TaskTracker运行一个简单的循环向jobTracker周期性的发送心跳。心跳告诉JobTracker TaskTracker是活的,他们也可以把该心跳作为一个通道来作为双方的通信的桥梁。心跳的一部分内容可以用来告诉jobTracker TaskTracker是否要准备运行一个新的任务,是的话,jobTracker就会分配一些任务给这个TaskTracker,这个任务通过心跳返回value来与taskTracker通信。(step7)在为一个taskTracker选择一个task之前,jobTracker必须选择那个task属于的job,存在各种各样的算法,默认的是简单地维持一个job 链表,选择一个job之后,jobtracker对这个job选择一个task。TaskTracker为map tasks和reduce tasks提供固定数目的插槽(slot),这些插槽是相互独立的。举个例子,一个taskTracker可能配置能够同时运行两个map task和reduce task。对于一个给定的job,job scheduler 先在插槽内填充map task,再填充reduce task。
任务执行
现在taskTracker被分配了一个任务,下一步就是执行任务。首先,它会从HDFS中复制 job JAR到taskTracker的文件系统,然后复制其他需要的文件。(step8)。其次,它为这个任务创建一个本地的工作目录,同时解压JAR的内容到这个目录中。最后,它会为这个将要运行的任务创建一个TaskRunner实例。TaskRunner构建一个新的JVM**(step9)**来运行每一个任务,因此map和reduce方法的错误不影响taskTracker。同时,这样的话,就有可能去重用JVM。子进程通过中央接口与taskRunner通信,每隔几秒告诉taskRunner该任务的进度,直到该任务结束。每一个任务都会执行设置(setup)和清除(cleanup)行为,这两个行为和任务运行在一个JVM中。清除行为用于提交任务,对于一个基于文件的job来说,调用了cleanup就意味着这个任务最后的输出已经写入指定的位置。这个提交协议确保当是预测执行(speculative execution)的状态时,只有一个副本任务被提交,其余的被终止。
流(stream)和管道(pipes)
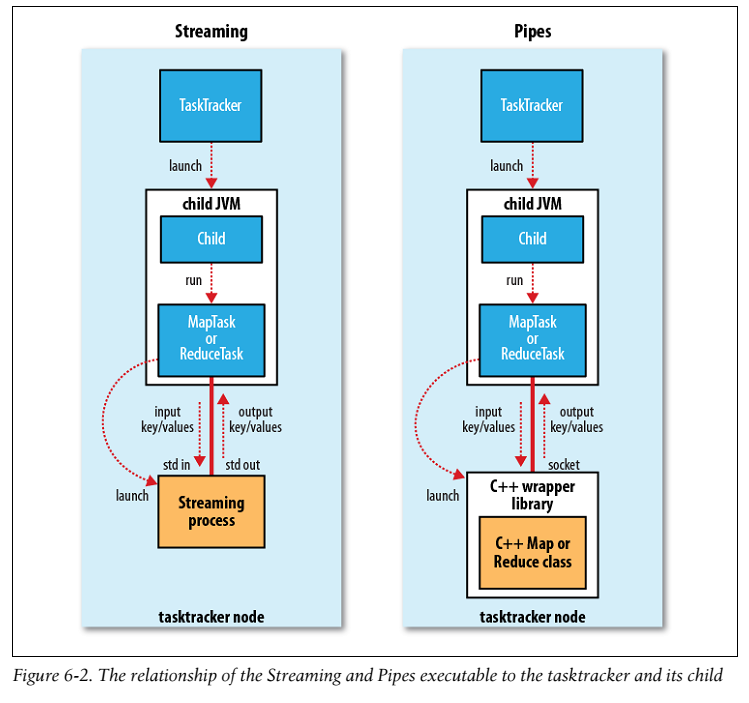
流和管道都可运行用户提供的map和reduce任务。在用流的情况下,流任务(streaming task)用标准的输入输出流与进程进行交互。管道任务则是侦听一个socket同时传递给一个C++进程一个能够启动端口号,这个C++进程能够建立一个长连接和它的上层JAVA pipe 任务交互。不论是哪一种情况,java 进程传递input key—value 键值对到外部进程,这个外部进程运行用户定义的map或者reduce方法,然后传递output key—value 返回给Java 进程。从taskTracker的角度来看,好像是他自己的子进程运行的。如图 6-2
进度和状态的更新
MapReduce Jobs一般是长时间运行的 job块,从几分钟到几个小时不等。这是一个很长的时间,因此对用户来说job的运行反馈非常重要。每一个job和它的任务都有一个身份(status),包括job和task的状态(成功和失败)、map和reduce 的进度,job counter的值、一个身份信息或者描述信息。这些状态会随着job的运行而更改,但是它是如何与client进行通信的呢?
当一个task运行的时候,它知道自己的进度。对map任务来说,就是input数据被处理的比例。对reduce来说,有点复杂,但是系统能够预估给reduce的输入(input)处理了多少。系统根据洗牌(shuffle)的三个阶段将整个进度华为三部分。举个例子,加入任务已经运行了reducer的input的一半,那么整个任务的进度已经运行了5/6,因为它已经完成了复制(copy)和排序(sort)阶段(各占1/3),同时运行reduce阶段的一半(1/6)。
如果一个task向上级报告进度,它会设置一个标签来表示状态的改变。这个标签在一个其他的进程中每隔三秒被核对一次,如果发生了改变,这件进程将会通知taskTracker目前的状态。同时,taskTracker每隔五秒向jobTracker发送一次心跳,这个心跳包含这个taskTracker运行的所有task的状态。计数器(counter)被发送的时间要比5秒长,因为相对来说需要更多的带宽。jobTracker合并这些更新状态并产生一个包含所有正在运行的job及job内任务的全局状态视图。最后Job 收到jobTracker每秒钟提供的状态。客户端通过调用Job的getStatus()来获取一个JobStatus实例,这个实例中包含这个job中所有的实例。如图6-3:
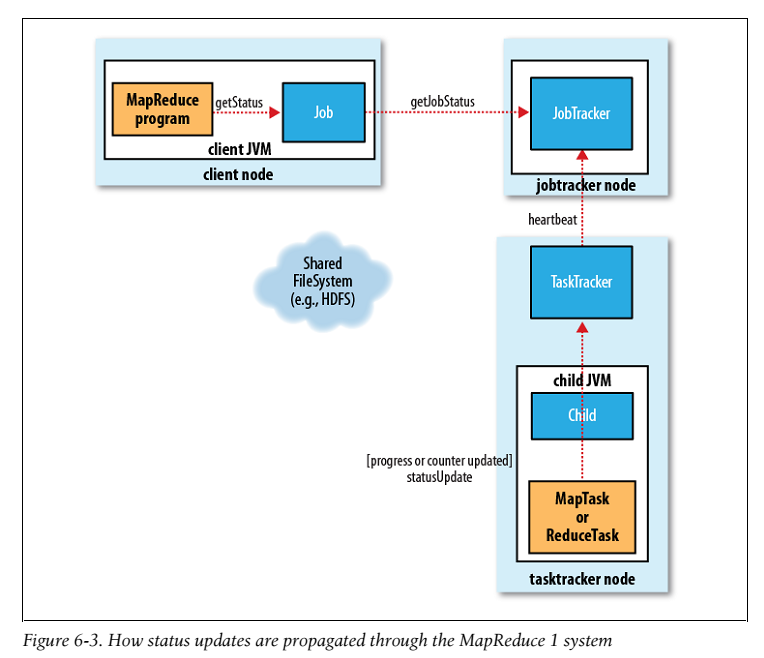
当一个jobTracker收到一个通知最后一个task已经完成了(cleanup task),它改变这个job的状态为successful。当The Job询问状态的时候,发现这个job已经成功,因此它用waitForCompletion()打印一个信息告诉user,Job统计的信息和counter在控制台打印。如果你配置job.end.notification.url的话,jobTracker也可能发送一个HTTP job 通知。最后,jobTracker清除它的工作状态同时告诉taskTracker做同样的工作(删除map产生的中间层的output)。















 4026
4026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









