






目录
验证地址空间排布
在学习C语言是应该都见过这张地址空间分布图:
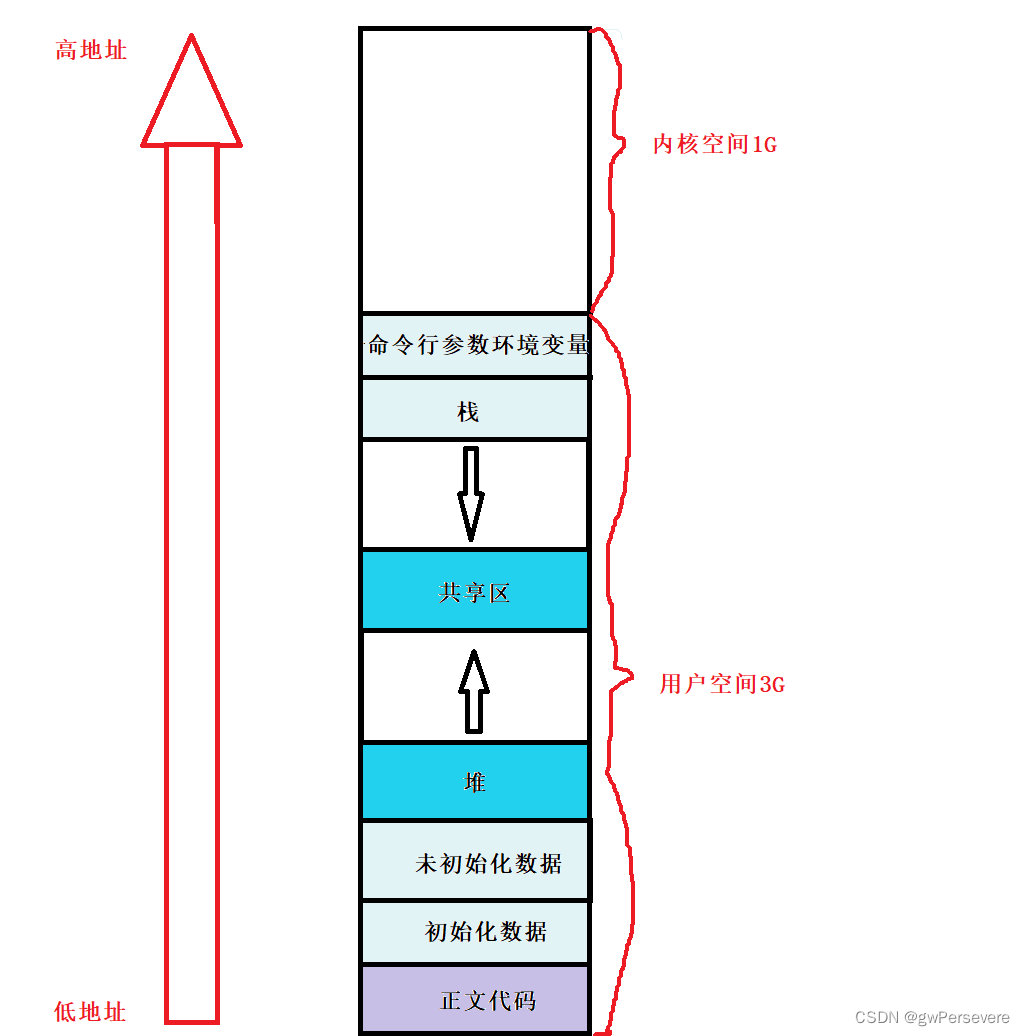
接下来我们先验证这个地址分布图:
代码:
#include<stdio.h> #include<stdlib.h>
int un_val;
int val = 100;
int main( int argc, char *argv[], char* env[] )
{
printf("code address:%p \n", main);//正文代码的地址
printf("val : %p\n", &val);//初始化变量的地址
printf("un_val : %p\n",&un_val );//未初始化变量的地址
int* arr1 = (int*)malloc(sizeof(int));
int* arr2 = (int*)malloc(sizeof(int));
int* arr3 = (int*)malloc(sizeof(int));
int* arr4 = (int*)malloc(sizeof(int));
printf("heap address 1 %p\n",arr1); //堆地址
printf("heap address 2 %p\n",arr2);
printf("heap address 3 %p\n",arr3);
printf("heap address 4 %p\n",arr4);
printf("stack address 1 :%p\n",&arr1);//栈地址
printf("stack address 2 :%p\n",&arr2);
printf("stack address 3 :%p\n",&arr3);
printf("stack address 4 :%p\n",&arr4);
int i = 0;
for(i = 0;i < argc; i++)
{
printf("argv[%d] : %p\n",i, argv[i]);// 命令行地址
}
for(i = 0; env[i]; i++)
{
printf("env[%d]: %p\n",i,env[i]);// 环境变量地址
}
return 0;
}

代码结果如上图 我们可以看出地址排布与分布图一致,需要注意的是堆区是从低地址向上分布,而栈区是从高地址向下分布。

另外我们知道当双击程序开始执行时,实际上就已经建立了进程,所以打印各个地址,就是进程打印地址。
什么是地址空间?
我们举个例子:
一个拥有10亿的富翁,有三个私生子,A , B ,C,他们都不知道个各自的存在。那么他们自己认为自己将继承父亲的全部资产,但是我们从上帝的视角看并不是这样。
其实我们可以类比:
父亲是操作系统
进程是儿子
从儿子视角看到的资产就是地址空间,这个地址空间就是虚拟内存。
而从上帝的视角看到的资产就是物理内存。
我们想一下这个父亲有多个儿子,每个儿子每次找他父亲要钱,他父亲需要记录吗,假设并不需要记录,那么从他父亲的角度看待他剩余的资产和从儿子的角度看待剩余资产是不同的,那当儿子给父亲要钱时可能存在父亲剩余的钱并没有这么多,但儿子认为父亲有这么多钱,这就出现了非常尴尬的情况,所以父亲需要记录每次给每个儿子的钱数。同样的操作系统也要对给进程的空间进行管理,其实内核中的地址空间本质上是一种数据结构,每个数据结构与特定的进程向匹配。
这时我们就知道了每个进程都有一个空间,并且这个空间并不是真实的。
其实在计算机发展过程中,也有过进程直接访问物理内存也就是真实的内存,这种情况下是非常不看全的,是为什么呢?
我们知道内存本身是可以随时被读写的,当进程1 、进程2、进程3全部加载到内存在,假设进程1中有一个野指针,并且对这个野指针进行操作,那么可能操作的是进程2或者进程3的内容,这就造成了不安全。所以不能直接使用物理内存。
那在现在计算机怎样解决这个问题呢
现代的计算机给每一个进程创建一个虚拟的地址空间从全0到全F。它在虚拟内存和物理内存之间添加了一个页表,也就是用虚拟地址向物理地址映射的机制,当一个程序加载到内存,那进程也就建立,相应的虚拟内存也就建立了,一个变量在物理内存的地址和在虚拟内存的地址是不同的,但是他们通过页表一一对应起来。如下图:

这是要访问物理空间就要通过页表映射。而不是直接访问物理空间。当虚拟地址是非法地址时页表就禁止了映射,这样上面说的安全问题就解决了。
如何理解区域划分?
假设我们两个是同桌共用一张一米的课桌,当闹别扭时就会在中间画条线表明可以各自可以使用的区间,那我用数据结构来表示就是:
struct destop
{
int start;
int end;
};
struct destop one = { 1, 50 };
struct destop one = { 51, 100 };这种方法本质就是区域划分,就是在一个范围内定义出start和end。
地址空间实际就是一种内核数据结构,它里面至少要有各个区域的划分:
struct addr_room
{
int code_start;
int code_end;
int init_start;
int init_end;
int uninit_start;
int uninit_end;
int heap_start;
int heap_end;
int stack_start;
int stack_end;
...
其他属性
};每个进程都会有一个地址空间,当程序定义的变量不同时,地址空间的每个区域的范围也可能发生变化,实际上所谓的范围变化本质就是对start或者end加减特定的范围。
那进程又是怎样操控或者控制虚拟地址内存的呢?
其实在进程的PCB中有指针指向虚拟地址空间。

看到了这里我们大概已经知道每个进程都拥有一个虚拟地址空间和页表(用户级页表)。那么怎样保证每个进程是独立的呢?其实只要保证每个进程的页表映射的物理内存是不同的区域就能做到进程之间不会互相干扰,保证独立性。
写时拷贝
了解了上面的内容,我们看一个代码 思考一个问题:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
int g_val = 100;
pid_t id = fork();
int count =0;
while(count<10)
{
if(id > 0)
{
printf("father ::PID : %d, g_val: %d ; &g_val: %p\n", getpid(), g_val, &g_val);
sleep(1);
}
else{
printf("child:: PID : %d, g_val: %d ; &g_val: %p\n", getpid(), g_val, &g_val);
count++;
if(count >= 5)
{
g_val =200;
}
sleep(1);
}
}
return 0;
}
父进程、子进程都打印同一个变量,同时也打印这个变量的地址,当运行5次循环后子进程更改变量的值。一起来看看结果:

我们可以看到①:父进程和子进程变量值相同,变量地址也相同。②变量值不同但是地址相同。
问题:地址相同那为什么值不同呢?看到这里相信这个题已经难不到大家了,因为这是打印的地址是虚拟地址。
我们来看一下底层是怎么实现的吧!
子进程开始运行时,会直接拷贝一份父进程的虚拟空间和页表,这时父进程的变量和子进程的变量在物理内存上是共用一块空间,但是当变量发生改变时,这时就会发生写时拷贝;也就是变量发生改变时,子进程会重新在物理内存上开辟空间存放变量,同时也会更改相应的页表,这时映射关系虽然变了,但是在虚拟空间中变量的地址并没有发生改变。所以就出现了上面的情况地址相同但是值不同

拓展:
在我们写好的程序,通过编译后,形成可执行程序,但是未被加载到内存之前,我们的程序内部有地址吗?
大多数同学看到这个问题时,肯定觉得没有地址,程序里面怎么会有地址。事实上在编译形成可执行程序时,程序内部就已经有了地址。
对于地址空间不要仅仅理解为是OS内部要遵守的,其实编译器也要遵守!!!即:编译器编译代码的时候,就已经给我们形成了各个区域,代码区、数据区等等,并且采用和Linux内核一样的编址方式,给每个变量,每行代码都进行了编址,故程序在编译的时候,每个字段早已经具有了一个虚拟地址。
当一个可执行程序加载到物理内存时,会给每个变量,每行代码分配新的地址储存(不仅储存值也要储存在编译过程中新城地地址);而虚拟内存则使用编译过程中形成的代码地址储存;这样页表就可将每个变量的物理地址和虚拟地址对应起来;如下图

也就是说程序内部的地址,依旧用的是编译器编好的虚拟地址,当程序加载到内存时,每行代码,每个变量便具有了一个物理地址。














 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









