







之前在“UFFS与dfs关系的文章里”提到过UFFS文件系统初始化的过程。
之前只提到了 uffs_Mount()这样的一个函数。
在 uffs_Mount()函数中我们可以找到这样一段代码:
if (uffs_InitDevice(mtb->dev) != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "init device fail !");
return -1;
}UFFS设备的加载函数:
RET uffs_InitDevice(uffs_Device *dev)
{
URET ret;
ret = uffs_InitDeviceConfig(dev);
if (ret != U_SUCC)
return U_FAIL;
if (dev->mem.init) {
if (dev->mem.init(dev) != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "Init memory allocator fail.");
return U_FAIL;
}
}
rt_memset(&(dev->st), 0, sizeof(uffs_FlashStat));
uffs_DeviceInitLock(dev);
uffs_BadBlockInit(dev);
if (uffs_FlashInterfaceInit(dev) != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "Can't initialize flash interface !");
goto fail;
}
uffs_Perror(UFFS_MSG_NOISY, "init page buf");
ret = uffs_BufInit(dev, dev->cfg.page_buffers, dev->cfg.dirty_pages);
if (ret != U_SUCC) {
uffs_Perror(UFFS_MSG_DEAD, "Initialize page buffers fail");
goto fail;
}
uffs_Perror(UFFS_MSG_NOISY, "init block info cache");
ret = uffs_BlockInfoInitCache(dev, dev->cfg.bc_caches);
if (ret != U_SUCC) {
uffs_Perror(UFFS_MSG_DEAD, "Initialize block info fail");
goto fail;
}
ret = uffs_TreeInit(dev);
if (ret != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "fail to init tree buffers");
goto fail;
}
ret = uffs_BuildTree(dev);
if (ret != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "fail to build tree");
goto fail;
}
return U_SUCC;
fail:
uffs_DeviceReleaseLock(dev);
return U_FAIL;
}首选让我们看一下 uffs_Device *dev 结构体:
/**
* \struct uffs_DeviceSt
* \brief The core data structure of UFFS, all information needed by manipulate UFFS object
* \note one partition corresponding one uffs device.
*/
struct uffs_DeviceSt {
URET (*Init)(uffs_Device *dev); //!< low level initialisation
URET (*Release)(uffs_Device *dev); //!< low level release
void *_private; //!< private data for device
struct uffs_StorageAttrSt *attr; //!< storage attribute
struct uffs_PartitionSt par; //!< partition information
struct uffs_FlashOpsSt *ops; //!< flash operations
struct uffs_BlockInfoCacheSt bc; //!< block info cache
struct uffs_LockSt lock; //!< lock data structure
struct uffs_PageBufDescSt buf; //!< page buffers
struct uffs_PageCommInfoSt com; //!< common information
struct uffs_TreeSt tree; //!< tree list of block
struct uffs_PendingListSt pending; //!< pending block list, to be recover/mark 'bad'/refresh
struct uffs_FlashStatSt st; //!< statistic (counters)
struct uffs_memAllocatorSt mem; //!< uffs memory allocator
struct uffs_ConfigSt cfg; //!< uffs config
u32 ref_count; //!< device reference count
int dev_num; //!< device number (partition number)
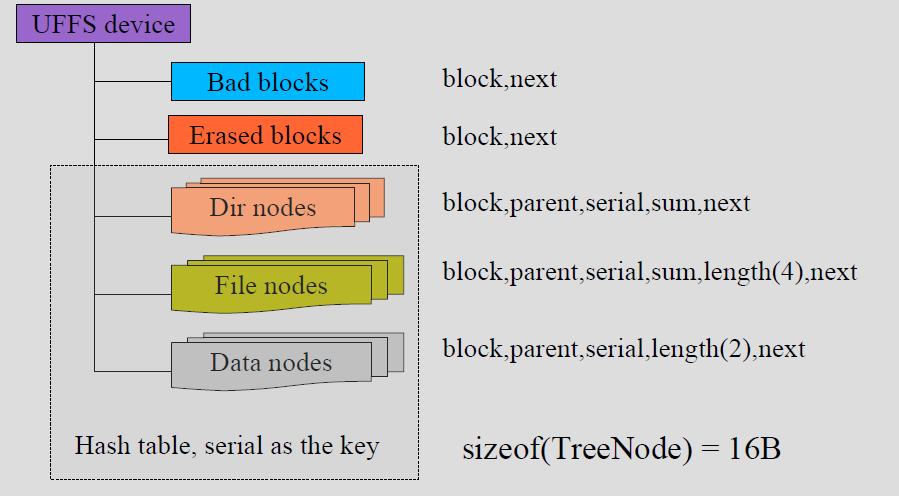
};- 这个结构体包含了在系统中一个具体UFFS设备的信息,包含“存储属性(Flash属性)”,“分区信息”,“Flash 操作函数”,“uffs运行占有内存管理”等等。 这里我比较关心的是struct uffs_TreeSt tree;该结构包含3个哈希表。在uffs查找文件,文件夹,文件数据时。全是通过这3个哈希表。
(注释:在这里我们要明白,文件夹对于flash来说,也是存储的数据,记录着文件夹层次关心,文件夹内包含文件,这些数据对于flash来讲,与普通文件A.txt文件并无区别。)
dir_entry : 文件夹链表
file_entry :文件链表
data_entry :数据链表 (当一个文件大于一个Nand叶存储时,用该链表记录下一块数据存储的位置)
2.让我们简化一下uffs_InitDevice 函数的代码:
uffs_InitDevice(uffs_Device *dev)
{
URET ret;
ret = uffs_InitDeviceConfig(dev);//读取UFFS加载的NandFlash信息
if (uffs_FlashInterfaceInit(dev) != U_SUCC)
ret = uffs_BufInit(dev, dev->cfg.page_buffers, dev->cfg.dirty_pages);
ret = uffs_BlockInfoInitCache(dev, dev->cfg.bc_caches);
ret = uffs_TreeInit(dev);
ret = uffs_BuildTree(dev);
}
uffs_FlashInterfaceInit()
uffs_BufInit()
uffs_BlockInfoInitCache()
uffs_TreeInit()
这4个函数是申请UFFS运行时所需要的内存,和结构链表,并且初始化这些这些结构和链表。一满足UFFS的运行。和接写了uffs_BuildTree函数的调用。
uffs_BuildTree函数会对全NandFlash进行扫描,讲内存里的链表信息和数据结构,真正的与当前所挂载的NandFlash关联起来。这块稍后说,先说一下上面4个函数内存使用状况。
UFFS文件系统内存消耗
下面的具体数据,是对一个拥有64个块的Nand进行加载的。一个叶2048字节
在UFFS初始化时,会申请四次内存。分别为:
1)在uffs_FlashInterfaceInit中, 申请 备份区缓存池。
#define UFFS_SPARE_BUFFER_SIZE (MAX_SPARE_BUFFERS * UFFS_MAX_SPARE_SIZE)
#define MAX_SPARE_BUFFERS 5 //* uffs_config.h 备份区缓存数量, 5足够了。 */
#define UFFS_MAX_SPARE_SIZE ((UFFS_MAX_PAGE_SIZE / 256) * 8)
#define UFFS_MAX_PAGE_SIZE 2048 //* nand基本信息 页大小 */
所以:_SPARE_BUFFER_SIZE 为 320
dev->mem.malloc(dev, UFFS_SPARE_BUFFER_SIZE);
2)在uffs_BufInit中,申请 页缓存池
dev->mem.malloc(dev, size);
size = (sizeof(uffs_Buf) + dev->com.pg_size) * buf_max;
(注::sizeof(uffs_Buf) = 40)
(注::dev->com.pg_size = 0x800 (2048))///每个页大小
attr->page_data_size = info->uNandSectorSize;//NAND_PAGE_DATA_SIZE; /* page data size */
(注::buf_max = 0xA (10)) MAX_PAGE_BUFFERS
#define MAX_PAGE_BUFFERS 10 //* uffs_config.h 页缓存块数。 */
(*注:该值越大,读写性能会越好。但是当该值大于每块的叶数,则改善读写性能不明显)
所以:: size = 0x5190 (20880)
3)在uffs_BlockInfoInitCache中,申请块信息缓存池。
dev->mem.malloc(dev, size);
size = (
sizeof(uffs_BlockInfo) +
sizeof(uffs_PageSpare) * dev->attr->pages_per_block
) * maxCachedBlocks;
(注::sizeof(uffs_BlockInfoSt) = 24 )
(注::sizeof(uffs_PageSpare) = 16 )
(注:: dev->attr->pages_per_block = 0x40 (64))//NAND_PAGES_PER_BLOCK; /* pages per block */
attr->pages_per_block = info->uNandBlockSize/info->uNandSectorSize;//NAND_PAGES_PER_BLOCK; /* pages per block */ //* nand基本信息 页大小 */
NAND_PAGES_PER_BLOCK //* nand基本信息 页大小 */
(注::maxCachedBlocks = 5)
#define MAX_CACHED_BLOCK_INFO 5 //* uffs_config.h 块的信息高速缓存 */
(*注: uffs 块的信息高速缓存,存储被打开的文件或者目录。 范围为5~MAX_OBJECT_HANDLE)
4)在uffs_TreeInit中,申请 tree节点缓存池。
dev->mem.malloc(dev, size * num);
num = dev->par.end - dev->par.start + 1;///总块数 For example64
(注:: sizeof(TreeNode)= 16)
(注::num = 总块数 For example 64)
所以:: size = 16 * 64( 1024)
总结:
内存总消耗 :
( (UFFS_MAX_PAGE_SIZE/ 256* 8)*MAX_SPARE_BUFFERS )+
( (sizeof(uffs_Buf) + NAND_PAGE_DATA_SIZE) *MAX_PAGE_BUFFERS )+
( (sizeof(uffs_BlockInfo) + sizeof(uffs_PageSpare) * NAND_PAGES_PER_BLOCK ) *MAX_CACHED_BLOCK_INFO;)+
( size * num)
解释
((页大小/265*8)*页备份区缓存数量)+
((页备份区大小+页数据区大小)*页缓存数量)+
((24 + 16*每块多少页)* 块的信息高速缓存)+
(16*块总数)
其中:
页大小,块总数需要根据具体芯片确定。
MAX_PAGE_BUFFERS ,MAX_CACHED_BLOCK_INFO 这两个宏为UFFS的配置信息,同时这两个值越大,消耗的内存越多,UFFS的性能也会越好。 UFFS文件系统对硬件存储器的使用及其数据结构
通过深入理解文件系统对其进行优化。
MAX_PAGE_BUFFERS ,MAX_CACHED_BLOCK_INFO 这两个宏为UFFS的配置信息,同时这两个值越大,消耗的内存越多,UFFS的性能也会越好。
UFFS建立关系树
uffs_BuildTree函数:
URET uffs_BuildTree(uffs_Device *dev)
{
URET ret;
/***** step one: scan all page spares, classify DIR/FILE/DATA nodes,
check bad blocks/uncompleted(conflicted) blocks as well *****/
/* if the disk is big and full filled of data this step could be
the most time consuming .... */
ret = _BuildTreeStepOne(dev);
if (ret != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "build tree step one fail!");
return ret;
}
/* process pending bad blocks/uncompleted blocks */
if (HAVE_BADBLOCK(dev))
uffs_BadBlockRecover(dev);
/***** step two: randomize the erased blocks, for ware-leveling purpose *****/
/* this step is very fast :) */
ret = _BuildTreeStepTwo(dev);
if (ret != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "build tree step two fail!");
return ret;
}
/***** step three: check DATA nodes, find orphan nodes and erase them *****/
/* if there are a lot of files and disk is fully filled, this step
could be very time consuming ... */
ret = _BuildTreeStepThree(dev);
if (ret != U_SUCC) {
uffs_Perror(UFFS_MSG_SERIOUS, "build tree step three fail!");
return ret;
}
/* process pending bad block */
if (HAVE_BADBLOCK(dev))
uffs_BadBlockRecover(dev);
return U_SUCC;
}代码注释讲的很详细:3个步骤。
第一步:
遍历所有叶的存储空间,将DIR/FILE/DATA这三种节点分类,检查坏块,冲突块。如果磁盘是大的,并且充满了数据,这一步可能是最耗时的。(本人测试过,真的很慢)
注:“DIR/FILE/DATA”就是前文提及到的 :
dir_entry : 文件夹链表
file_entry :文件链表
data_entry :数据链表
在程序中定义的具体结构可以看一下:
struct uffs_TreeSt {
TreeNode *erased; //!< erased block list head
TreeNode *erased_tail; //!< erased block list tail
int erased_count; //!< erased block counter
TreeNode *suspend; //!< suspended block list, this is just a staging zone
// that prevent the serial number of the block be re-used.
TreeNode *bad; //!< bad block list
int bad_count; //!< bad block counter
u16 dir_entry[DIR_NODE_ENTRY_LEN];// dir_entry : 文件夹链表
u16 file_entry[FILE_NODE_ENTRY_LEN];// file_entry :文件链表
u16 data_entry[DATA_NODE_ENTRY_LEN];//data_entry :数据链表
u16 max_serial;
};第二步:
随机擦除块,这一步是非常快的
步骤三:检查数据节点,找到孤儿节点和删除它们,如果有大量的文件并且磁盘被完全填充,这一步可能是非常耗时的
UFFS文件操作过程
dfs_uffs_open 函数主要操作:
dfs_uffs_open
{
{
uffs_mkdir//没有则创建该文件
Else
uffs_open//打开
Elseuffs_opendir
} -> uffs_OpenObject
…
}
uffs_OpenObject
{
uffs_OpenObjectEx
{
uffs_TreeFindDirNodeByName// 打开目录
操作的是 dir_entry
uffs_TreeFindFileNodeByName//打开文件
操作的是 file_entry
}
}当调用UFFS系统打开一个文件的时候。无论是打开文件,还是文件夹,都会触发底层对Nand备份区的读取ReadPageSpare(),直到找到该数据节点,或者穷尽有效叶但为找到该节点(Nand中没有此文件)。
让我们看一下函数的调用过程:
//这里层次真的好深,代码较多,不方便全给出来,读者可以根据这个路线自己在源代码中看,扩展出来
uffs_BufGetEx
{
uffs_FindPageInBlockWithPageId
{
uffs_FindPageInBlockWithPageId
{
For(page_id ~pages_per_block )
{
uffs_BlockInfoLoad
{
For( 0 ~ pages_per_block )
{
uffs_FlashReadPageTag
{
ReadPageSpare//nandflash的驱动接口函数
}
}
}
}
}
}
}(验证与部分猜想下结论)
UFFS初始化时 会扫描所有的块。区分每一块节点(node)信息。
有3类,dir ,file ,data ;
分别存在 dev->tree 下的 dir_entry file_entry data_entry (即为三个 哈希列表)。
也就是说 这3个数组指针,会记录着所有有数据的块信息。UFFS文件系统中,所有的文件操作,访问读写等,在内存中都是3个哈希列表相互配合使用的过程。
注:哈希表的查询精度只到块。
每一个 文件,或者文件夹,都至少占有一个块(130172),
当是文件夹时,这个块中至少有一页存储有效数据,即为当前文件夹目录下的文件与文件夹数据,而其他页为被使用,当修改当前目录时,则可以用其他未被使用的页替换该页(写平衡机制)。当是文件时,这块同样如此,也可存储不满其他页用于写平衡,也可以被写满,这时该块的每个页都存有 有效数据。
当查找一个文件夹时,会穷尽dir_entry 哈希表,根据sum parent 和对比存在nand下的文件名(对比文件名字会实际访问nand (在一个块中寻找有效页,会调用很多次 nandspareread,但不会超过64次(测试时总块就64),最终确定有效页,调用nandread)),来找到哈希表中合适的节点。 则该节点就是要找的nand块,也就是要打开的文件夹。
结论是数据依据:
当nandflash中 有38个文件夹, 一个文件时 test2.bat 2048时。
dir_entry下有38个节点,
File_entry下有1个节点,
Data_entry下无有效节点。
修改test2.bat 10240文件大小,增大 也没有改变。
当创建test3.bat 文件长度为 64*2K*5时,data_entry下有5个节点,File节点有2个。证明之前的猜想 :)
data_entry记录着 一个文件超出一个块的存储时需要用到的文件链表数据。
当访问数据,跨过页的时候,会访问data_entry,寻找下一个连接页的节点信息。
写不动了,UFFS就到这吧,抛砖引玉。希望有高手指点一二。















 6255
6255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









