







从学习数据库到现在已经有一年的时间了,期间也建过2个数据库。数据库的使用是有所深入了,但建表的时候是不是真的从三范式角度思考了,并且知道这么建的理由。现在开始开发项目,大家一起来分析需求,当讨论到这些数据应该怎样建表的时候,大家的“感觉”所占比重很大。这样开发也没什么大问题,但系统健壮吗?
一、意义
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且可能存储了大量不需要的冗余信息。
二、实战
以机房收费系统某些字段为例说一下三范式
1、第一范式1NF(保持数据原子性)
定义:数据库表中的字段都是单一属性的,不可再分。
简单的说,每个字段能分就分,分到不能分为止!
例1:
我们先来看一张不符合1NF的表1-1
| cardID | department | cash |
| 1 | 文学院,新闻系,1班 | 100 |
之所以说这张表不符合1NF,是因为department和Time字段可以再分,所以应该更改为表1-2:
| cardNo | academy | major | class | cash |
| 001 | 文学院 | 新闻系 | 1 | 100 |
例2:
原表1
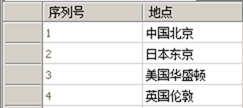
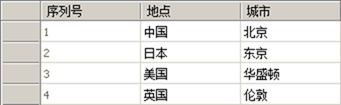
上表中“地点”字段中的值就不符合第一范式。正确的做法应该是把大地点和小地点分开,保持每列的原子性,即不可分割性,如下表:
修改后的表
1NF是关系模式应具备的最起码的条件,如果数据库设计不能满足第一范式,就不称为关系型数据库。也就是说,只要是关系型数据库,就一定满足第一范式。
2、第二范式2NF(消除部分依赖)
定义:在满足第一范式的基础上,数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖于任意一组候选关键字。(另外,所有单关键字的数据库表都符合第二范式,因为不可能存在组合关键字。)
也就是说:
1、 尽可能的使用单关键字
2、 每个表只表述一个事
我们再来看上面的满足1NF的表1-2
| cardID | studentID | studentName | sex | academy | major | class | cash | date | time | userID | level |
| 1 | 1 | 小明 | 男 | 文学院 | 新闻系 | 1 | 100 | 2013/10/03 | 11:00 | 1 | 管理员 |
我们看到,在这张表中,通过cardID和studentNo就可以确定studentName,sex,academy,major,class,cash,date,time。所以可以把cardID和studentNo的组合作为主键。但表中"cash"完全依赖“cardNo”,而“姓名”和“年龄”完全依赖“学号”。也就是说在这一张表里描述了两个事情:学生信息、信息。
卡表:
| cardNo | cash | date | time | userID | level |
| 1 | 100 | 2013/10/03 | 11:00 | 1 | 管理员 |
学生表:
| studentID | cardNo | studentName | sex | academy | major | class |
| 1 | 1 | 小明 | 男 | 文学院 | 新闻系 | 1 |
3、第三范式3NF(消除传递依赖)
定义:在第二范式的基础上,数据表中如果不存在非关键字段对任一候选关键字段的传递函数依赖则符合3NF。
传递依赖:A依赖于B,B依赖于C,就可以说A依赖C。例如:
| cardNo | cash | date | time | userID | level |
| 1 | 100 | 2013/10/03 | 11:00 | 1 | 管理员 |
在表中,一个UserID能确定一个Level。这样,UserID依赖于CardNo,而Level又依赖于UserID,这就导致了传递依赖,3NF就是消除这种依赖。
优化得到:
卡表:
| cardNo | cash | date | time |
| 1 | 100 | 2013/10/03 | 11:00 |
用户表:
| UserID | UserLevel |
| Operator | 操作员 |
我们看到,第三范式规则查找以消除没有直接依赖于第一范式和第二范式形成的表的主键的属性。我们需要建立用户表只是保存用户的信息。
三、总结
通过运用三个范式可以使你的数据库更加准确、高效,下篇博客“浅入浅出三范式的依赖”来描述范式的依赖。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









