







——Java培训、Android培训、iOS培训、.Net培训、期待与您交流! ——-
集合类
为什么出现集合类?
面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,Java就提供了集合类。
之前我们存储大量对象的引用,使用数组;
对象数组的弊端:
1.对于数组,定义时,经常要使用”长度”信息。而大部分时候,我们不会先期的知道具体数量;
2.当数组一旦初始化后,其长度是不可变的;Java中的数组,其长度是不可变的;
所以,对于使用数组存储大量对象,不是一个很方便的工具;
所以,编程语言又为我们准备了一种强大的”容器”,叫:集合
数组和集合类同是容器,有何不同?
对象数组内存图解:
集合类的特点
集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象。
“连接池(Connection接口)”这一概念就是数据库服务器的一个开放连接集。
集可以是有限的,也可以是无限的。
“集合框架”由一组用来操作对象的接口组成。
在“集合框架”中,接口Map和Collection在层次结构没有任何亲缘关系,它们是截然不同的(Map的典型应用是访问按关键字存储的值。它支持一系列集合操作的全部,但操作的是键-值对,而不是单个独立的元素)。返回Map对象的Set视图的方法:
Setset = aMap.keySet();
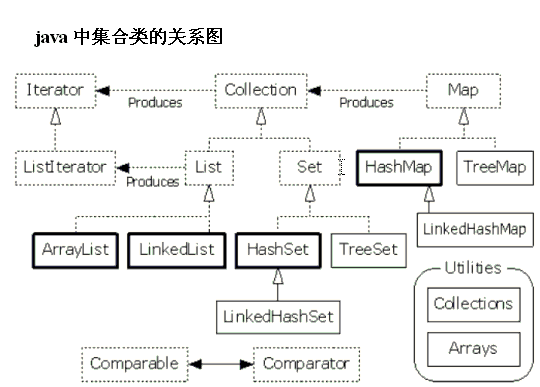
“集合框架”四个基本接口的层次结构:
Collection接口是一组允许重复的对象。
Set接口继承Collection,但不允许重复。
List接口继承Collection,允许重复,并引入位置下标。
Map接口既不继承Set也不继承Collection。
集合的继承体系图解:
Collection接口
Collection接口概述
Collection 层次结构中的根接口。Collection 表示一组对象,这些对象也称为 collection 的元素。一些 collection 允许有重复的元素,而另一些则不允许。一些 collection 是有序的,而另一些则是无序的。
Collection的基本方法
一些简单方法:
一.添加元素:(注:一些方法的形参和返回值,如果是E,大家把它先理解为Object)
boolean add(E e):向集合中添加一个元素。如果此 collection 由于调用而发生更改,则返回 true。
二.删除元素:
boolean remove(Object o):从此 collection 中移除指定元素的单个实例,如果存在的话(可选操作)。
更确切地讲,如果此 collection 包含一个或多个满足 (o==null ? e==null : o.equals(e)) 的元素 e,则移除这样的元素。
如果此 collection 包含指定的元素(或者此 collection 由于调用而发生更改),则返回 true 。
void clear():清空集合
三.判断:
boolean contains(Object o):如果此 collection 包含指定的元素,则返回 true。
更确切地讲,当且仅当此 collection 至少包含一个满足 (o==null ? e==null : o.equals(e)) 的元素 e 时,返回 true。
boolean isEmpty():判断集合是否为空;
四.获取:
int size():返回集合内元素的数量;
Collection中一些对批量元素进行操作的方法:
boolean addAll(Collection c):将参数集合中的内容,全部添加到当前集合中。
boolean removeAll(Collection c):移除此 collection 中那些也包含在指定 collection 中的所有元素(可选操作)。此调用返回后,collection 中将不包含任何与指定 collection 相同的元素。
boolean containsAll(Collection c):如果此 collection 包含指定 collection 中的”所有元素”,则返回 true。
boolean retainAll(Collection c):移除此 collection 中未包含在指定 collection 中的所有元素。
Collection中用于遍历元素的方法:
Object[] toArray():
把集合转成数组,可以实现集合的遍历
Iterator iterator():
迭代器,集合的专用遍历方式
java.util.Iterator(接口):
boolean hasNext() :如果仍有元素可以迭代,则返回 true。
Object next():返回迭代的下一个元素。
void remove() : 从迭代器指向的 collection 中移除迭代器返回的最后一个元素(可选操作)。
Iterator的原理:
interface Iterator{
boolean hasNext();
Object next();
void remove();
}
interface Collection{
Iterator iterator();
}
class ArrayList implements Collection{
//重写父类方法
//父类,定义了一个规则:子类必须要有一个迭代器,用于遍历元素;
public Iterator iterator(){
return new Itr();
}
private class Itr implements Iterator{
boolean hasNext(){//实现}
Object next(){//实现}
void remove(){//实现}
}
}
class LinkedList implements Collection{
public Iterator iterator(){
return new Itr();
}
private class Itr implements Iterator{
boolean hasNext(){//实现}
Object next(){//实现}
void remove(){//实现}
}
}
迭代器使用图解和原理解析:

迭代器遍历数组:

List接口
List接口概述
有序的 collection(也称为序列)。此接口的用户可以对列表中每个元素的插入位置进行精确地控制。用户可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。
与 set 不同,列表通常允许重复的元素。
List的子类特点
ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
List有三个儿子,我们到底使用谁呢?
看需求(情况)。
要安全吗?
要:Vector(即使要安全,也不用这个了,后面有替代的)
不要:ArrayList或者LinkedList
查询多:ArrayList
增删多:LinkedList
数组和链表:
List的常用方法:有序的(取出时,跟存入的顺序相同)。
* 允许重复元素;
* 以下方法是List接口增加的一些方法:
* void add(int index,Object element):向index的位置,插入一个对象element;index >= 0 && index <= size()
* Object remove(int index):移除index位置上的元素。返回值为删除的对象;
* Object get(int index):获取index位置上的元素;
* Object set(int index,Object element):使用element替换原index位置上的元素;
* ListIterator listIterator():ListIterator继承自Iterator,增加了向上遍历的功能。
List存储自定义对象:
ListIterator的并发修改异常:
* ListIterator的并发修改异常:
* 当我们通过”迭代器”遍历元素时,通过list去修改成员,这时会导致list中的内容与”迭代器”中的内容不符,所以,就会产生并发修改异常:java.util.ConcurrentModificationException
*
* 所以这里注意:
* 1.当我们使用迭代器遍历时,如果想同时添加数据,那么就用迭代器的add方法添加;
* 2.如果使用list遍历,那么就用list的add方法添加;
ArrayList类
ArrayList类概述
底层数据结构是数组,查询快,增删慢
线程不安全,效率高
ArrayList案例
存储字符串并遍历
public class Demo {
public static void main(String[] args) {
MyArrayList list = new MyArrayList();
list.add(“aaa”);
list.add(“bbb”);
list.add(“ccc”);
for(int i = 0;i < 10000000 ; i++){
list.add(String.valueOf(i));
}
System.out.println(“我的集合的size() = ” + list.size());
}
}
Vector类
Vector类概述
底层数据结构是数组,查询快,增删慢
线程安全,效率低
LinkedList类
LinkedList类概述
底层数据结构是链表,查询慢,增删快
线程不安全,效率高
自己实现的链表结构
public class Demo {
public static void main(String[] args) {
MyLinkedList list = new MyLinkedList();
list.add(“aaa”);
list.add(“bbb”);
list.add(“ccc”);
list.insert(0, "xxx");
list.printAll();
}
}
LinkedList类特有功能
public void addFirst(E e)及addLast(E e)
public E getFirst()及getLast()
public E removeFirst()及public E removeLast()















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









