







 本文介绍了GCN网络如何利用大卷积核改善语义分割任务的分类和定位问题。GCN模块通过非对称卷积减少参数量并增大感受野,BR模块则提升边界定位精度。实验结果显示,GCN网络在PASCAL VOC 2012和Cityscapes数据集上达到了SOTA水平。
本文介绍了GCN网络如何利用大卷积核改善语义分割任务的分类和定位问题。GCN模块通过非对称卷积减少参数量并增大感受野,BR模块则提升边界定位精度。实验结果显示,GCN网络在PASCAL VOC 2012和Cityscapes数据集上达到了SOTA水平。
文章目录
1 摘要
文章指出,最近流行的一个趋势就是使用小的过滤器进行堆叠(如:1x1,3x3等),这样能够在同样的计算量情况下比大的过滤器更有效率。然而,作者发现,大的过滤器其实在语义分割的分类和定位问题上扮演着重要的角色,作者基于大过滤器提出Global Convolutional Network(GCN),能同时解决语义分割中的分类和定位这两个问题。该网络在PASCAL VOC 2012和Cityscapes数据集中均达到SOTA。
2 存在问题
语义分割中分类和定位是两个矛盾的问题:
① 对于分类问题,它本身不关注图像的细节、纹理等信息,更多地关心目标的显著的特征,依靠这些显著的特征来判断这是什么类,所以在VGG16、AlexNet中都会使用卷积+池化层,使用池化层在减少参数的同时可以获得更大的感受野去感知这个目标,最后得到一个很小的特征图(里面都是决定一个物体类别的特征),依靠这些特征即可对图像完成分类。如下图:
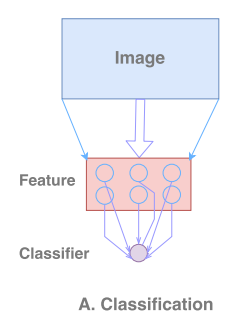
上图也是说明了,分类任务,Image先缩小得到特征,再对像素进行分类。
② 对于定位问题,由于进行的是语义分割任务,语义分割任务有一个很重要的步骤就是需要将小小的特征图恢复成原图大小,完成目标边界的划分与定位。而池化层是对定位的精度有着很大伤害的一种方法,它会把图像的细节信息过滤掉,所以在FCN、UNet等网络都会通过把浅层的图像再利用起来叠加或者拼接到上采样之后的图像。下图则展现了定位问题的过程:
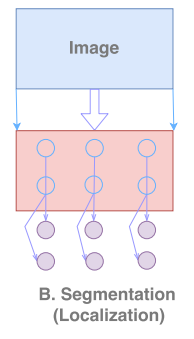
上图中,定位问题是希望直接是Image大小的图像,直接对这里面的像素进行定位(位置与原图一一对应)。
由
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









