






欢迎关注“
计算机视觉研究院
”

计算机视觉研究院专栏
作者:Edison_G
CVPR2021已经很多好的paper被公布,比如腾讯的20篇好文,后期我们也会详细给大家分析,如果有机会还会分享代码的整体运行讲解。
今天我们要说的也是CVPR2021的一个优秀paper,华为技术产出的,其主要利用加法神经网络(AdderNet)-加法网络用于检测,研究了单幅图像超分辨率问题。 与卷积神经网络相比,AdderNet利用加法计算输出特征,避免了传统乘法的大量能量消耗。

长按扫描二维码关注我们
回复“华为CVPR2021”获取论文
及Github代码
我们创办了“计算机视觉研究院”微信学习群,有兴趣的同学可以加入我们一起来学习,探讨问题、解决问题,共同进步!

1、前言摘要
然而,由于计算范式的不同,很难将AdderNet在大规模图像分类上的现有成功直接继承到图像超分辨率任务中。具体来说,加法器操作不容易学习标识映射,这对于图像处理任务是必不可少的。此外,AdderNet无法保证高通滤波器的功能。
为此,研究员深入分析了加法器操作与标识映射之间的关系,并插入快捷方式,以提高使用加法器网络的SR模型的性能。然后,研究员开发了一个可学习的power activation,以调整特征分布和细化细节。在几个基准模型和数据集上进行的实验表明,使用加法网络的图像超分辨率模型可以实现与其CNN基线相当的性能和视觉质量,并使能耗降低约2×。

2、相关领域及回顾
AdderNet
加法网络,“计算机视觉研究院”平台之前就详细分析了,并且移植到目标检测,具体链接如下:
CVPR2020最佳目标检测 | AdderNet(加法网络)含论文及源码链接
代码实践 | CVPR2020——AdderNet(加法网络)迁移到检测网络(代码分享)
现有的有效超分辨率方法旨在减少模型的参数或计算量。最近,[Hanting Chen, Yunhe Wang, Chunjing Xu, Boxin Shi, Chao Xu, Qi Tian, and Chang Xu. Addernet: Do we really need multiplications in deep learning? In CVPR, 2020]开创了一种新的方法,通过用加法运算代替乘法来减少网络的功耗。它在卷积层中没有任何乘法,在分类任务上实现了边际精度损失。本此研究旨在提高加法网络在超分辨率任务中的性能。
Preliminaries and Motivation
在这里,我们首先简要介绍了使用深度学习方法的单个图像超分辨率任务,然后讨论了直接使用AdderNet构建节能SR模型的困难。现有的超分辨率方法大致可分为三类:interpolation based methods,dictionary-based methods和deep learning based methods。在过去的十年里,由于其显著的表现,注意力已经转移到深度学习方法上。[Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Learning a deep convolutional network for image super-resolution. In ECCV, pages 184–199, 2014]首先引入了深度学习方法来实现超分辨率,并取得了比传统方法更好的性能。conventional SISR任务的总体目标函数可以表述为:
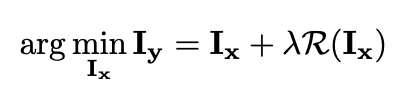
尽管下面公式显示了类似的性能,在上面公式定义了SISR问题。与传统的识别任务有很大的不同。例如,我们需要确保输出结果保持X(即Iy)中的原始纹理,这是下面公式不容易学习的。因此,我们应该设计一个新的AdderNet框架来构建节能SISR模型。
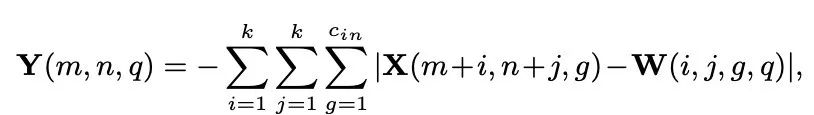
3、AdderNet for Image Super-Resolution
Learning Identity Mapping using AdderNet

然后选择每个元素的合适值:

Learnable Power Activation
除了标识映射外,传统卷积滤波器还有另一个重要的功能,不能很容易地通过加法滤波器来保证。SISR模型的目标是增强输入低分辨率图像的细节,包括颜色和纹理信息。因此,在现有的SISR模型中,高通滤波器也是一个非常重要的组成部分。可以在下图中找到,当网络深度增加时,输入图像的细节逐渐增强。


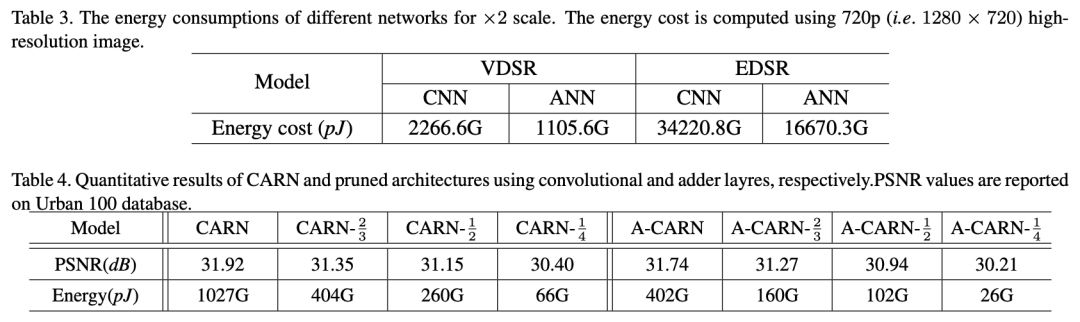
4、实验

一种具有不同策略的AdderSR网络中加法层的输出特征图
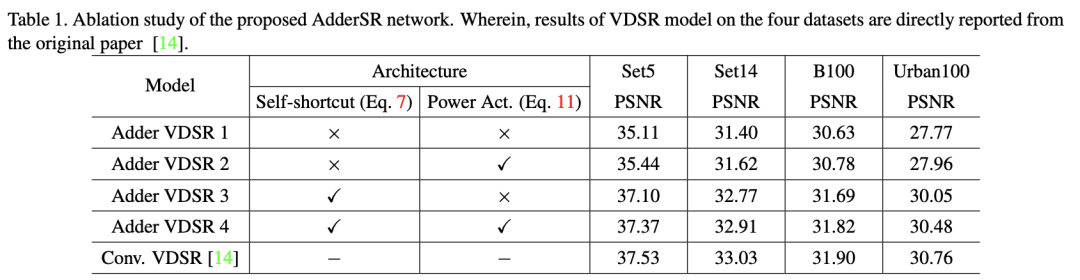
[14]:Jiwon Kim, Jung Kwon Lee, and Kyoung Mu Lee. Accurate image super-resolution using very deep convolutional networks. In CVPR, pages 1646–1654, 2016.
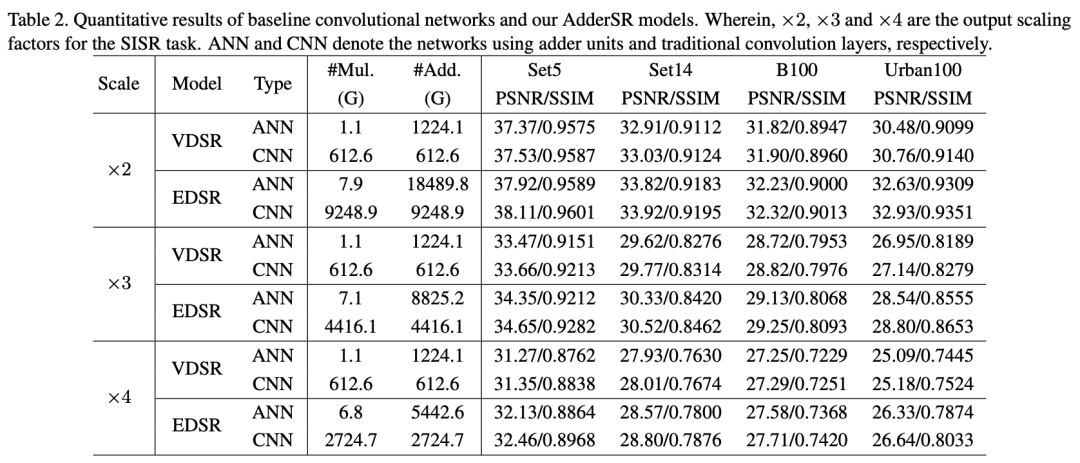

AdderSR Network and CNN on ×3 scale超分辨率图像可视化
© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
🔗



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











