






点击蓝字
关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式

论文标题:GLEE: General Object Foundation Model for Images and Videos at Scale
论文地址:https://arxiv.org/abs/2312.09158
代码地址:https://github.com/FoundationVision/GLEE
Demo 地址:https://huggingface.co/spaces/Junfeng5/GLEE_demo
视频地址:https://www.bilibili.com/video/BV16w4m1R7ne/
计算机视觉研究院专栏
Column of Computer Vision Institute
近年来,LLM 已经一统所有文本任务,展现了基础模型的强大潜力。一些视觉基础模型如 CLIP 在多模态理解任务上同样展现出了强大的泛化能力,其统一的视觉语言空间带动了一系列多模态理解、生成、开放词表等任务的发展。然而针对更细粒度的目标级别的感知任务,目前依然缺乏一个强大的基础模型。

为了解决这个问题,来自华中科技大学和字节跳动的研究团队提出了一个针对视觉目标的基础模型 GLEE,一次性解决图像和视频中的几乎所有目标感知任务。GLEE 支持根据任意开放词表、目标的外观位置描述、和多种交互方式进行目标检测、分割、跟踪,并在实现全能性的同时保持 SOTA 性能。
此外,GLEE 还构建了统一优化目标的训练框架,从超过一千万的多源数据中汲取知识,实现对新数据和任务的零样本迁移。并验证了多种数据之间相互促进的能力。模型和训练代码已全部开源。
1. GLEE 可以解决哪些任务?
GLEE 可以同时接受语义和视觉上的 prompt 作为输入,因此,任意长度的开放词表、目标属性描述、目标位置描述都、交互式的 point,box,mask 都可以被作为 prompt 来指引 GLEE 检测分割出任意目标。具体来说,开放世界的目标检测、实例分割、文本描述的指代检测与分割(referring expression comprehension and segmentation)以及交互式分割都可以被轻松实现。
此外,通过在超大规模的图像数据上进行训练,GLEE 学习到了更加有判别性的目标特征,直接对这些特征进行无参数的帧间匹配可以实现高质量的跟踪,从而将 GLEE 的能力完全扩展到视频任务上。在视频任务中 GLEE 可以实现开放世界的视频实例分割(VIS),视频目标分割(VOS),参考视频实例分割(RVOS)以及交互式的视频目标分割跟踪。
2. GLEE 统一了哪些数据用来训练?
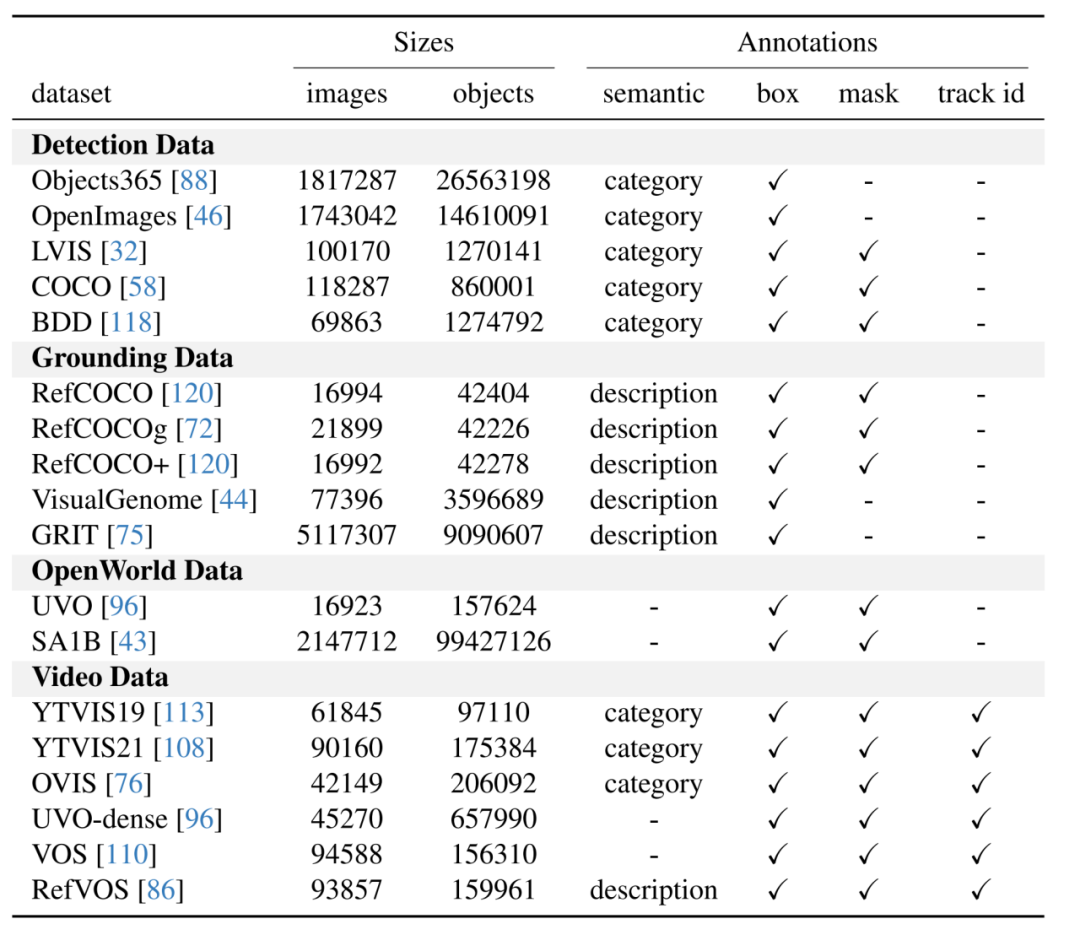
GLEE 使用了来自 16 个数据集的超过一千万图片数据进行训练,充分利用了现有的标注数据和低成本的自动标注数据构建了多样化的训练集,是 GLEE 获得强大泛化性的根本原因。
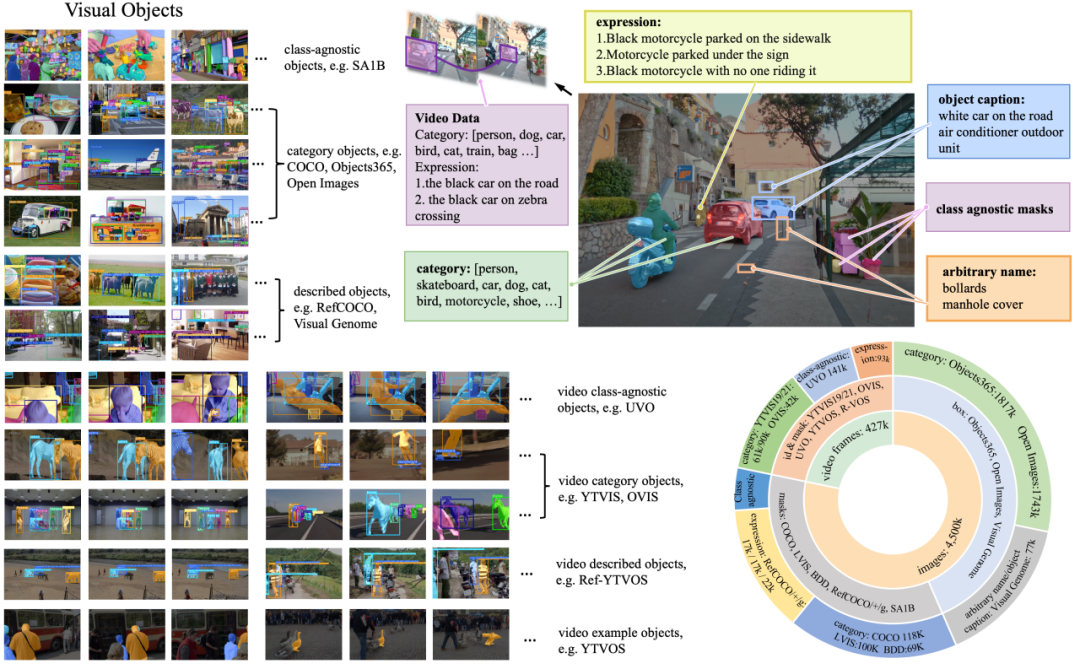
GLEE 使用的数据根据标注类型可以分为四大类:1)基于词表的目标检测数据集,如 COCO、Objects365。2)基于目标描述的 grounding 数据集,如 RefCOCO 系列、VisualGenome。3)无类语义信息的 open-world 数据集,如 SA1B、UVO。4)视频数据,如 YouTubeVIS、OVIS。GLEE 所使用的图片超过 1 千万,其中标注目标数量超过一亿五千万。
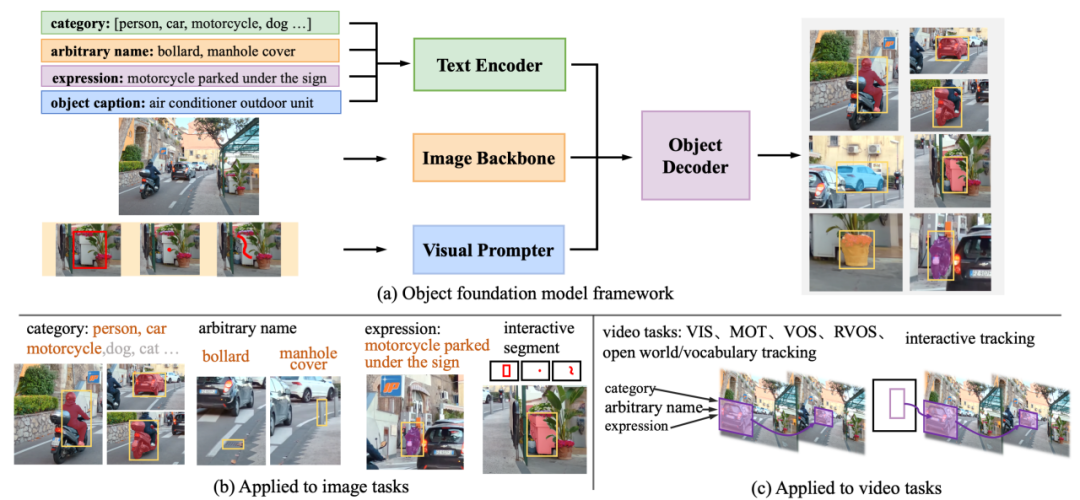
3. GLEE 如何构成?
GLEE 包括图像编码器、文本编码器、视觉提示器和目标检测器,如图所示。文本编码器处理与任务相关的任意描述,包括目标类别词表、目标任何形式的名称、关于目标的标题和指代表达。视觉提示器将用户输入(如交互式分割中的点、边界框或涂鸦)编码成目标对象的相应视觉表示。然后,这些信息被整合到一个检测器中,根据文本和视觉输入从图像中提取对象。
4. 在目标感知任务上的全能性和泛化能力
该研究展示了 GLEE 模型作为一个目标感知基础模型的普适性和有效性,它可以直接应用于各种以目标为中心的任务,同时确保最先进的性能,无需进行微调。
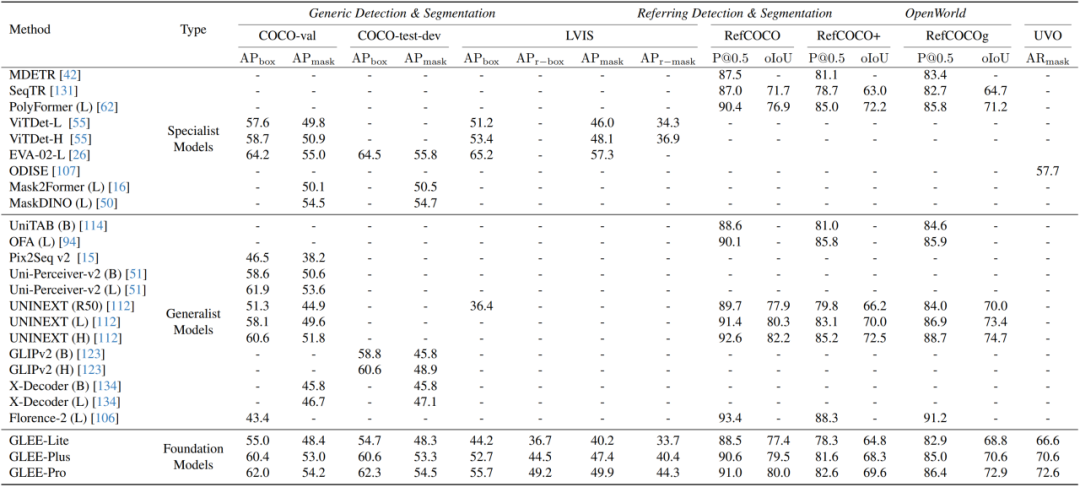
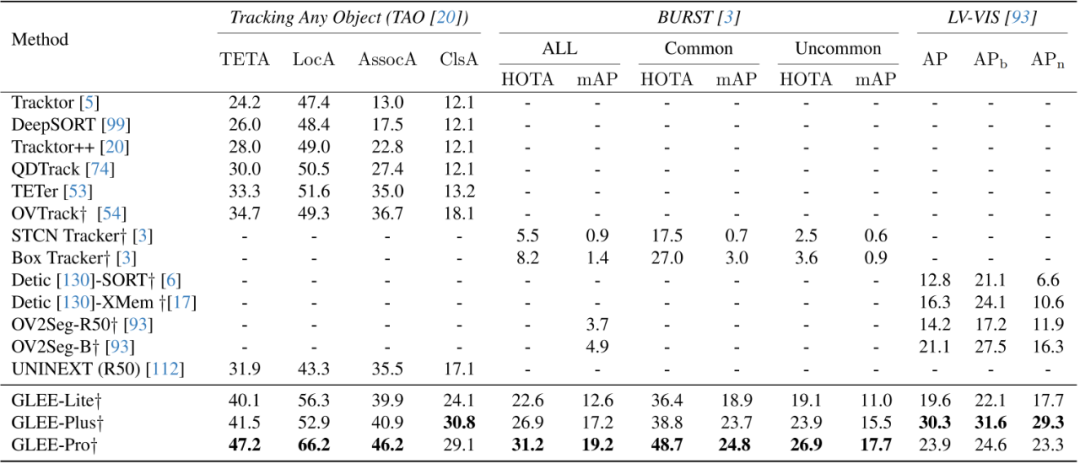
此外,该研究在一些开放词汇表的视频任务中验证了 GLEE 的零样本泛化能力。在 TAO、BURST、LV-VIS 这三个开放词汇表的跟踪数据集上,GLEE 在未经过训练和微调的情况下,取得了令人惊叹的最先进(SOTA)性能,这证明了 GLEE 在大规模联合训练中学习到的通用对象感知能力和强大的泛化能力。
5. 作为基础模型的潜力
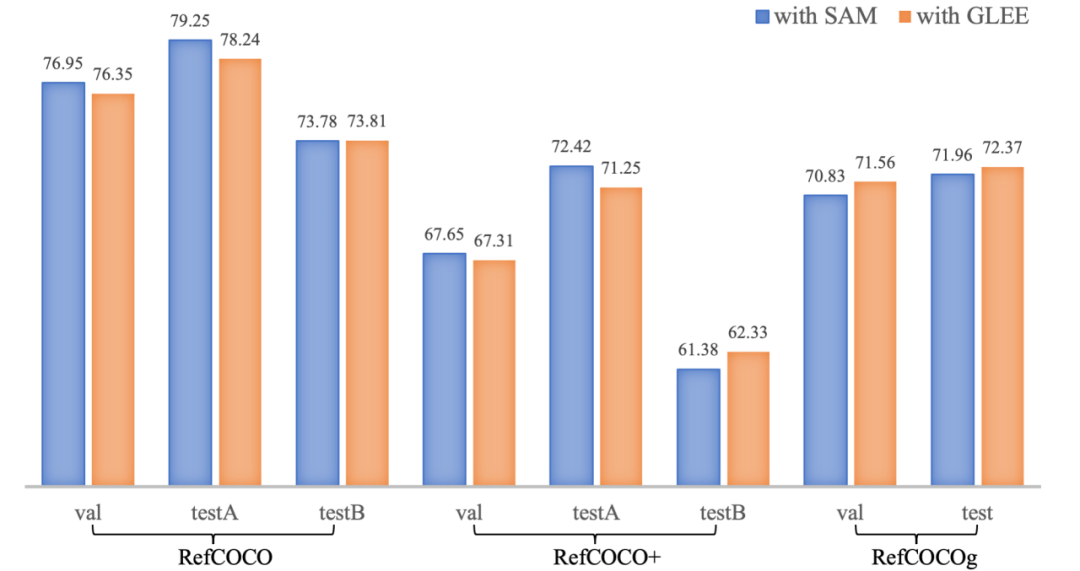
作为基础模型,该研究用预训练且冻结的 GLEE-Plus 替换了 LISA 的中使用的 SAM backbone,并将 GLEE 的 Object Query 输入到 LLAVA 中,移除了 LISA 的解码器。该研究直接将输出的 SEG 标记与 GLEE 特征图进行点积运算以生成 Mask。在进行相同步数的训练后,修改后的 LISA-GLEE 取得了与原版 LISA 使用 SAM 相媲美的结果,这证明了 GLEE 的表示具有多功能性,并且在为其他模型服务时的有效性。

END


转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
🔗















 1453
1453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









