






点击蓝字 关注我们
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|计算机视觉研究院
学习群|扫码在主页获取加入方式
计算机视觉研究院专栏
Column of Computer Vision Institute
道路建设中使用的材料质量欠佳,检测并避开道路坑洼是一项颇具挑战性的任务。尽快识别并修复坑洼对于预防事故至关重要。路边的坑洼会引发严重的交通安全问题,还会损坏汽车。

01
简介
本次介绍一种新颖的基于YOLOv8的坑洼检测方法(POT-YOLO),用于检测诸如裂缝、油渍、补丁、碎石等不同类型的坑洼。首先,将坑洼视频转换为图像帧以便进一步处理。为减少图像失真,这些图像帧会使用对比度拉伸自适应高斯星型滤波器(CAGF)进行预处理。最后,经过预处理的图像利用索贝尔(Sobal)边缘检测器识别坑洼区域,并使用YOLOv8检测坑洼。POT - YOLO方法通过Python代码进行模拟。模拟结果表明,POT-YOLO方法的性能通过准确率(ACU)、精确率(PRE)、召回率(RCL)和F1分数(F1S)来衡量。POT - YOLO的总体准确率达到99.10%。此外,POT-YOLO模型的精确率达到97.6%,召回率达到93.52%,F1分数达到90.2%。相比之下,POT - YOLOv8网络在准确率方面比现有的诸如Faster RCNN、SSD和Mask R CNN等网络表现更优。与基于机器学习的DeepBus、基于深度神经网络(DNN)的自动图像分析以及ODRNN相比,POT-YOLO方法的总体准确率分别提高了12.3%、0.97%和1.4%。

02
背景及动机
道路在现代基础设施中起着至关重要的作用,它促进了全球范围内的交通运输和互联互通。长期以来,国家对汽车的依赖程度很高,截至目前,该国已注册车辆超过2.95亿辆,且这一数字还在迅速增长。

道路上的坑洼可能会危及道路使用者的生命。如果不加以妥善维护,坑洼情况会随着时间的推移而恶化。因此,如果坑洼得不到及时处理,将立即引发多种后果,比如导致摩托车骑手遭遇惨烈的交通事故、车辆悬挂系统严重受损,或者造成不必要的交通拥堵。坑洼不仅会损坏车辆,还会对司机和行人构成威胁。人们已经开发出多种检测坑洼的方法,例如在汽车上安装传感器和专用硬件。遗憾的是,目前需要更经济实惠的解决方案来简化道路结构监测,而这不仅仅局限于坑洼情况。根据其他研究,加速度计检测设置起来很简单,但在路面凸起处经常会出现误检,这可能会影响汽车的悬挂系统。基于图像处理的检测对计算硬件要求较低,且能得出可接受的结果;然而,这些方法容易受到光线变化的影响,而且对于小坑洼和路面基本相同的纹理也很敏感。尽管基于机器学习的检测相比之前的技术有所进步,但创建特征提取器往往需要大量的工作和专业知识,并且其准确性仍有待提高。不过,随着计算机视觉和深度学习算法的发展,自动坑洼检测技术正日益受到欢迎。“你只看一次”(YOLO)方法是用于识别物体(包括坑洼识别应用)最有前景的深度学习技术。YOLO是一种神经网络,它利用目标检测和分类技术在实时视频流中识别物体。由于其在检测物体时具有较高的准确性和速度,它已广受欢迎。然而,此前人们已经探索过多种方法,但它们都存在显著的局限性,比如得出结果的速度较慢,实现过程不够稳定。深度学习网络在所有实时应用中都取得了积极的成果,并且它们有助于预防这类事故。
因此,该项目的重点是利用YOLOv3模型实现实时的道路坑洼检测。通过定期监测,可以让林区道路保持良好状态。2023年,佩拉尔塔-洛佩斯(Peralta-López,J.E.)等人提出了一种利用深度神经网络(DNN)进行自动彩色图像分析的方法,通过ZED相机拍摄的图像来检测道路上的坑洼。这种轻量级架构旨在加快训练和使用速度。通过安装在汽车前部的ZED相机生成了一个数据库。该系统使用数据库中70%的数据进行训练,并用剩余30%的数据进行验证,得出的准确率为98.13%。

03
新方法解析
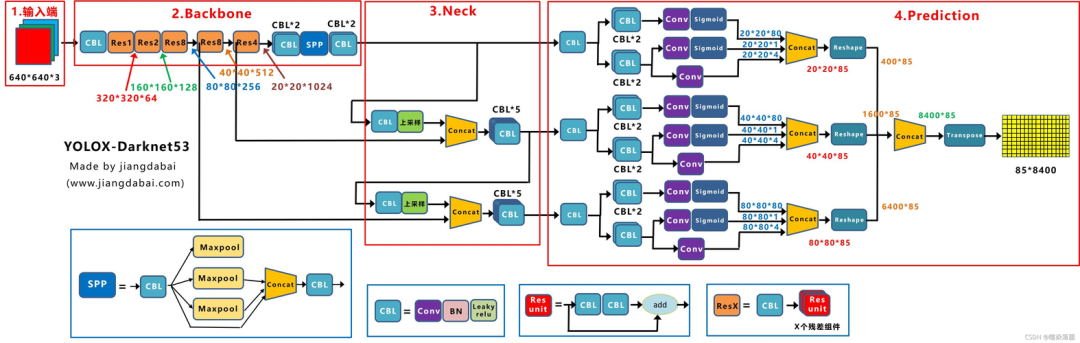
利用POT-Yolov8来识别各种形式的道路坑洼,包括裂缝、油渍、补丁和碎石。首先,从数据集中提取坑洼视频,并将其转换为图像。为减少失真,这些图像帧使用对比度拉伸自适应高斯星型滤波器(CAGF)进行预处理。最后,经过预处理的图像利用POT-YOLOv8来检测和识别坑洼区域。下图展示了POT-YOLO的总体流程。
数据集获取本研究采用了乌玛(Ouma,Y.O.)等人在其研究中获取的数据集。在这些不同的数据集里,包含了各种尺寸和形状的坑洼,还有不同的成像条件,比如噪声、背景特征、光照以及阴影情况,此外还涵盖了路面状况,例如褪色、线性裂缝以及其他路面缺陷。
在所选的测试图像中,均存在坑洼,但所提出的方法仅在单个图像块内识别和提取坑洼,而不是自动在多个路面图像中识别坑洼。测试数据集可能包含诸如坑洼或非坑洼的缺陷。其他特征可能包括光照裂缝、油渍、补丁、碎石、阴影以及其他噪声。
A.通过对比度拉伸自适应高斯星型滤波器(CAGF)进行预处理在将坑洼图像分割成帧后,使用自适应高斯星型滤波对其进行预处理。本节介绍的一种图像增强技术会在子块内局部调整对比度拉伸,以控制强度范围。
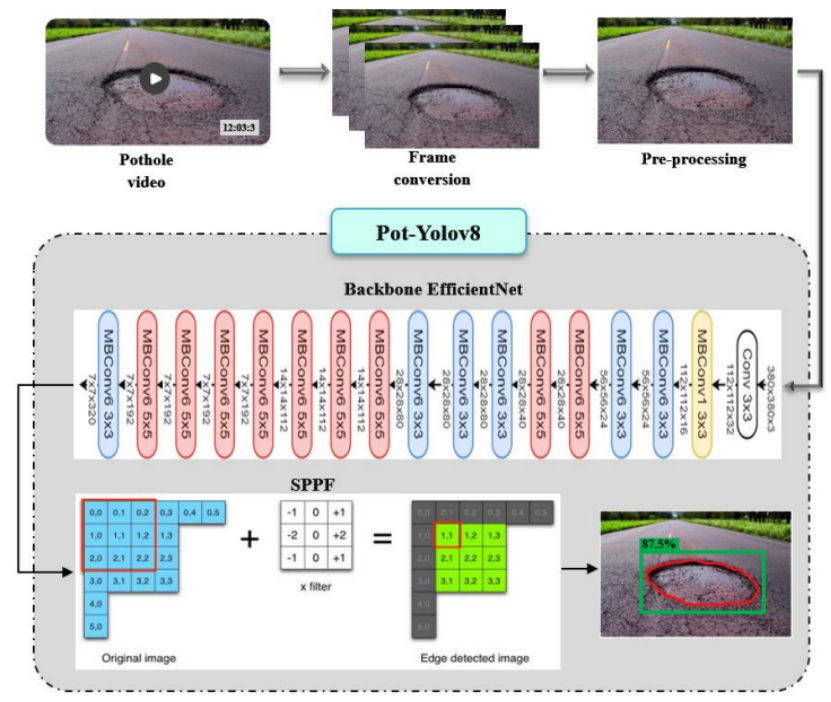
B.利用POT-YOLOv8进行坑洼检测,经过预处理的图像被输入到POT-YOLOv8网络中,以精确检测坑洼中的缺陷类型。POT-YOLOv8在早期YOLO版本成功的基础上进行了改进,融入了新的特性和升级,进一步提升了性能和通用性,从而实现了卓越的性能和完美的效率。POT-YOLOv8有五种不同的尺寸选项:超小(nano)、小(small)、中(medium)、大(big)和超大(extra-large)。POT-YOLOv8分为三个部分:骨干网络(backbone)、颈部(neck)和头部(head),它们分别负责特征提取、多功能融合和预测输出。下图展示了POT-YOLOv8网络的架构。
i.道路坑洼的目标检测
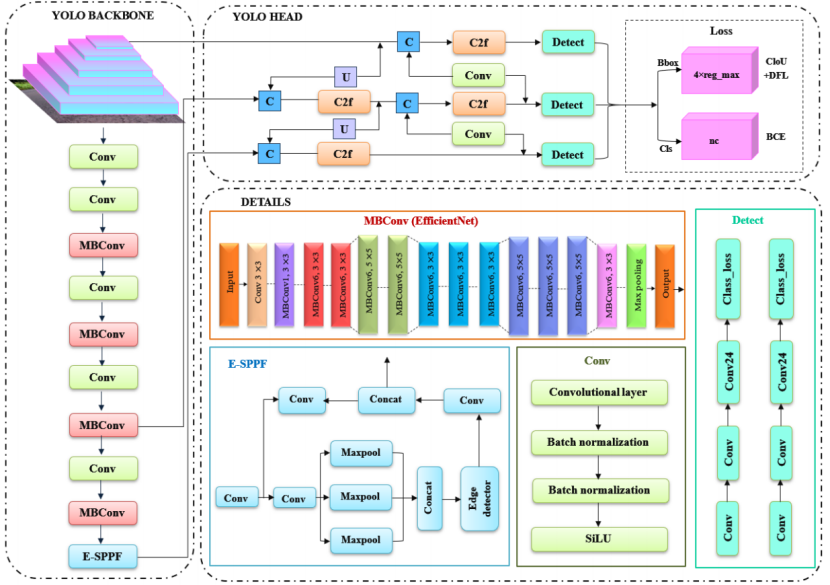
在这个阶段,使用移动倒瓶颈卷积(MBCConv,即高效网络EfficientNet所采用的结构)来检测道路上的坑洼。反向瓶颈结构的MBCConv是构建高效网络EfficientNet的基础。MBCConv模块由先减少通道数再增加通道数的层组成。对于高效网络EfficientNet而言,修正线性单元(ReLU)作为激活函数。在复合缩放(compoundscaling)过程中,会使用复合系数μ,得到的规则如下:
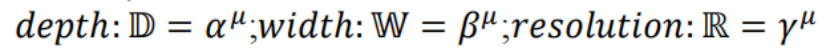
ii.针对道路坑洼的增强型空间金字塔池化快速模块(E-SPPF)
YOLOv8中的E-SPPF模块已被证明在通过多尺度特征融合提升模型性能方面十分有效,尤其是在特定情况下。空间金字塔池化快速模块(SPPF)在复杂背景以及目标尺度变化的情况下可能存在局限性。这是因为它目前缺乏一种聚焦关键区域的精细方法。为了克服SPPF模块的局限性并提升特征提取能力,引入了边缘检测器-空间金字塔池化快速模块(E-SPPF),该模块能够根据每个区域的重要性,以自适应的方式动态调整特征图中的权重。E-SPPF注意力技术在降低计算成本的同时,能够保留来自每个通道的信息。

为了实现这一点,通道维度被重新排列到批量维度中,子特征维度被划分为若干个子特征。这使得空间语义特征在每个特征组内得到了均匀分布。上图展示了所提出的带有E-SPPF模型的边缘检测结果,该模型将E-SPPF注意力机制融入到了这个模块中。E-SPPF模块不仅进行多尺度特征融合,还会精细调整每个尺度的特征,从而能够在多个尺度上有效地捕捉信息。这种调整极大地增强了模型识别坑洼边缘的能力。这种检测形式可以提高检测精度并加速模型收敛。YOLOv8是一种无锚框检测模型,它几乎定义了有效样本和无效样本。它还利用任务对齐分配器(Task-AlignedAssigner)动态分配样本,从而提高了模型的检测精度和适应性。为了有效地识别坑洼,需要调整诸如训练轮数(epoch)和学习率等超参数,以提高检测精度。

04
实验机可视化

上图展示了POT-YOLO方法在检测输入图像中坑洼的仿真结果。第1列包含数据集的输入图像。第2列展示了使用CAGF进行预处理后的图像。第3列展示了使用索贝尔(Sobal)边缘检测器来查找坑洼边缘的结果。最后,第4列使用Pot-Yolov8在经过边缘检测的图像中查找坑洼。
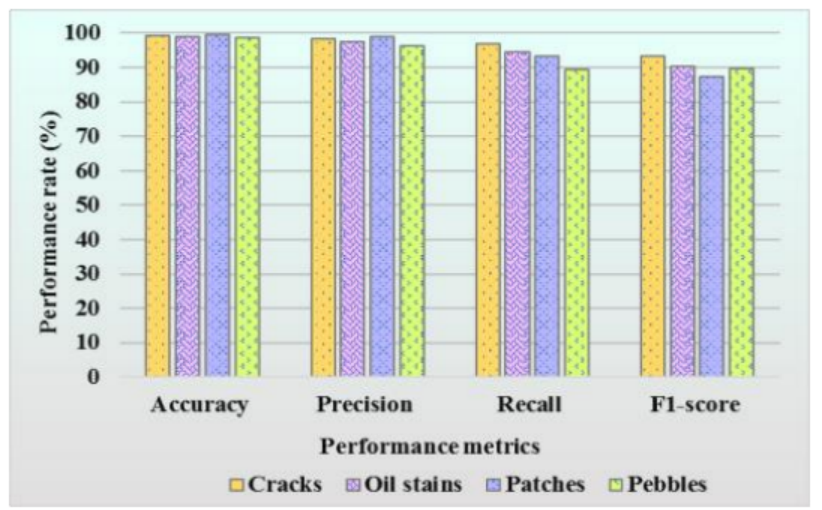
上图5展示了POT-YOLO网络对裂缝、油渍、补丁和碎石这四类(缺陷)的分类有效性\[27,28\]。POT-YOLO的性能通过准确率(ACU)、精确率(PRE)、召回率(RCL)和F1分数(F1S)来衡量。结果显示,POT-YOLO的分类准确率达到99.10%。此外,该模型的精确率达到97.6%,召回率达到93.52%,F1分数达到90.2%。在某些情况下,图像质量的差异和光照条件会影响检测精度。

上图展示了针对道路坑洼的传统目标检测网络的检测对比结果。然而,与POT-YOLOv8相比,传统的目标识别算法表现较差。根据上述比较,POT-YOLOv8优于诸如Yolov3、Yolov5和Yolov6等传统技术。POT-YOLOv8通过达到99.10%的准确率,提高了系统的效率并降低了误报率。因此,POT-YOLOv8能更快地预测出结果,并且在准确率(ACU)方面取得了最佳效果。

转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于目标检测、目标跟踪、图像分割、OCR、模型量化、模型部署等研究方向。研究院每日分享最新的论文算法新框架,提供论文一键下载,并分享实战项目。研究院主要着重”技术研究“和“实践落地”。研究院会针对不同领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

往期推荐
🔗



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











