







代码随想录1刷—动态规划篇(四):编辑距离
- [392. 判断子序列](https://leetcode.cn/problems/is-subsequence/)
- 双指针法
- 动态规划
- [115. 不同的子序列](https://leetcode.cn/problems/distinct-subsequences/)
- [583. 两个字符串的删除操作](https://leetcode.cn/problems/delete-operation-for-two-strings/)
- [72. 编辑距离](https://leetcode.cn/problems/edit-distance/)
- [647. 回文子串](https://leetcode.cn/problems/palindromic-substrings/)
- [516. 最长回文子序列](https://leetcode.cn/problems/longest-palindromic-subsequence/)
392. 判断子序列
双指针法
初始化两个指针 i 和 j,分别指向 s 和 t 的初始位置。每次匹配成功则 i 和 j 同时右移,匹配 s 的下一个位置,匹配失败则 j 右移,i 不变,尝试用 t 的下一个字符匹配 s。最终如果 i 移动到 s 的末尾,就说明 s 是 t 的子序列。
class Solution {
public:
bool isSubsequence(string s, string t) {
int n = s.length(), m = t.length();
int i = 0, j = 0;
while(i < n && j < m){
if(s[i] == t[j]){
i++;
}
j++;
}
return i == n;
}
};
动态规划
编辑距离的入门题目,从题意中可以发现,只需要计算删除的情况,不用考虑增加和替换的情况。
1、 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示以下标 i − 1 i-1 i−1为结尾的字符串 s s s,和以下标 j − 1 j-1 j−1为结尾的字符串 t t t,相同子序列的长度为 d p [ i ] [ j ] dp[i][j] dp[i][j]。
注意这里是判断 s s s是否为 t t t的子序列。即 t t t的长度是大于等于 s s s的。
2、在确定递推公式的时候,首先要考虑如下两种操作:
- i f ( s [ i − 1 ] = = t [ j − 1 ] ) if (s[i - 1] == t[j - 1]) if(s[i−1]==t[j−1]):表示在 t t t中找到了一个字符在 s s s中也出现了
- i f ( s [ i − 1 ] ! = t [ j − 1 ] ) if (s[i - 1] != t[j - 1]) if(s[i−1]!=t[j−1]):相当于 t t t要删除元素,继续匹配
if (s[i - 1] == t[j - 1]),dp[i][j] = dp[i - 1][j - 1] + 1;因为找到了一个相同的字符,相同子序列长度自然要在
d
p
[
i
−
1
]
[
j
−
1
]
dp[i-1][j-1]
dp[i−1][j−1]的基础上加1。
if (s[i - 1] != t[j - 1]),此时相当于
t
t
t要删除元素,
t
t
t如果把当前元素
t
[
j
−
1
]
t[j - 1]
t[j−1]删除,那么
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j] 的数值就是 看
s
[
i
−
1
]
s[i - 1]
s[i−1]与
t
[
j
−
2
]
t[j - 2]
t[j−2]的比较结果了,即:dp[i][j] = dp[i][j - 1];
3、 d p [ i ] [ j ] dp[i][j] dp[i][j]都是依赖于 d p [ i − 1 ] [ j − 1 ] dp[i - 1][j - 1] dp[i−1][j−1] 和 d p [ i ] [ j − 1 ] dp[i][j - 1] dp[i][j−1],所以 d p [ 0 ] [ 0 ] dp[0][0] dp[0][0]和 d p [ i ] [ 0 ] dp[i][0] dp[i][0]是一定要初始化的。
注意:在定义 d p [ i ] [ j ] dp[i][j] dp[i][j]含义的时候为什么要表示以下标 i − 1 i-1 i−1为结尾的字符串s,和以下标 j − 1 j-1 j−1为结尾的字符串t,相同子序列的长度为 d p [ i ] [ j ] dp[i][j] dp[i][j]?而不是下标 i i i和 j j j为结尾呢?
因为这样的定义在 d p dp dp二维矩阵中可以留出初始化的区间,如果要是定义的 d p [ i ] [ j ] dp[i][j] dp[i][j]是以下标 i i i为结尾的字符串 s s s和以下标 j j j为结尾的字符串 t t t,初始化就比较麻烦了。如图:
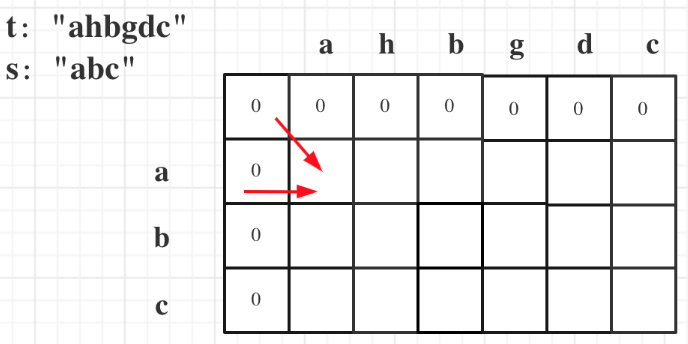
d p [ i ] [ 0 ] dp[i][0] dp[i][0] 表示以下标 i − 1 i-1 i−1为结尾的字符串,与空字符串的相同子序列长度为 0 0 0 , d p [ 0 ] [ j ] dp[0][j] dp[0][j]同理。其实这里只初始化 d p [ i ] [ 0 ] dp[i][0] dp[i][0]就够了,但一起初始化也方便,所以就一起操作了,代码如下:
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
4、
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]都是依赖于
d
p
[
i
−
1
]
[
j
−
1
]
dp[i - 1][j - 1]
dp[i−1][j−1]和
d
p
[
i
]
[
j
−
1
]
dp[i][j - 1]
dp[i][j−1],那么遍历顺序也应该是从上到下,从左到右

class Solution {
public:
bool isSubsequence(string s, string t) {
vector<vector<int>> dp(s.size() + 1, vector<int>(t.size() + 1, 0));
for(int i = 1; i <= s.size(); i++){
for(int j = 1; j <= t.size(); j++){
if(s[i - 1] == t[j - 1]){
dp[i][j] = dp[i - 1][j - 1] + 1;
}
else dp[i][j] = dp[i][j - 1];
}
}
if(dp[s.size()][t.size()] == s.size()) return true;
else return false;
}
};
115. 不同的子序列
1、 d p [ i ] [ j ] dp[i][j] dp[i][j]:以 i − 1 i-1 i−1为结尾的 s s s子序列中出现以 j − 1 j-1 j−1为结尾的 t t t的个数为 d p [ i ] [ j ] dp[i][j] dp[i][j]。
2、当 s [ i − 1 ] s[i - 1] s[i−1]与 t [ j − 1 ] t[j - 1] t[j−1]相等时, d p [ i ] [ j ] dp[i][j] dp[i][j]可以由两部分组成:
- 一部分是用 s [ i − 1 ] s[i - 1] s[i−1]来匹配,那么个数为 d p [ i − 1 ] [ j − 1 ] dp[i - 1][j - 1] dp[i−1][j−1]。
- 一部分是不用 s [ i − 1 ] s[i - 1] s[i−1]来匹配,个数为 d p [ i − 1 ] [ j ] dp[i - 1][j] dp[i−1][j]。
为什么还要考虑 不用 s [ i − 1 ] s[i - 1] s[i−1]来匹配,都相同了指定要匹配啊?
例如: s:bagg 和 t:bag ,s[3] 和 t[2]是相同的,但是字符串s也可以不用s[3]来匹配,即用s[0]s[1]s[2]组成的bag。也可以用s[3]来匹配,即:s[0]s[1]s[3]组成的bag。
所以当
s
[
i
−
1
]
s[i - 1]
s[i−1] 与
t
[
j
−
1
]
t[j - 1]
t[j−1]相等时,dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
当
s
[
i
−
1
]
s[i - 1]
s[i−1] 与
t
[
j
−
1
]
t[j - 1]
t[j−1]不相等时,
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]只有一部分组成,不用
s
[
i
−
1
]
s[i - 1]
s[i−1]来匹配,即:
d
p
[
i
−
1
]
[
j
]
dp[i - 1][j]
dp[i−1][j],所以递推公式为:dp[i][j] = dp[i - 1][j];
3、dp[i][0]=1,以
i
−
1
i-1
i−1为结尾的
s
s
s,删除所有元素,出现空字符串的个数就是
1
1
1。
再来看dp[0][j]=0,
d
p
[
0
]
[
j
]
dp[0][j]
dp[0][j]:空字符串
s
s
s可以随便删除元素,出现以
j
−
1
j-1
j−1为结尾的字符串
t
t
t的个数。
dp[0][0]=1,空字符串
s
s
s,可以删除
0
0
0个元素,变成空字符串
t
t
t。
4、从递推公式中可以看出
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]都是根据左上方和正上方推出来的。所以遍历时一定从上到下,从左到右,保证
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]可以根据之前计算出来的数值进行计算。
class Solution {
public:
int numDistinct(string s, string t) {
//vector<vector<int>> dp(s.size()+1,vector<int>(t.size()+1,0));
vector<vector<unsigned int>> dp(s.size()+1,vector<unsigned int>(t.size()+1,0));
//由于题干给定:题目数据保证答案符合 32 位带符号整数范围。
//(注意此处是0-32的意思不是-16到+16的意思哈)
//因此需要使用unsigned int int是-16到+16的 无符号的int就是0到+32的,同时由于是个数不可能为负数,所以满足答案(0-32位)的要求。
for(int i = 0; i < s.size(); i++) dp[i][0] = 1;
for(int i = 1; i <= s.size(); i++){
for(int j = 1; j <= t.size(); j++){
if(s[i - 1] == t[j - 1]){
dp[i][j] = dp[i - 1][j - 1] + dp[i - 1][j];
}else{
dp[i][j] = dp[i - 1][j];
}
}
}
return dp[s.size()][t.size()];
}
};
583. 两个字符串的删除操作
动态规划解法一:参考 115. 不同的子序列
两个字符串都可以删除。
1、 d p [ i ] [ j ] dp[i][j] dp[i][j]:以 i − 1 i-1 i−1为结尾的字符串 w o r d 1 word1 word1,和以 j − 1 j-1 j−1位结尾的字符串 w o r d 2 word2 word2,想要达到相等,所需要删除元素的最少次数。
2、递推公式的确定:
-
当
word1[i - 1] == word2[j - 1]时,dp[i][j] = dp[i - 1][j - 1]; -
当
word1[i - 1] != word2[j - 1]时,有三种情况:- 情况一:
删word1[i - 1],最少操作次数为dp[i - 1][j] + 1 - 情况二:
删word2[j - 1],最少操作次数为dp[i][j - 1] + 1 - 情况三:同时
删word1[i - 1]和word2[j - 1],操作的最少次数为dp[i - 1][j - 1] + 2 - 递推公式:
dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
- 情况一:
3、从递推公式中可以看出, d p [ i ] [ 0 ] dp[i][0] dp[i][0] 和 d p [ 0 ] [ j ] dp[0][j] dp[0][j]是要初始化的。
d p [ i ] [ 0 ] dp[i][0] dp[i][0]: w o r d 2 word2 word2为空字符串,以 i − 1 i-1 i−1为结尾的字符串 w o r d 1 word1 word1要删除多少个元素,才能和 w o r d 2 word2 word2相同呢,很明显 d p [ i ] [ 0 ] = i dp[i][0] = i dp[i][0]=i。 d p [ 0 ] [ j ] dp[0][j] dp[0][j]同理,所以代码如下:
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
4、
d
p
[
i
]
[
j
]
=
m
i
n
(
d
p
[
i
−
1
]
[
j
−
1
]
+
2
,
m
i
n
(
d
p
[
i
−
1
]
[
j
]
,
d
p
[
i
]
[
j
−
1
]
)
+
1
)
;
d
p
[
i
]
[
j
]
=
d
p
[
i
−
1
]
[
j
−
1
]
dp[i][j] = min(dp[i - 1][j - 1] + 2, min(dp[i - 1][j], dp[i][j - 1]) + 1);dp[i][j] = dp[i - 1][j - 1]
dp[i][j]=min(dp[i−1][j−1]+2,min(dp[i−1][j],dp[i][j−1])+1);dp[i][j]=dp[i−1][j−1]递推公式中可以看出
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]都是根据左上方、正上方、正左方推出来的。所以遍历的时候一定是从上到下,从左到右,这样保证
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]可以根据之前计算出来的数值进行计算。
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min({dp[i - 1][j - 1] + 2, dp[i - 1][j] + 1, dp[i][j - 1] + 1});
}
}
}
return dp[word1.size()][word2.size()];
}
};
动态规划解法二:参考 1143.最长公共子序列
求出两个字符串的最长公共子序列长度,而除了最长公共子序列之外的字符都是必须删除的,最后用两个字符串的总长度减去两个最长公共子序列的长度就是删除的最少步数。
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size()+1, vector<int>(word2.size()+1, 0));
for (int i=1; i<=word1.size(); i++){
for (int j=1; j<=word2.size(); j++){
if (word1[i-1] == word2[j-1]) dp[i][j] = dp[i-1][j-1] + 1;
else dp[i][j] = max(dp[i-1][j], dp[i][j-1]);
}
}
return word1.size()+word2.size()-dp[word1.size()][word2.size()]*2;
}
};
72. 编辑距离
1、 d p [ i ] [ j ] dp[i][j] dp[i][j] 表示以下标 i − 1 i-1 i−1为结尾的字符串 w o r d 1 word1 word1,和以下标 j − 1 j-1 j−1为结尾的字符串 w o r d 2 word2 word2,最近编辑距离为 d p [ i ] [ j ] dp[i][j] dp[i][j]。
2、递推公式:
-
if (word1[i - 1] == word2[j - 1])那么说明不用任何编辑,即dp[i][j] = dp[i - 1][j - 1]; -
if (word1[i - 1] != word2[j - 1]),此时就需要编辑了,编辑有三种方式:-
操作一:删除
word1删除一个元素,那么就是以下标 i − 2 i - 2 i−2为结尾的 w o r d 1 word1 word1与 j − 1 j-1 j−1为结尾的 w o r d 2 word2 word2的最近编辑距离 再加上一个操作。即dp[i][j] = dp[i - 1][j] + 1;word2删除一个元素,那么就是以下标 i − 1 i - 1 i−1为结尾的 w o r d 1 word1 word1 与 j − 2 j-2 j−2为结尾的 w o r d 2 word2 word2的最近编辑距离 再加上一个操作。即dp[i][j] = dp[i][j - 1] + 1;
-
操作二:添加
-
实际上, w o r d 2 word2 word2添加一个元素,相当于 w o r d 1 word1 word1删除一个元素。
例如: w o r d 1 = ′ ′ a d ′ ′ , w o r d 2 = ′ ′ a ′ ′ word1 = ''ad'' ,word2 = ''a'' word1=′′ad′′,word2=′′a′′, w o r d 1 word1 word1删除元素 ′ d ′ 'd' ′d′和 w o r d 2 word2 word2添加一个元素 ′ d ′ 'd' ′d′, 最终的操作数是一样的。
-
-
操作三:替换
word1替换word1[i - 1],使其与word2[j - 1]相同,以下标 i − 2 i-2 i−2为结尾的 w o r d 1 word1 word1 与 j − 2 j-2 j−2为结尾的 w o r d 2 word2 word2的最近编辑距离 加上一个替换元素的操作。即dp[i][j] = dp[i - 1][j - 1] + 1;
-
-
综上,当
if (word1[i - 1] != word2[j - 1])时取最小的,即:dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
3、
d
p
[
i
]
[
0
]
dp[i][0]
dp[i][0] :以下标
i
−
1
i-1
i−1为结尾的字符串
w
o
r
d
1
word1
word1,和空字符串
w
o
r
d
2
word2
word2,最近编辑距离为
d
p
[
i
]
[
0
]
dp[i][0]
dp[i][0]。那么
d
p
[
i
]
[
0
]
dp[i][0]
dp[i][0]就应该是
i
i
i,对
w
o
r
d
1
word1
word1里的元素全部做删除操作,即:dp[i][0] = i;同理dp[0][j] = j;
4、从递推公式可以看出
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]是依赖左方,上方和左上方元素的,所以从左到右从上到下去遍历。
class Solution {
public:
int minDistance(string word1, string word2) {
vector<vector<int>> dp(word1.size() + 1, vector<int>(word2.size() + 1, 0));
for (int i = 0; i <= word1.size(); i++) dp[i][0] = i;
for (int j = 0; j <= word2.size(); j++) dp[0][j] = j;
for (int i = 1; i <= word1.size(); i++) {
for (int j = 1; j <= word2.size(); j++) {
if (word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
}
else {
dp[i][j] = min({dp[i - 1][j - 1], dp[i - 1][j], dp[i][j - 1]}) + 1;
}
}
}
return dp[word1.size()][word2.size()];
}
};
647. 回文子串
暴力解法
两层for循环,遍历区间起始位置和终止位置,然后判断这个区间是不是回文。时间复杂度: O ( n 3 ) O(n^3) O(n3)
class Solution {
public:
bool isGood(const string &str) { //判断是否回文
int left = 0, right = str.size() - 1;
while (left < right) {
if (str[left] != str[right])return false;
//双指针向中间缩
left++;
right--;
}
return true;
}
int countSubstrings(string s) {
int sum = 0;
for (int i = 0; i < s.size(); ++i) {
for (int j = i; j < s.size(); ++j) {
//遍历所有子字符串,然后判断是否回文
if (isGood(s.substr(i, j - i + 1)))sum++;
}
}
return sum;
}
};
动态规划解法
1、布尔类型 d p [ i ] [ j ] dp[i][j] dp[i][j]:表示区间范围 [ i , j ] [i,j] [i,j] (注意是左闭右闭)的子串是否是回文子串,如果是则 d p [ i ] [ j ] dp[i][j] dp[i][j]为 t r u e true true,否则为 f a l s e false false。
2、递推公式:
- 当
s[i]!=s[j],dp[i][j]=false。 - 当
s[i]==s[j]相等时,有如下三种情况:- 情况一:
下标i=j,同一个字符例如 a a a,当然是回文子串 - 情况二:
下标j-i=1,例如 a a aa aa,也是回文子串 - 情况三:
下标j-i>1,例如 c a b a c cabac cabac,此时 s [ i ] = s [ j ] = c s[i]=s[j]=c s[i]=s[j]=c,此时判断 i i i到 j j j区间是不是回文子串还需要看 a b a aba aba是不是回文,那么 a b a aba aba就是 i + 1 i+1 i+1 与 j − 1 j-1 j−1区间,也就是看dp[i + 1][j - 1]是否为true。
- 情况一:
3、 d p [ i ] [ j ] dp[i][j] dp[i][j]可以初始化为 t r u e true true么? 当然不行,怎能刚开始就全都匹配上了。所以 d p [ i ] [ j ] dp[i][j] dp[i][j]初始化为 f a l s e false false。
4、遍历顺序:
在递推公式的情况三中根据 d p [ i + 1 ] [ j − 1 ] dp[i+1][j-1] dp[i+1][j−1]是否为 t r u e true true,以此对 d p [ i ] [ j ] dp[i][j] dp[i][j]进行赋值 t r u e true true。 d p [ i + 1 ] [ j − 1 ] dp[i + 1][j - 1] dp[i+1][j−1]在 d p [ i ] [ j ] dp[i][j] dp[i][j]的左下角,如果从上到下,从左到右遍历,会用到没有计算过的 d p [ i + 1 ] [ j − 1 ] dp[i + 1][j - 1] dp[i+1][j−1],也就是根据不确定是不是回文的区间 [ i + 1 , j − 1 ] [i+1,j-1] [i+1,j−1]来判断了 [ i , j ] [i,j] [i,j]是不是回文,那结果一定是错的。
所以要从下到上,从左到右遍历,这样保证都是经过计算的。有的代码实现是优先遍历列,然后遍历行,其实也是一个道理,都是为了保证
d
p
[
i
+
1
]
[
j
−
1
]
dp[i + 1][j - 1]
dp[i+1][j−1]都是经过计算的。
class Solution {
public:
int countSubstrings(string s) {
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int result = 0;
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j] && (j - i <= 1 || dp[i + 1][j - 1])) {
result++;
dp[i][j] = true;
}
}
}
return result;
}
};
//时间复杂度:O(n^2);空间复杂度:O(n^2)
双指针解法
首先确定回文串,就是找中心然后向两边扩散看是不是对称的就可以了。
在遍历中心点的时候,要注意中心点有两种情况:一个元素可以作为中心点,两个元素也可以作为中心点。
class Solution {
public:
int countSubstrings(string s) {
int result = 0;
for (int i = 0; i < s.size(); i++) {
result += extend(s, i, i, s.size()); // 以i为中心
result += extend(s, i, i + 1, s.size()); // 以i和i+1为中心
}
return result;
}
int extend(const string& s, int i, int j, int length) {
int result = 0;
while (i >= 0 && j < length && s[i] == s[j]) {
i--;
j++;
result++;
}
return result;
}
};
//时间复杂度:O(n^2);空间复杂度:O(1)
类似题目:5. 最长回文子串
暴力解法(超时辽)
列举所有的子串,判断是否为回文串,保存最长的回文串。
class Solution {
public:
bool isGood(const string &str) { //判断是否回文
int left = 0, right = str.size() - 1;
while (left < right) {
if (str[left] != str[right])return false;
//双指针向中间缩
left++;
right--;
}
return true;
}
string longestPalindrome(string s) {
string ans;
int maxval = 0;
for (int i = 0; i < s.size(); ++i) {
for (int j = i; j < s.size(); ++j) {
string test = s.substr(i, j - i + 1);
//遍历所有子字符串,然后判断是否回文
if (isGood(s.substr(i, j - i + 1)) && test.size() > maxval){
ans = s.substr(i, j - i + 1);
maxval = max(maxval, (int)ans.size());
//注意size()的返回值是size_t类型,在max函数里必须是两个同类型值进行比较,所以进行强转
}
}
}
return ans;
}
};
动态规划解法
class Solution {
public:
string longestPalindrome(string s) {
vector<vector<bool>> dp(s.size(), vector<bool>(s.size(), false));
int maxlenth = 0;
int left = 0;
int right = 0;
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i; j < s.size(); j++) {
if (s[i] == s[j] && (j - i <= 1 || dp[i + 1][j - 1])) {
dp[i][j] = true;
}
if (dp[i][j] && j - i + 1 >maxlenth) {
maxlenth = j - i + 1;
left = i;
right = j;
}
}
}
return s.substr(left, maxlenth);
}
};
双指针解法
class Solution {
public:
int left = 0;
int right = 0;
int maxLength = 0;
string longestPalindrome(string s) {
for (int i = 0; i < s.size(); i++) {
extend(s, i, i, s.size()); // 以i为中心
extend(s, i, i + 1, s.size()); // 以i和i+1为中心
}
return s.substr(left, maxLength);
}
void extend(const string& s, int i, int j, int length) {
while (i >= 0 && j < length && s[i] == s[j]) {
if (j - i + 1 > maxLength) {
left = i;
right = j;
maxLength = j - i + 1;
}
i--;
j++;
}
}
};
516. 最长回文子序列
上面的647题求的是回文子串,而本题要求的是回文子序列,要搞清楚这两者之间的区别:回文子串是要连续的,回文子序列不是连续的!
1、 d p [ i ] [ j ] dp[i][j] dp[i][j]:字符串 s s s在 [ i , j ] [i, j] [i,j]范围内最长的回文子序列的长度为 d p [ i ] [ j ] dp[i][j] dp[i][j]。
2、如果 s [ i ] s[i] s[i]与 s [ j ] s[j] s[j]相同,那么 d p [ i ] [ j ] = d p [ i + 1 ] [ j − 1 ] + 2 ; dp[i][j] = dp[i + 1][j - 1] + 2; dp[i][j]=dp[i+1][j−1]+2;
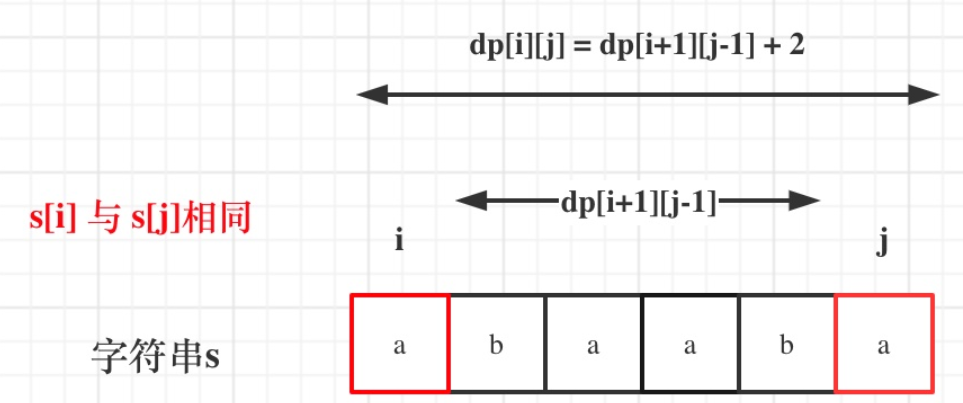
如果 s [ i ] s[i] s[i]与 s [ j ] s[j] s[j]不相同,说明 s [ i ] s[i] s[i]和 s [ j ] s[j] s[j]的同时加入 并不能增加 [ i , j ] [i,j] [i,j]区间回文子串的长度,那么分别加入 s [ i ] s[i] s[i]、 s [ j ] s[j] s[j]看看哪一个可以组成最长的回文子序列。
加入 s [ j ] s[j] s[j]的回文子序列长度为 d p [ i + 1 ] [ j ] dp[i + 1][j] dp[i+1][j]。加入 s [ i ] s[i] s[i]的回文子序列长度为 d p [ i ] [ j − 1 ] dp[i][j - 1] dp[i][j−1]。那么 d p [ i ] [ j ] dp[i][j] dp[i][j]一定是取最大的,即: d p [ i ] [ j ] = m a x ( d p [ i + 1 ] [ j ] , d p [ i ] [ j − 1 ] ) ; dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); dp[i][j]=max(dp[i+1][j],dp[i][j−1]);
3、首先要考虑当 i i i和 j j j 相同的情况,从递推公式:$dp[i][j] = dp[i + 1][j - 1] + 2; $ 可以看出递推公式是计算不到 i i i 和 j j j 相同时候的情况。所以需要手动初始化一下,当 i i i与 j j j相同,那么 d p [ i ] [ j ] dp[i][j] dp[i][j]一定是等于 1 1 1的,即:一个字符的回文子序列长度就是 1 1 1。其他情况 d p [ i ] [ j ] dp[i][j] dp[i][j]初始为 0 0 0就行,这样递推公式: d p [ i ] [ j ] = m a x ( d p [ i + 1 ] [ j ] , d p [ i ] [ j − 1 ] ) ; dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]); dp[i][j]=max(dp[i+1][j],dp[i][j−1]);中 d p [ i ] [ j ] dp[i][j] dp[i][j]才不会被初始值覆盖。
4、
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]是依赖于
d
p
[
i
+
1
]
[
j
−
1
]
dp[i + 1][j - 1]
dp[i+1][j−1]和
d
p
[
i
+
1
]
[
j
]
dp[i + 1][j]
dp[i+1][j](
d
p
[
i
]
[
j
]
dp[i][j]
dp[i][j]下一行的数据)。 所以遍历
i
i
i的时候一定要从下到上遍历,这样才能保证,下一行的数据是经过计算的。

class Solution {
public:
int longestPalindromeSubseq(string s) {
vector<vector<int>> dp(s.size(), vector<int>(s.size(), 0));
for (int i = 0; i < s.size(); i++) dp[i][i] = 1;
for (int i = s.size() - 1; i >= 0; i--) {
for (int j = i + 1; j < s.size(); j++) {
if (s[i] == s[j]) {
dp[i][j] = dp[i + 1][j - 1] + 2;
} else {
dp[i][j] = max(dp[i + 1][j], dp[i][j - 1]);
}
}
}
return dp[0][s.size() - 1];
}
};

















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











