






杨立昆哈佛大学演讲:生成式大模型很糟糕,我们需要目标驱动的AI
2024年3月28日,杨立昆在哈佛大学数学科学和应用中心(CMSA)做了一场学术演讲(2024 Ding Shum Lecture)。
杨立昆是法国计算机科学家Yann LeCun的中文名,他任Meta首席人工智能科学家和纽约大学教授,他带领 Meta 的团队推出了开源大模型领域 Llama。他与 Yoshua Bengio、Geoffrey Hinton一同获得2018年的图灵奖。
 杨立昆在哈佛大学演讲现场
杨立昆在哈佛大学演讲现场
演讲标题:目标驱动的人工智能:迈向能学习、记忆、推理和规划的AI系统
演讲摘要:机器如何能够像人类和动物一样高效地学习?机器如何学习世界的运行方式并获得常识?机器如何学习推理和规划?当前的AI架构(如自回归大型语言模型)存在不足,我提出一种模块化认知架构,可能会回答这些问题。该架构的核心是一个世界模型,使系统能够预测其行为的后果,并规划一系列动作,以最优实现一组目标。这些目标包括确保系统的可控性和安全性。
 演讲PPT封面
演讲PPT封面
整个演讲1小时16分钟,演讲记录约12000字,本文对其进行了整理和缩略。
1. 机器学习很糟糕
机器学习很糟糕,至少与我们在人类和动物身上观察到的相比,它真的不那么出色。
动物和人类可以很快地通过几次尝试或学习,理解世界是如何运作的,他们可以进行推理和规划,他们有常识,这是今天绝大多数AI系统做不到的。
在不远的将来,或者说不那么近的将来,我们与数字世界的每一次互动,都将通过一个人工智能系统来中介。我现在其实戴着智能眼镜,我可以给你们拍照,我可以按一个按钮或者说,“嘿,Meta,拍张照”,它就会拍照;我问一个问题,然后就会有AI回答,你们听不到,因为它通过骨传导,这非常酷。
 Machine Learning sucks!
Machine Learning sucks!
所以,一旦我们拥有具有人类水平智力的智能助手,这将放大人类的全球智力。
不幸的是,我们离这还很远,尽管硅谷的炒作总是告诉你AGI即将到来。我们实际上并没有那么接近。这是因为我们目前拥有的AI系统,在一些能力上极其有限。
如果我们有了接近人类智力的系统,我们就会有能够在20小时练习中学会驾驶汽车的系统,就像任何17岁的青少年那样;我们就会有家用机器人,能够一次性学会清理餐桌和清空洗碗机,就像10岁孩子那样。
所以我们漏掉了一些重要的东西。
我们漏掉的是:让AI学习世界是如何运作的,不仅仅是从文本中学习,还可以从视频或者其他感官输入中学习。
我们的需要的是:一个拥有世界模型,拥有记忆,能够推理,能够规划行动的系统,它同时是可控和安全的,这就是目标驱动的AI。
2. LLM有很大的局限性
LLM以及图像识别、语音识别、翻译等,AI中所有很酷的这些东西,都归功于自监督学习。
做这件事的方式是,你拿一段数据,比如一段文本,以某种方式转换或破坏它,比如用空白标记替换其中的一些单词。然后你训练一些巨大的神经网络来预测缺失的单词,这就是LLM的训练方式。
Meta也有这样的AI,我输入这样的提示:“生成一张照片,一位哈佛数学家在黑板上证明黎曼假设,在一个智能机器人的帮助下。”生成的图片如下:
 AI生成一张数学家证明黎曼假设的图片
AI生成一张数学家证明黎曼假设的图片
我检查了证明,它是不正确的。事实上,我不知道其中的一些符号是什么。
每个人都对生成式AI感到兴奋,它们工作得很好,是因为LLM会在数十万亿个token上训练(token是一个子词单位,平均是3/4个单词)。一个token通常是两个字节,训练LLM需要2乘以10的13次方个字节,如果一个人每天阅读8小时,每分钟250个单词,需要17万年,如果你读得快,每天阅读12小时,也需要10万年。
LLM这种东西会犯愚蠢的错误。 它们并不真正理解逻辑,如果你告诉它们A和B是一回事,它们不一定知道B和A也是一回事。它们并不真正理解排序关系的传递性以及类似的东西。它们不会做逻辑推理。你必须明确地教它们做算术,或者让它们调用工具来做算术。
 自回归LLM是注定要失败的
自回归LLM是注定要失败的
它们对底层现实没有任何了解。它们只是在文本上训练。 有些还在图像上训练,但基本上是将图像视为文本。所以它们非常有限。
我们知道,自回归LLM是不断预测下一个单词来产生句子的,每次系统生成一个单词,都有一定概率这个单词不在正确答案的集合中,所以一个单词序列成为正确答案的概率随着答案长度呈指数级下降,这不是一件好事。有各种技术论文讨论这个问题,都倾向于表明这一点。
还有很多研究,探讨这些系统是否真的能够做规划,答案是不行,它们真的不能规划。每当它们看似可以规划时,基本上是因为它们已经在非常相似的情况下训练过,它们看到过一个计划,它们基本上只是重复一个非常相似的计划。
 我们漏掉了重要的东西
我们漏掉了重要的东西
最后一点,它们是在语言上训练的。所以它们只知道语言中包含的知识。但大多数人类知识实际上与语言无关,我想再次重复17岁孩子学习驾驶或10岁孩子学习收拾餐桌的例子。
这被称为莫拉维克悖论,即有些事情对人类来说很复杂,比如下棋,或规划复杂的轨迹,但对计算机来说却相当简单。那些我们认为理所当然、不需要智能的事情,比如猫能做的事情,实际上非常复杂。
考虑一个4岁的人类孩子,他醒着的时间已经有16000小时(心理学家是这么告诉我们的),我们有200万根视神经纤维进入我们的视觉皮层(每只眼睛大约有100万根),每根纤维每秒携带大约10个字节。所以,一个4岁孩子通过视觉接受到的数据量,可能在10的15次方个字节左右,这超过了互联网上所有公开文本的总量的50倍。
 孩子和LLM获得信息量的对比
孩子和LLM获得信息量的对比
这告诉你很多事情,但首先它告诉你,我们永远不可能仅通过语言训练就能让AI达到人类的智能水平,这是不可能的。
我们从世界中获得的背景知识实在太多了,而当前的AI没有这些知识。
所以这让我有了“目标驱动的AI系统”的想法。
3.目标驱动的AI系统
是什么让人类或动物能够以新的方式使用工具、物品,并发明新的行为方式?
我写了一篇相当易读、相当长的论文:“通往自主机器智能之路” (A path towards autonomous machine intelligence)
你可以在这个URL看到:
https://openreview.net/forum?id=BZ5a1r-kVsf
在我的方法中,基础架构如下图所示:
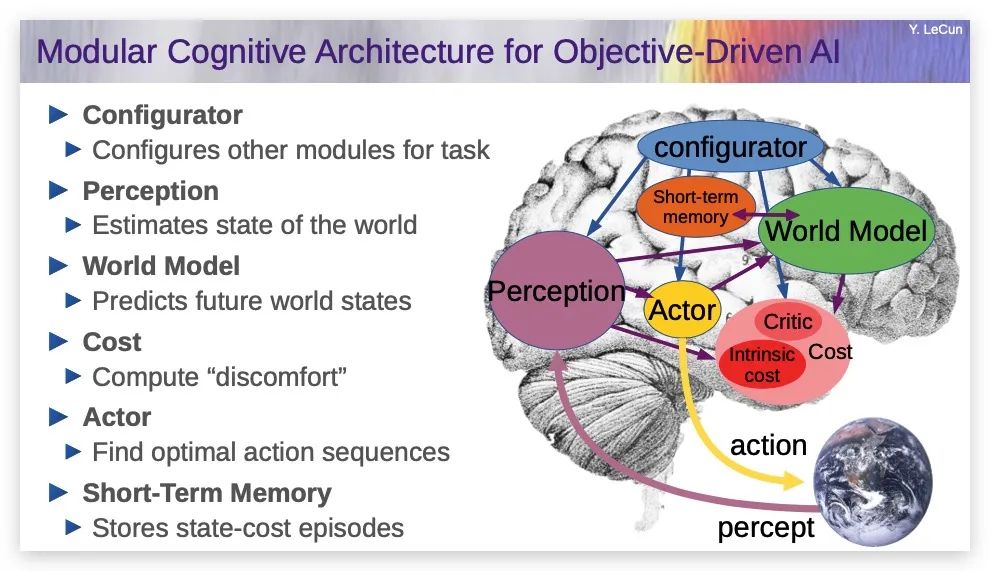 目标驱动Al的模块化认知结构
目标驱动Al的模块化认知结构
你看到的图中的每个箭头,意味着有信号通过,也意味着可能有反向传播(我假设里面的一切都是可微的)。
在这个架构中,有一个感知模块,用来观察世界,并将其转化为对世界的表示;有一个持久记忆模块,用来记录事实;有一个世界模型,这是系统的核心;有一个动作模块,一个成本模块,一个配置器。系统的工作方式如下:
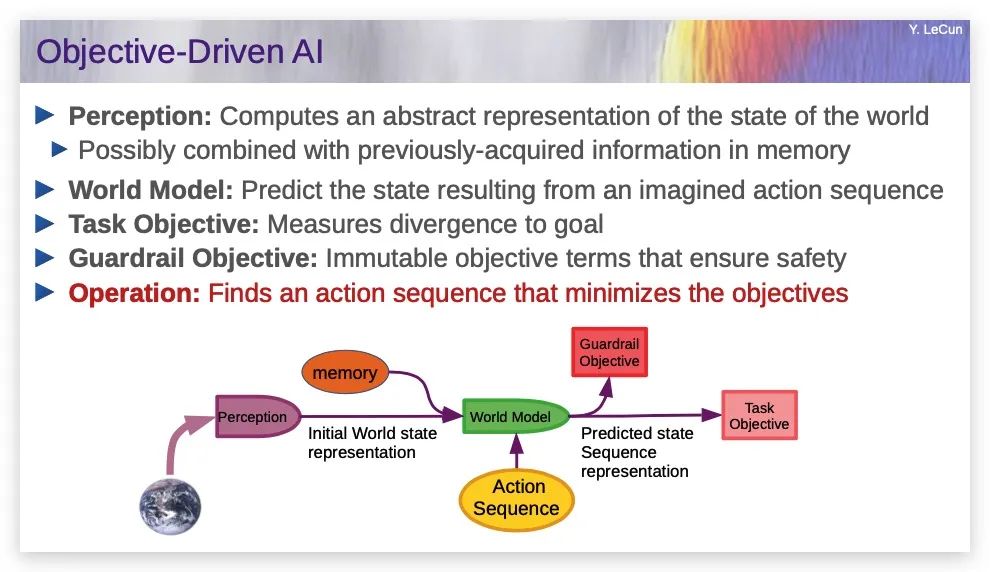 目标驱动的AI
目标驱动的AI
一个典型的场景是AI观察世界,将其输入感知系统,产生对当前世界状态的认识,也许它可以将其与记忆中的内容结合起来,记忆中包含先前观察到的世界状态。世界模型的作用是接收当前世界状态、可能的行动序列,产生对未来世界状态的预测。
红色或粉色的方框,会计算一个标量值,以预测的未来世界状态为输入,告诉你离特定目标有多远,离护栏(Guardrail)目标有多远(也即这个状态在多大程度上是危险的)。
系统将搜寻一个行动序列,以使预测的世界状态满足目标,这与那些多层神经网络有本质的不同。这基本上是一个优化问题,如果这个推理的空间是连续的,我们可以使用基于梯度的方法,因为所有这些模块都是可微的。
我们可以通过那些箭头反向传播梯度,然后更新行动序列,最后收敛到最优行动序列。
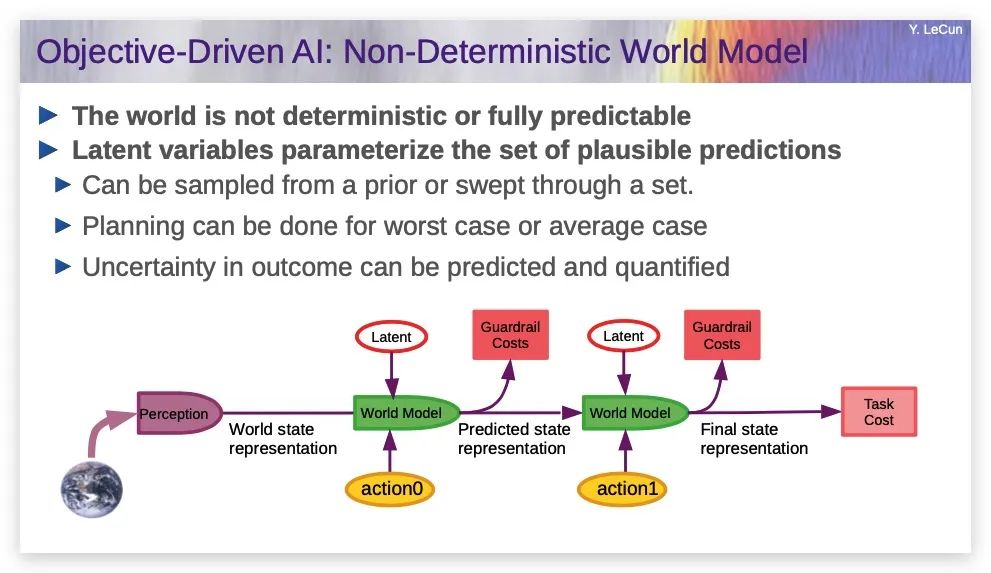 非确定性世界模型
非确定性世界模型
所以,一开始,初始世界序列和初始动作被输入世界模型,然后,预测下一个状态,在那个状态下,我们输入另一个动作,来预测下下个状态。整个序列都可以输入到护栏目标,最终结果输入到任务目标。
世界可能是确定性的,比如我抓住这个瓶子会发生什么,几乎没有不确定性,因为我掌控着。但大部分世界并非确定性的,这时,你需要某种潜变量(Latent)输入你的世界模型,来解释你不知道的世界的所有事情,你可以在某种分布内选取多个潜变量,并做出多个预测,预测未来可能发生什么。
你最终想做的,不是这种单层规划,而是想做分层规划。举个例子。假设我坐在纽约大学的办公室里,我想去巴黎。我不会做毫秒级的计划,这是不可能的,因为我不知道将会发生的情况。我是否必须避开一个我还没看到的特定障碍?红绿灯会是红色还是绿色?我要等多久才能打到出租车?所以,我不能从一开始就计划好一切,
但我能做高层规划,我知道我需要到机场并登机,这是两个宏观动作,对吧?然后再决定较低层次的子目标,我如何到达机场?嗯,我在纽约,所以我需要下楼到街上打车,就是下一层的目标。
我如何到达我要去的街道,我必须坐电梯下去,然后走到街上?我如何去电梯?我需要从椅子上站起来,打开办公室的门,走到电梯,按下按钮。
所以你可以想象有这种分层规划在进行。我们完全不费力气就能做到这一点,动物也能很好地做到这一点。今天没有任何AI系统能够做到这一点。
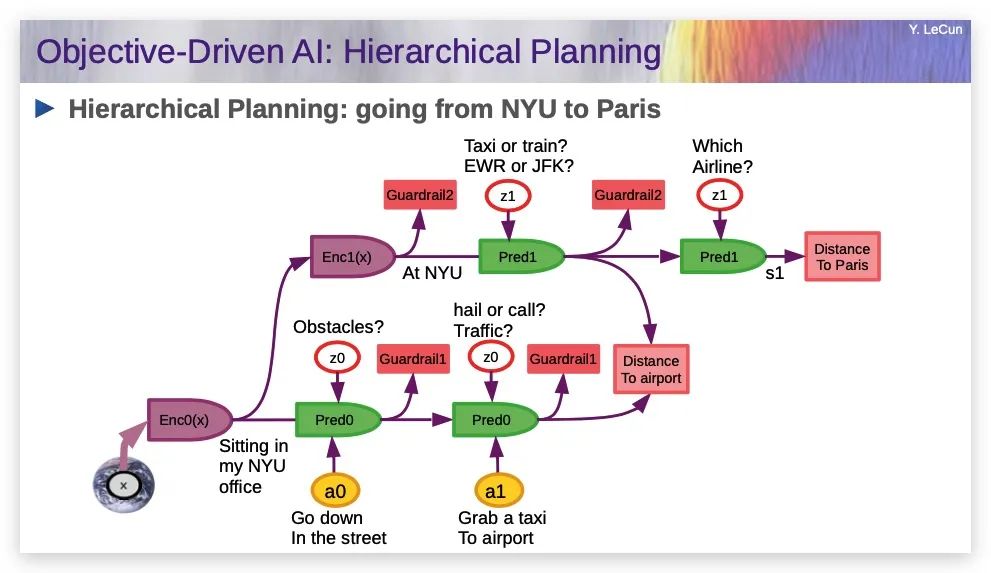 目标驱动的AI:分层规划
目标驱动的AI:分层规划
如果我们要建立这种类型的系统,我们如何构建世界模型?人类或动物是如何做到这点的?
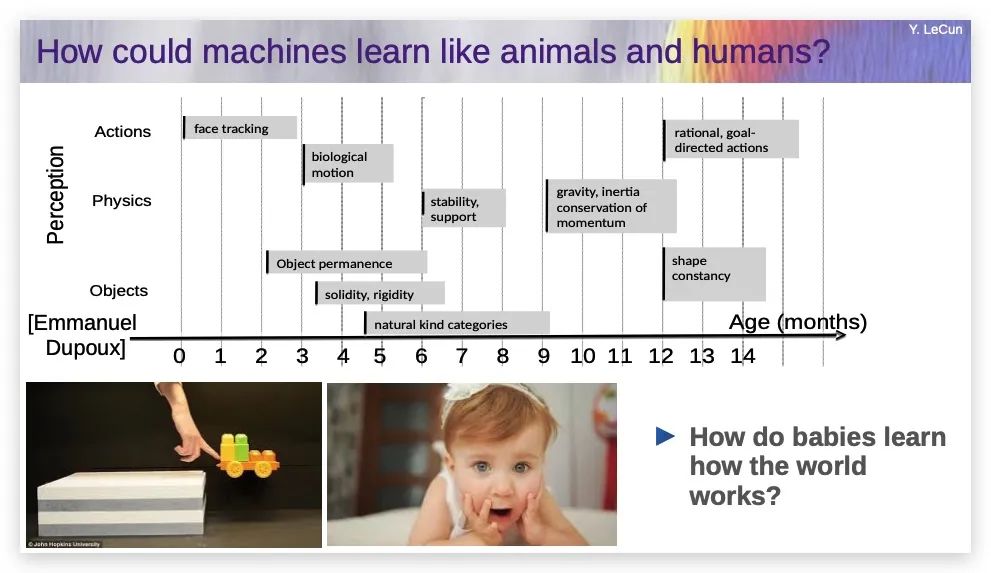 婴儿是怎么学习世界的
婴儿是怎么学习世界的
四个月大的婴儿并不真正理解语言,但他们自发地发展了对象类别的概念,比如物体的固体性、刚性,有生命和无生命物体的区别。
然后,婴儿需要大约9个月的时间,明白没有支撑的物体会因为重力而下落,以及直觉物理学中的更多概念。这并不快,对吧?
我的意思是,我们花很长时间来学习这些。人们至少在生命的最初几个月主要通过观察学习,几乎没有与世界互动,因为婴儿直到三四个月大还不能真正操纵任何东西或影响除了肢体以外的世界。他们对世界的大部分了解主要是观察。
问题是,当婴儿这样做时,发生了什么类型的学习?这就是我们需要复制的。
有一个很自然的想法,就是把自监督训练文本的想法移植到视频上:拍一段视频,称之为y,这是完整视频,然后通过遮盖其中一部分来破坏它,比如说遮盖后半段的视频为x,然后训练一些巨大的神经网络来预测缺失的视频部分。
如果系统能预测视频中将要发生的事情,那么,它可能对物理世界的底层本质有很好的认识。
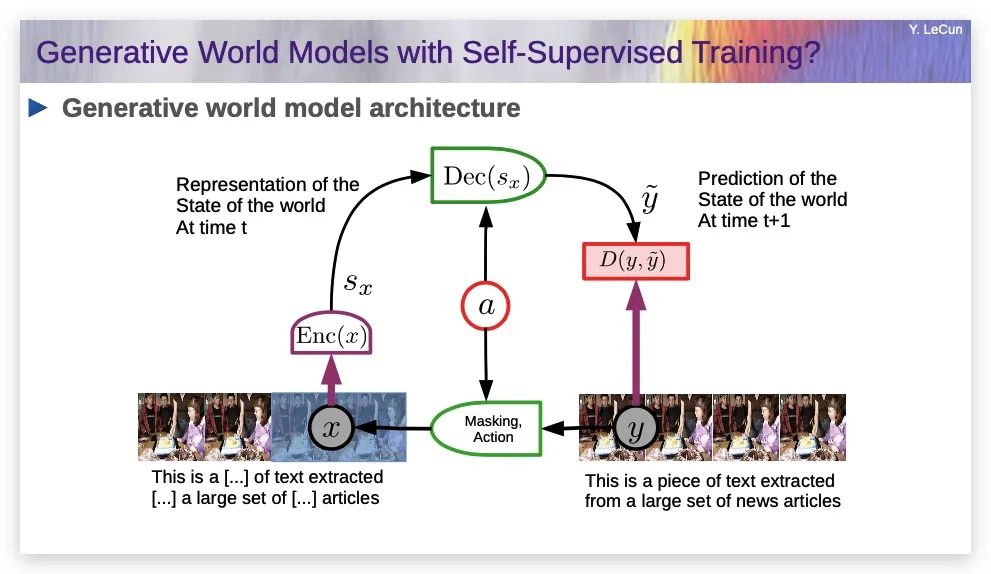 生成式世界模型架构
生成式世界模型架构
这是个非常自然的概念,事实上,神经科学家很长时间以来一直在思考这类问题,这被称为预测编码。但如果你这样做,它不起作用。我们尝试了,我和我的同事尝试这样做,做了10年,没有得到良好的预测,我们得到的预测非常模糊。
原因是它无法真正预测将要发生的事情,所以它预测所有可能发生的事情的平均值。那会是一个非常模糊的视频。
解决这个问题的方法基本上是放弃生成模型的想法。这可能看起来很令人震惊,因为这是目前机器学习中最流行的东西。但我们不得不这样做。
4. 解决方案是JEPA
我提出的解决方案是:用我称之为联合嵌入预测架构(JEPA)的东西来取代它。
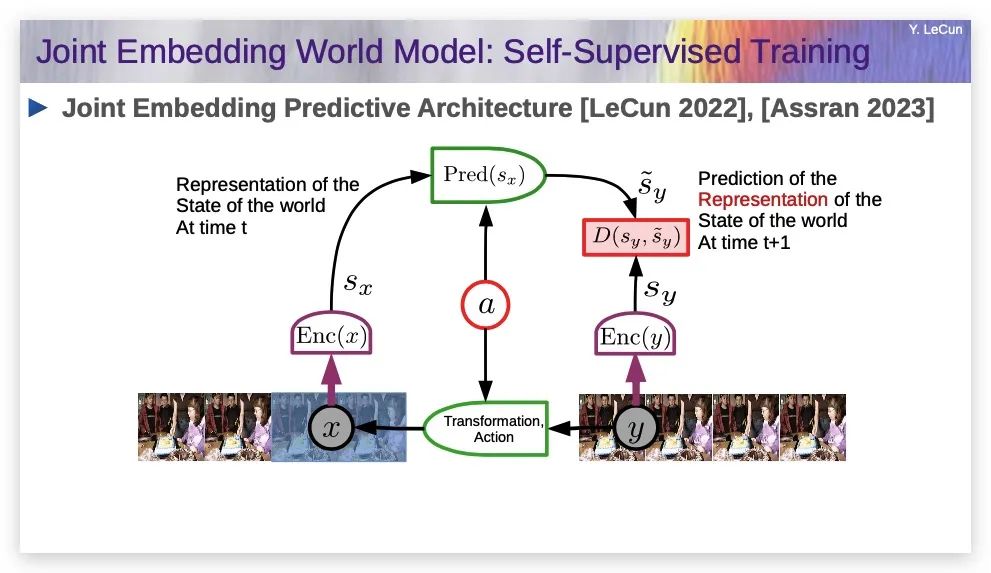 联合嵌入世界模型:自监督训练
联合嵌入世界模型:自监督训练
上图就是JEPA。
你遮盖y的一部分,得到x;但不是直接预测y,而是将y也通过一个编码器。
你是从“x的表示”重建“y的表示”,所以你不是预测每个像素,而只是试图预测y的表示,它可能不包含关于y的所有信息,可能只包含部分信息。这就是这两种架构之间的区别。
在推理时,x是一个观察,sx是那个观察的表示。a将是你采取的一个行动(或者你观察到有人在采取行动),然后sy是你采取行动后世界状态表示的预测,y就是预测的未来世界状态,对吧?
然后,你可以拿y和你观察到的世界实际状态做比较,训练系统以最小化预测误差。但有一个问题,就是该系统可能会崩溃,如果你只是最小化预测误差,它可能完全忽略x和y,生成恒定sx和sy,这样的预测是没有意义的,你必须使用一些更聪明的方法,比如基于能量的模型。
(这里略去部分演讲内容)
总之,我的建议是,放弃生成模型,转而使用那些联合嵌入架构;放弃概率建模,转而使用基于能量的模型;放弃对比方法,转而使用那些正则化方法。还有,放弃强化学习,我已经说了有10年了。
它们可是当今机器学习中最流行的四件事,所以我知道,我的建议并不讨喜。
5. 我们不需要那些不重要的信息
预测图像中缺失的内容非常困难,因为图像中可能有复杂的纹理,诸如此类。
拿这个讲座的视频举例,我把相机指向这个方向,慢慢平移,在你前面停下,这时,我们让系统预测视频中接下来会发生什么。
系统可能会预测:平移会继续,会有人坐着,在某个时候会有一面墙。它绝对不可能预测我们任何人长什么样,它也不可能预测楼梯有多少级,它不可能预测墙壁或地毯的精确纹理,对吧?所以这里有各种完全无法预测的细节。
如果你训练一个生成式系统,它实际上将不得不投入大量资源来预测那些细节,对吧?
所以,在某种程度上,我们只需要预测有用的部分:比如你想预测行星的轨迹,行星上的大部分信息对预测来说是完全不相关的,唯一重要的是六个变量,即位置和速度(编者注:位置和速度都是三维的)。
所以做预测的大问题是:什么是适当的信息和适当的抽象层次?然后你消除其他所有东西,因为如果你把所有资源都花在试图预测那些无关紧要的事情上,你就完全是在浪费时间。
为什么预测文本容易,预测图像困难?原因在于,图像是高维和连续的,所以生成它们实际上很难,而文本是离散的。
所以语言很简单,有一种观点认为语言是最复杂的东西,因为只有人类能做到。事实上,它很简单,真正的世界才是真正困难的。
我们最近上线了V-JEPA,它是一个用于视频训练的模型架构,你取一段视频,遮盖其中的一部分,然后用V-JEPA训练,基本上可以预测完整视频的表示。
我们将其用在了许多不同类型的视频上,在动作分类和各种其他任务上,V-JEPA都获得了非常好的性能,比之前人们尝试过的任何其他方法都要好。而且预训练实际上是在相对较少量的视频上进行的,并不需要一个巨大的数据集。
 V-JEPA:使用单独训练的解码器重建视频
V-JEPA:使用单独训练的解码器重建视频
上图是对视频重建的示意,它通过单独训练一个解码器来完成,这个训练不是初始训练的一部分,但最终,我们可以使用这个解码器重建视频中缺失的部分。
在上图中,你可以看到,系统正在填充合理的东西,这是一段烹饪视频,在将其中部分内容用白色方块遮盖后,让模型重建视频,你可以看到,重建后,这里有一只手、一把刀和一些食材。
我们取一段视频,遮盖后面的部分,告诉其正在采取的动作,要求系统预测将要发生的事情。如果你有这个,你就有了一个世界模型。 如果你有一个世界模型,就可以将其放入规划系统。如果你有一个可以规划的系统,你就可能拥有比当前AI更智能的系统,它们可以够规划行动,而不仅仅是词语,它们不再以自回归的方式预测。
我们正在研究从视频中进行自监督学习,使用我所说的目标驱动架构,证据表明系统可以根据目标进行推理和规划,不仅适用于视频,对于文本和机器人控制,也是如此。
6. 为什么我们需要开源的AI平台
 未来无处不在的AI虚拟助理
未来无处不在的AI虚拟助理
在未来,我们和数字世界的每一次互动都会有AI系统作为媒介,这意味着AI系统将本质上构成所有人类知识的储存库,每个人都会使用,有点像一个你可以对话的维基百科,但比维基百科知道得更多。
每一个这样的AI系统必然是有偏见的,它们是通过互联网上可用的数据训练的,其中,英语的数据比任何其他语言都多。这些系统必然会有偏见。我们看到了一些相当戏剧性的例子,比如Google的Genie系统,他们花了很多努力来确保系统没有偏见,最后它以另一种令人讨厌的方式表现出偏见。
所以偏见是不可避免的。在媒体和新闻界也是一样,每一份期刊、每一份新闻杂志报纸都有偏见。我们解决这个问题的方法是拥有高度多样化的非常不同的杂志和报纸。我们不会从单一系统获取信息,我们可以在各种有偏见的系统之间进行选择。
同样地,我们不会有无偏见的AI系统,我们需要一个非常简单的平台,基本上允许任何人根据自己的语言、文化、价值观、兴趣来微调一个开源AI系统,这就是我看到的、我想看到的AI的未来。
我很高兴地说,Meta已经完全接受了AI平台需要开放的想法,并致力于开源Llama的各种版本。开源AI平台是必要的。
 AI平台应该开源
AI平台应该开源
一个大的危险是,开源AI平台将被监管得无法存在,因为有些人认为AI是危险的,他们说“你不能把AI交到每个人手中,它太危险了,你需要监管它”。
其实,这更加危险,这样做的危险要比把AI交到每个人手中的危险高得多。
强大的AI不是一天就能出现的,而是一个渐进的过程。我们需要构建我所描述的这种类型的系统,使它们越来越强大,让它们学习越来越多的东西,设置越来越多的护栏和目标等等,随着它们变得越来越聪明,它们也会变得更加安全可靠和行为良好。
在这个过程中,每个人都可以做出贡献,这就是为什么我们需要开源模型。
7. 未来的AI很危险吗
达到人类水平的AI还需要多长时间?LLM的支持者说会在明年或今年年底之前,这是扯淡,尽管你可能从OpenAI那里听到这样的说法。我认为大概五年内都不会。
有一种想法是,突然间,超级智能系统会在几分钟内接管世界,这完全是荒谬的,世界根本不是这样运作的。
 AI在短期和长期对人类的风险及对策
AI在短期和长期对人类的风险及对策
但有一些很有钱的人,他们资助了许多智库,智库游说政府相信这种风险,所以政府会组织会议,讨论类似“我们明年都会死光光吗?”这种问题。
所以我们必须先告诉政府,我们离人类级智能还很远,不要相信那些告诉你超级智能就在眼前的人,比如Elon。
我们可以以无危险的方式构建它们,超级人工智能不会是一个事件,它将是渐进的,我们有办法以安全的方式构建这些东西。
不要将当前LLM不可靠的事实投射到未来的系统中,未来的系统可能会有完全不同的架构,也许是我描述的类型,它们是可控的,因为你可以对它们设置护栏和目标。
所以,讨论现在的AI今后可能存在的风险,是无厘头的,因为未来的AI还没有被发明出来,我们不知道它们会是什么样子。
这就像在1925年讨论喷气式客机跨大西洋飞行的安全性,我们知道,喷气发动机在那时还没有被发明出来,而且这不是一天就发生的,对吧?它花了几十年的时间,现在你可以乘坐双引擎喷气式飞机完全安全地飞到地球的另一端,这太神奇了。
AI也会是同样的事情。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
 #### 一、全套AGI大模型学习路线
#### 一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









