







关于数据库优化需要从三个方面考虑:
1、数据存储分区
2、表索引
3、SQL语句优化
1 数据存储分区,我们的财险系统,购买保险的用户来自不同的地区,考虑到保单数量可能接近上亿条,单纯的为表建立索引不能满足性能的需要,因此保单表按省份做了列表分区,使不同省的保单存储到不同的数据分区,当查询数据加上省份条件时,只会检索对应分区的数据,大大缩小数据检索的范围,从而提高查询性能。【备注:每个项目组按照自己项目的实际分区情况举例说明】
分区还有:
范围分区(比如按照日期字段来建立分区,一个季度或者一个月的数据划分为一个区)
散列分区(不指定分区条件,oracle自动将数据平均分配)
复合分区(比如:做了分区后,每个分区里面再次做分区)
2 表索引,为表建立好分区以后,在分区里面添加索引,进一步提高数据的查询速度,我们项目里用到索引的比如(客户信息表 姓名建立btree索引、身份证号建立唯一索引、客户编号建立主键,主键自带唯一索引)(产品表 产品类别建立位图索引)(经常用到的表关表关联条件建立索引)【备注:按照自己项目建立索引的实际情况举例说明】
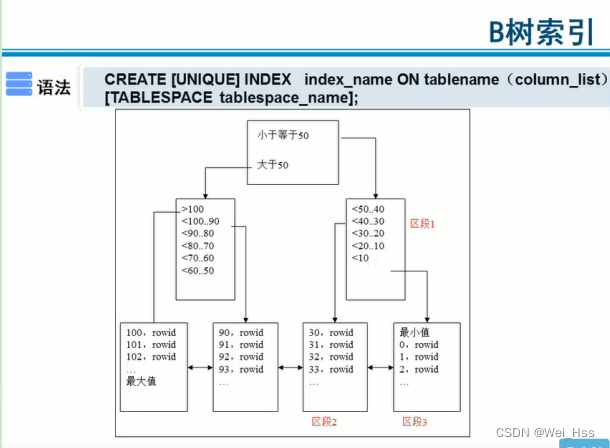
索引之所以会提高查询速度,我大概介绍一下它的原理,索引有一套独立的系统表存储数据与rowid的对应关系(如书本的目录),比如btree索引,它是一个树形结构图,有根节点、分支节点、叶子节点,根节点只有一个,分支节点数量不固定由oracle合理分配,分支节点存储数据的范围,最终的分支节点下面有叶子节点,叶子节点负责存储具体的值和rowid。
比如:根节点存储大于50和小于50两个范围,两个分支节点,大于50的分支节点存储50-60、60-70、大于100等区段,每个区段都有对应的叶子节点,比如大于100的区段下面的叶子节点存储100、101、102和对应的rowid等具体数据,100、101、102的值即为表中建立索引的列(比如:num)的值,当编写sql语句where num=101时,就会通过检索索引表,查询到叶子节点上存储的rowid,然后根据rowid查询对应的数据,避免了对数据表的全表扫描。
当然,索引也不是越多越好,索引适合建立在经常作为条件的列(即where后作为条件的列,包括关联条件)、以及 order by的列。如果对于增删改性能要求特别高而查询要求不高的表就不建议建立索引了,因为索引会降低增删改的效率。
3 SQL语句优化(重点在理解,不需要一字不漏背下来,抽查面试题时只要求背出自己理解的几点即可)
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.
备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num = 0
3.应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = 'admin'
可以这样查询:
select id from t where num = 10
union all
select id from t where Name = 'admin'
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
6.如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num = @num
可以改为强制查询使用索引:
select id from t with(index(索引名)) where num = @num
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2 = 100
应改为:
select id from t where num = 100*2
7.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描,除非建立函数索引。如:
select id from t where substring(name,1,3) = ’abc’ -–name以abc开头的id
select id from t where datediff(day,createdate,’2005-11-30′) = 0 -–‘2005-11-30’ --生成的id
应改为:
select id from t where name like 'abc%'
select id from t where createdate >= '2005-11-30' and createdate < '2005-12-1'
8.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
9.Update 语句,如果只更改1、2个字段,不要Update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
10.对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
11.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
12.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连 接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
13.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
14.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
15.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
4.表中有大字段X(例如:text类型),且字段X不会经常更新,以读为为主,请问您是选择拆成子表,还是继续放一起?写出您这样选择的理由
拆带来的问题:连接消耗 + 存储拆分空间;不拆可能带来的问题:查询性能;
如果能容忍拆分带来的空间问题,拆的话最好和经常要查询的表的主键在物理结构上放置在一起(分区) 顺序IO,减少连接消耗,最后这是一个文本列再加上一个全文索引来尽量抵消连接消耗
如果能容忍不拆分带来的查询性能损失的话:上面的方案在某个极致条件下肯定会出现问题,那么不拆就是最好的选择














 2679
2679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









