









实例一 :一直fullGc导致的cpu使用率飙升
项目使用现象:
web项目,页面打开特别慢,反正就是慢。平常打开页面需要0.5s,现在需要3-5秒
进入服务器(4核8G内存)查看原因:
top发现:
但是cpu波动过大,使用平常在 10%左右,会突然飙升到100%、200%甚至300%
jmap -heap pid jvm内存已使用99.9%。jstat 发现发生了大量的fullgc.
所以即使存在OOM,也是响应很慢,不会停止提供服务
原因:
昨天领导让放宽缓存条件,最大8M修改为20M,所以
放宽缓存条件 --> 缓存增加 --> jvm内存耗用增加(99.9%) --> fullgc --> top时cpu飙升不稳定
解决:
收紧缓存条件,只能缓存8M以内的对象
插曲:收紧缓存条件,jvm内存消耗稳定在40%
再次top查看,发现cpu占用已经稳定,但是内存占用极不稳定,1%到40% 跳跃,奇怪,实在找不到原因,然后就问领导啥原因,领导看了一眼,骂了我一通:那是不同的线程。
因为top的结果排序是按照cpu的占比来排序的。
cpu使用率飙升一般定位步骤
一、引子
对于互联网公司,线上CPU飙升的问题很常见(例如某个活动开始,流量突然飙升时),按照本文的步骤排查,基本1分钟即可搞定!特此整理排查方法一篇,供大家参考讨论提高。
二、问题复现
线上系统突然运行缓慢,CPU飙升,甚至到100%,以及Full GC次数过多,接着就是各种报警:例如接口超时报警等。此时急需快速线上排查问题。
三、问题排查
不管什么问题,既然是CPU飙升,肯定是查一下耗CPU的线程(可能是代码里有死循环),然后看看GC。
3.1 核心排查步骤
1 获取最耗cpu的pid
top 结果的第一行就是假设为26906
2 pid为26906的进程下的所有线程占CPU的情况
top -Hp 26906
得到 27010 //top -Hp 26906中第一行的线程id(即占用cpu最多的线程id)
3 将线程id从十进制转化为16进制,这是因为 线程堆栈信息展示的都是十六进制,而我们要查堆栈信息
printf '%x\n' 27010 // 27010从10进制转化为16进制,得到6982
4 查询线程堆栈信息
jstack 26906 | grep 6982
结果:
"kafka-producer-network-thread | antispamProducer" #99 daemon prio=5 os_prio=0 tid=0x00007fa3b0862db0 nid=0x6982 runnable [0x00007fa356612000]
其中nid=0x6982就是线程号。 "kafka-producer-network-thread | antispamProducer"可以看到是kafaka线程
如果是“VM Thread”这就是虚拟机GC回收线程了
如果上面信息看不出来什么内容:需要获取更多信息
jstack 26906 | more // 查找线程号: 0x6982
获取如下内容:
"XNIO-2 task-45" #3354 prio=5 os_prio=0 cpu=34431284.32ms elapsed=313564.04s tid=0x00007f40fc00b000 nid=0x118e runnable [0x00007f40e4e4f000]
java.lang.Thread.State: RUNNABLE
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler.checkOrder(PartExactScratchHandler.java:179)
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler.compareBlockGroup(PartExactScratchHandler.java:60)
at com.tal.coding.platform.service.scratch.judge.handler.BaseOrderParamHandler.getComparePair(BaseOrderParamHandler.java:129)
at com.tal.coding.platform.service.scratch.judge.handler.BaseOrderParamHandler.check(BaseOrderParamHandler.java:82)
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler.doHandler(PartExactScratchHandler.java:34)
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler$$FastClassBySpringCGLIB$$5c23e861.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)结合代码定位问题:PartExactScratchHandler.checkOrder(PartExactScratchHandler.java:179),特殊场景下产生while死循环,一直未退出。
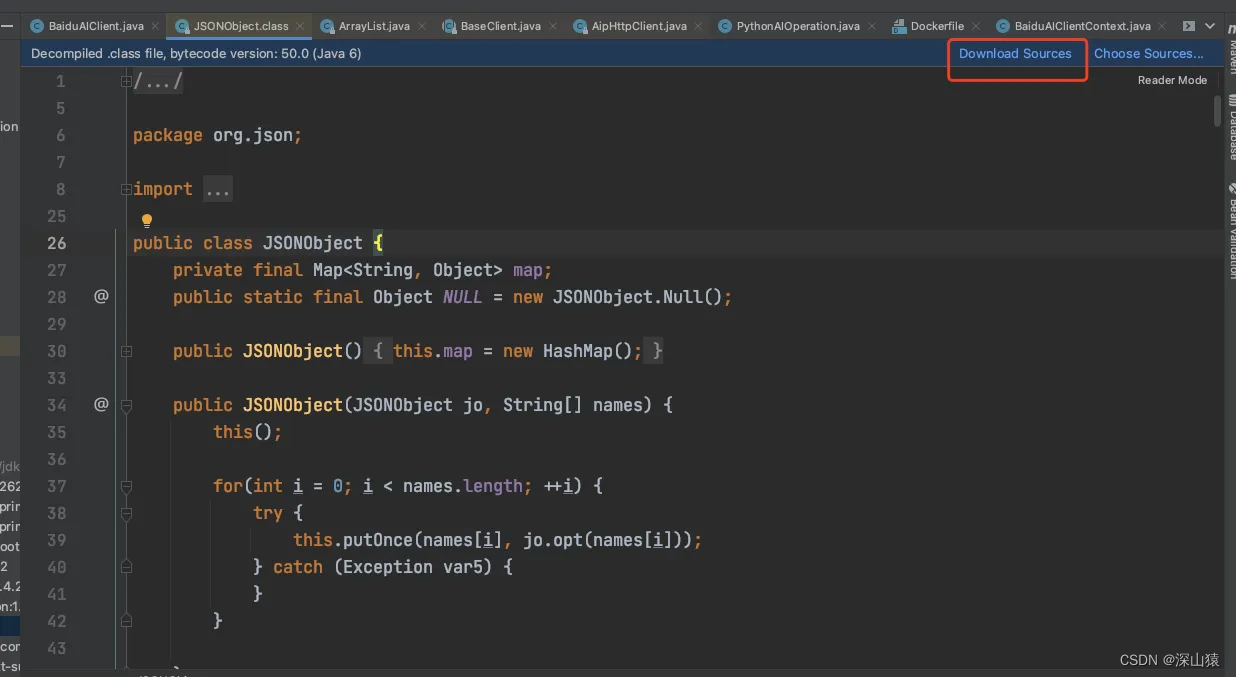
补充说明:有些时候即使拿到了堆栈信息,但是却发现跟展示的代码不一致,如堆栈中展示异常在at com.baidu.aip.client.BaseClient.requestServer(BaseClient.java:315),但是点击进去发现改行代码并不存在,BaseClient类只有152行,很奇怪。此时原因是这行代码是在jar包里面,直接点进去是编译后的代码,并非实际的源码!!点击如下图中的download source,然后重新进入方法即可。
5.执行“jstat -gcutil 进程号 统计间隔毫秒 统计次数(缺省代表一致统计)”,查看某进程GC持续变化情况,如果发现返回中FGC很大且一直增大-》确认Full GC!-》dump出内存,查找程序哪里内存溢出了。-》可明确看到gc的原因!
如: jstat -gcutil 26906 3000 2
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
0.00 22.69 92.78 78.57 97.16 93.47 24011 101.119 10 0.175 101.294
0.00 22.69 100.00 78.57 97.16 93.47 24011 101.119 10 0.175 101.294
3.2 原因分析
1.内存消耗过大,导致Full GC次数过多
执行步骤1-5:
多个线程的CPU都超过了100%,通过jstack命令可以看到这些线程主要是垃圾回收线程-》上一节步骤2
通过jstat命令监控GC情况,可以看到Full GC次数非常多,并且次数在不断增加。--》上一节步骤5
确定是Full GC,接下来找到具体原因:
生成大量的对象,导致内存溢出,此时可以通过eclipse的mat工具查看内存中有哪些对象比较多,飞机票:Eclipse Memory Analyzer(MAT),内存泄漏插件,安装使用一条龙;
内存占用不高,但是Full GC次数还是比较多,此时可能是代码中手动调用 System.gc()导致GC次数过多,这可以通过添加 -XX:+DisableExplicitGC来禁用JVM对显示GC的响应。
2.代码中有大量消耗CPU的操作,导致CPU过高,系统运行缓慢;
执行步骤1-4:在步骤4jstack,可直接定位到代码行。例如某些复杂算法,甚至算法BUG,无限循环递归等等。
3.由于锁使用不当,导致死锁。
执行步骤1-4: 如果有死锁,会直接提示。关键字:deadlock.步骤四,会打印出业务死锁的位置。
造成死锁的原因:最典型的就是2个线程互相等待对方持有的锁。
4.随机出现大量线程访问接口缓慢。
代码某个位置有阻塞性的操作,导致该功能调用整体比较耗时,但出现是比较随机的;平时消耗的CPU不多,而且占用的内存也不高。
思路:
首先找到该接口,通过压测工具不断加大访问力度,大量线程将阻塞于该阻塞点。
执行步骤1-4:
daemon prio= os_prio= tid=0x00007fd08d0fa000 nid=0x6403 waiting on condition [0x00007000033db000]
java.lang.Thread.State: TIMED_WAITING (sleeping)-》期限等待
at java.lang.Thread.sleep(Native Method)
at java.lang.Thread.sleep(Thread.java:)
at java.util.concurrent.TimeUnit.sleep(TimeUnit.java:)
at com.*.user.controller.UserController.detail(UserController.java:)-》业务代码阻塞点
如上图,找到业务代码阻塞点,这里线程进入了TIMED_WAITING(期限等待)状态。关于线程状态,不理解的飞机票:Thread类源码剖析
5.某个线程由于某种原因而进入WAITING状态,此时该功能整体不可用,但是无法复现;
执行步骤1-4:jstack多查询几次,每次间隔30秒,对比一直停留在WAITING状态的线程。
prio= os_prio= tid=0x00007f9de08c7000 nid=0x5603 waiting on condition [0x0000700001f89000]
java.lang.Thread.State: WAITING (parking) ->无期限等待
at sun.misc.Unsafe.park(Native Method)
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:)
at com.*.SyncTask.lambda$main$(SyncTask.java:)-》业务代码阻塞点
at com.*.SyncTask$$Lambda$/.run(Unknown Source)
at java.lang.Thread.run(Thread.java:)
参考:https://www.bbsmax.com/A/1O5E3vDnz7/
cpu频率很高的原因
一直在fgc
程序中有大量计算的操作,且开启了多线程
病毒与攻击
机器散热有问题
代码中因逻辑漏洞导致的死循环
cpu飙升实例二:异常导致的while条件一直满足
这两天做一个数据汇总处理的功能,即7张表(数据量在万-500万之间)汇总到一张表中。采取了分页存储的方式,但是遇到了一些问题。
现象:
1 jmap发现堆使用率达到将近100%
2 日志写的异常快速,需要不定时删除对应日志信息
3 记录处理刚开始快,后来越来越慢
最后结合日志中的异常定位问题代码:
private void addStatsStuAnswer(String tableName, String startTime, String endTime) {
int startNum = 0;
List<Exercise> exerciseList = null;
List<StatsStuAnswer> stuAnswerList = null;
long start = 0L, end = 0L;
int size = 0;
// 按页处理提交数据, 直到查询到的结果小于PAGE_SIZE
do {
try {
start = System.currentTimeMillis();
log.info(tableName + "从第" + startNum + "条记录开始处理");
// 1 查询exercise表中新增的记录
exerciseList = stuAnswerService.listExeByPage(tableName, startNum, PAGE_SIZE, startTime, endTime);
if (CollectionUtils.isEmpty(exerciseList)) {
return;
}
// 2 将答题实例转化为统计实例,增加习题、学生、班级等具体信息
// 假设这里抛出了异常。。。。那么该do while就是一个死循环
stuAnswerList = exerciseToStuAnswer(exerciseList, tableName);
// 3 执行幂等性的插入
saveStuAnswer(stuAnswerList);
end = System.currentTimeMillis();
log.info(tableName + "从" + startNum + "条记录开始,处理了" + exerciseList.size() + "条记录,耗时:{}秒", (end - start) / 1000);
startNum += PAGE_SIZE;;
} catch (Exception e) {
log.error(tableName + "从" + startNum + "条记录开始时,习题数据汇总出错,", e);
}
}while(exerciseList != null && PAGE_SIZE == exerciseList.size() );
}本质问题是:stuAnswerList = exerciseToStuAnswer(exerciseList, tableName);这行代码抛出异常会导致do while的死循环
解决方案:在try catch后面增加finally, startNum += PAGE_SIZE;放到finally中。
另外:现在的分页方式为
"select * from ${tableName} " +
"where modify_time <![CDATA[ >= ]]> #{startTime} " +
"and modify_time <![CDATA[ <= ]]>#{endTime} " +
"limit #{startNum}, #{pageSize}" 虽然modify_time上面有索引,但是到了实际场景中,增加modify_time字段时,会有百万条的记录modify_time值相同,此时越是向后面查询,数据的查询会越慢。
百万级别数据分页的正确方法 应该是每次查出最后一条的id 然后记录,下一次查询大于该id的记录1000条。
CPU飙升实例三:ifelse不完全导致的while死循环
现象:早晨一到公司发现了大量的告警,夜间不自动重启机器的cpu资源的使用率达到100%
定位与解决:
op 定位进程 结果:581

top -Hp 定位线程 下图可以看到多个线程占用很高的cpu,这里选取pid 4494进行分析

[work@bcy-cc-api-1 tmp]$ printf '%x\n' 4494
118e
[work@bcy-cc-api-1 tmp]$ jstack 581 | grep '118e'
"XNIO-2 task-45" #3354 prio=5 os_prio=0 cpu=34338641.37ms elapsed=313417.06s tid=0x00007f40fc00b000 nid=0x118e runnable [0x00007f40e4e4f000]
重点可以关注:cpu=34338641.37ms elapsed=313417.06s 说明线程一直没有释放
这个信息看的内容还不够具体:需要获取更多信息
jstack 581 | more // 输入 0x118e查找
获取到如下内容:
"XNIO-2 task-45" #3354 prio=5 os_prio=0 cpu=34431284.32ms elapsed=313564.04s tid=0x00007f40fc00b000 nid=0x118e runnable [0x00007f40e4e4f000]
java.lang.Thread.State: RUNNABLE
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler.checkOrder(PartExactScratchHandler.java:179)
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler.compareBlockGroup(PartExactScratchHandler.java:60)
at com.tal.coding.platform.service.scratch.judge.handler.BaseOrderParamHandler.getComparePair(BaseOrderParamHandler.java:129)
at com.tal.coding.platform.service.scratch.judge.handler.BaseOrderParamHandler.check(BaseOrderParamHandler.java:82)
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler.doHandler(PartExactScratchHandler.java:34)
at com.tal.coding.platform.service.scratch.judge.handler.PartExactScratchHandler$$FastClassBySpringCGLIB$$5c23e861.invoke(<generated>)
at org.springframework.cglib.proxy.MethodProxy.invoke(MethodProxy.java:218)结合代码定位问题:PartExactScratchHandler.checkOrder(PartExactScratchHandler.java:179),里边有while循环,if elseIf没有考虑到所有场景,部分场景导致了死循环。
CPU飙升实例四:大量线程因为等待http连接池导致的阻塞
问题梳理:
场景:
1 线程池并发进行外部rpc请求
2 rpc请求调用httpUtils,因为httpUtils设置了针对同一个url最多提供两个连接池
线程池无论内核多少,arthas监控都是只有两个线程处于runnable状态,别的都是waiting状态。
现象:
1 我们系统skywalking统计部分接口超时(60秒),外部反馈只有几十毫秒
2 存在大量request aborted异常
最终是因为http连接池中给的http连接太少,导致大量线程阻塞
CPU飙升实例五:容器场景,jar包中的while死循环导致的cpu升高
top获取cpu高的进程号 1
top -Hp获取cpu高的子进程号 10605
将10605转为16进制printf '%x\n' 10605 得到296d
然后 jstack 1 | more,手动搜索296d,得到的异常信息如下:
"pool-19-thread-1" #10545 prio=5 os_prio=0 cpu=136304584.53ms elapsed=136725.09s tid=0x00007f82fc254e60 nid=0x296d runnable [0x00007f78f7f05000]
java.lang.Thread.State: RUNNABLE
at java.lang.StackTraceElement.initStackTraceElements(java.base@15.0.1/Native Method)
at java.lang.StackTraceElement.of(java.base@15.0.1/StackTraceElement.java:526)
at java.lang.Throwable.getOurStackTrace(java.base@15.0.1/Throwable.java:840)
- locked <0x000000079096ff00> (a java.net.MalformedURLException)
at java.lang.Throwable.getStackTrace(java.base@15.0.1/Throwable.java:832)
at com.baidu.aip.util.ExceptionUtil.getStackTraceString(ExceptionUtil.java:6)
at com.baidu.aip.util.ExceptionUtil.buildErrorMessage(ExceptionUtil.java:21)
at com.baidu.aip.http.AipHttpClient.post(AipHttpClient.java:95)
at com.baidu.aip.client.BaseClient.requestServer(BaseClient.java:315)
at com.tal.editor.core.python.ai.BaiduAIClient.send(BaiduAIClient.java:114)
at com.tal.editor.core.python.ai.BaiduAIClientTask.leakyBucketWork(BaiduAIClientTask.java:87)
at com.tal.editor.core.python.ai.BaiduAIClientTask.call(BaiduAIClientTask.java:64)
at com.tal.editor.core.python.ai.BaiduAIClientTask.call(BaiduAIClientTask.java:20)
at java.util.concurrent.FutureTask.run(java.base@15.0.1/FutureTask.java:264)
at java.util.concurrent.ThreadPoolExecutor.runWorker(java.base@15.0.1/ThreadPoolExecutor.java:1130)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(java.base@15.0.1/ThreadPoolExecutor.java:630)
at java.lang.Thread.run(java.base@15.0.1/Thread.java:832)
但是
堆栈中展示异常在at com.baidu.aip.client.BaseClient.requestServer(BaseClient.java:315),但是点击进去发现改行代码并不存在,BaseClient类只有152行,很奇怪。此时原因是这行代码是在jar包里面,直接点进去是编译后的代码,并非实际的源码!!点击如下图中的download source,然后重新进入方法即可。
最终定位到是特定场景jar包中存在死循环,升级jar包后解决















 1038
1038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









