








SparkR安装
1、安装Spark(先安装JDK)
1.1 登陆Spark官网,点击Download Spark
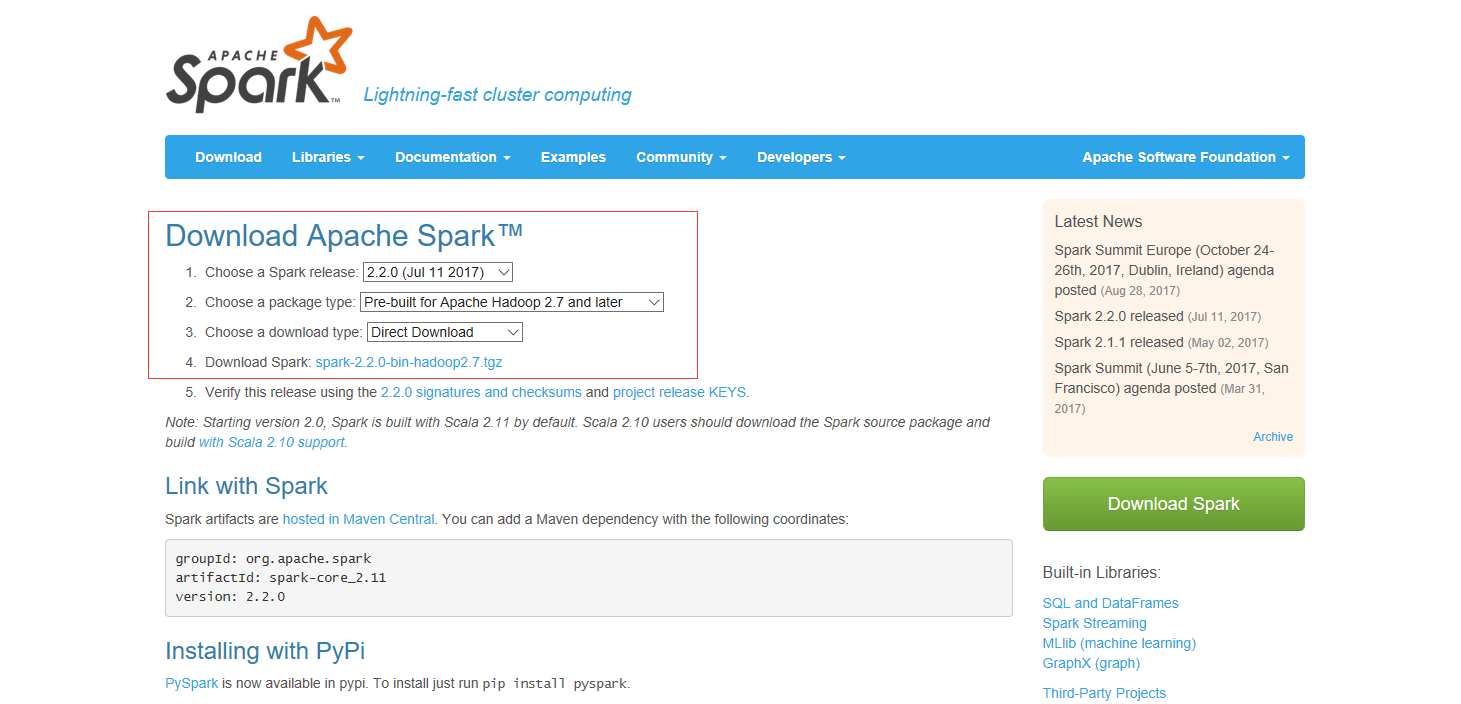
选择相应版本,将其解压缩至本地
1.2 安装对应版本的scala
1.3 将安装路径下R文件夹里的SparkR文件夹复制到R包安装目录下
以上Spark安装步骤会在另一篇博客中详细介绍,点击进入。
2、安装Hadoop(根据需要安装)
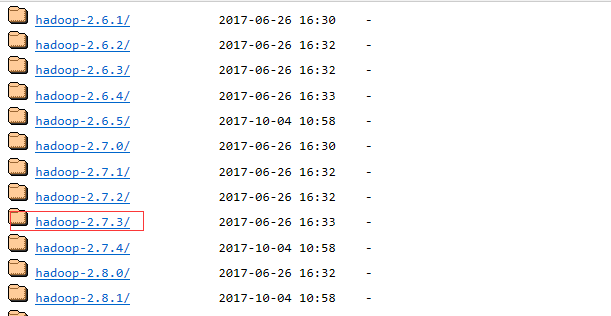
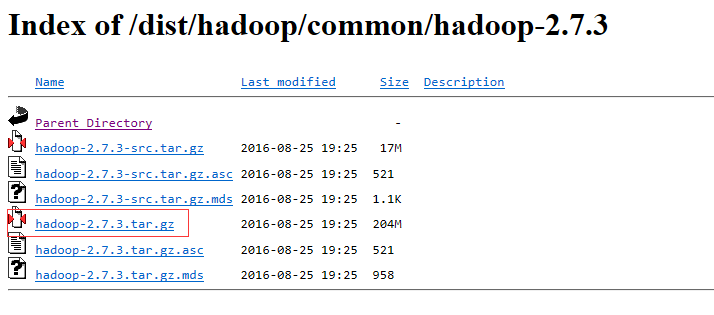
从Hadoop下载页面下载对应版本的Hadoop,解压至本地
3、配置环境变量
在path中添加R的安装路径,否则无法启动sparkR。
设置环境变量SPARK_HOME为第1步解压路径。
设置环境变量HADOOP_HOME为第2步解压路径。
4、环境测试
在%SPARK_HOME%\bin目录下,按住Shift右键选择在此处打开Powershell/cmd窗口,运行.\sparkR,一切顺利的话,会有“Welcome to SparkR!” ,否则,根据错误提示进行修改。
如果不在命令行中运行,此操作可以忽略
使用SparkR进行数据分析
1、概述
SparkR是R在Spark环境下的应用。在Spark 2.2.0中,SparkR提供了分布式框架,支持选择,过滤,聚合等操作。同时,可以通过MLlib实现机器学习。
2、SparkDataFrame
SparkDataFrame等效于R中的dataframe,但是有着更加丰富的优化。SparkDataFrames可以通过结构化数据集,Hive表,外部数据库或者R的dataframe等进行构造。
从RStudio进入SparkR
在RStudio中使用SparkR,安装并加载SparkR包即可。
从shell进入SparkR
在shell中使用SparkR,可在Spark安装目录下执行./bin/sparkR操作。
启动: SparkSession
在shell中使用SparkR,可在Spark安装目录下执行./bin/sparkR操作,然后执行如下命令:
sparkR.session()从RStudio启动
从RStudio启动SparkR,必须确保SPARK_HOME环境变量设置完毕(可以通过Sys.getenv命令检测),加载SparkR包,然后运行sparkR.session命令,具体如下:
if (nchar(Sys.getenv("SPARK_HOME")) < 1) {
Sys.setenv(SPARK_HOME = "/home/spark")
} #检测`SPARK_HOME`环境变量是否设置
library(SparkR, lib.loc = c(file.path(Sys.getenv("SPARK_HOME"), "R", "lib"))) #加载SparkR包,如果已复制SparkR到R包目录,lib.loc可省略
sparkR.session(master = "local[*]", sparkConfig = list(spark.driver.memory = "2g"))以下为从RStudio启动sparkR.session可使用的参数:
| 属性名称 | 属性组 | 相当于提交命令 |
|---|---|---|
| spark.master | 应用程序属性 | –master |
| spark.yarn.keytab | 应用程序属性 | –keytab |
| spark.yarn.principal | 应用程序属性 | –principal |
| spark.driver.memory | 应用程序属性 | –driver-memory |
| spark.driver.extraClassPath | 运行时环境 | –driver-class-path |
| spark.driver.extraJavaOptions | 运行时环境 | –driver-java-options |
| spark.driver.extraLibraryPath | 运行时环境 | –driver-library-path |
创建SparkDataFrames
使用可以从本地R数据框,Hive表或其他数据源构造SparkDataFrames。
从本地数据框
构造SparkDataFrame最简单的方法就是从R数据框生成。可以使用as.DataFrame或者createDataFrame创建SparkDataFrame。示例:使用R中faithful数据集构造SparkDataFrame:
df <- as.DataFrame(faithful)
head(df)
## eruptions waiting
##1 3.600 79
##2 1.800 54
##3 3.333 74从数据源构造
SparkR可以通过SparkDataFrame的接口支持各种数据源的操作。 最常用的创建方法是使用read.df函数。SparkR支持的格式包括JSON,CSV等,也可以通过包支持第三方数据源,例如Avro。这些包可以通过spark-submit的--packages 或者SparkSession的sparkPackages参数。
sparkR.session(sparkPackages = "com.databricks:spark-avro_2.11:3.0.0")从JSON文件读取
people <- read.df("./examples/src/main/resources/people.json", "json")
head(people)
## age name
##1 NA Michael
##2 30 Andy
##3 19 Justin
# SparkR自动判断JSON文件的结构
printSchema(people)
# root
# |-- age: long (nullable = true)
# |-- name: string (nullable = true)
# 使用read.json读取多个json文件
people <- read.json(c("./examples/src/main/resources/people.json", "./examples/src/main/resources/people2.json"))读取csv文件
df <- read.df(csvPath, "csv", header = "true", inferSchema = "true", na.strings = "NA")保存文件
write.df(people, path = "people.parquet", source = "parquet", mode = "overwrite")从Hive表创建
sparkR.session()
sql("CREATE TABLE IF NOT EXISTS src (key INT, value STRING)")
sql("LOAD DATA LOCAL INPATH 'examples/src/main/resources/kv1.txt' INTO TABLE src")
# 通过HiveQL查询创建
results <- sql("FROM src SELECT key, value")
head(results)
## key value
## 1 238 val_238
## 2 86 val_86
## 3 311 val_311SparkDataFrame操作
SparkDataFrames支持结构化数据的操作:
选择行,列
# 创建SparkDataFrame
df <- as.DataFrame(faithful)
# 获取SparkDataFrame基本信息
df
## SparkDataFrame[eruptions:double, waiting:double]
# 选择"eruptions"列
head(select(df, df$eruptions))
## eruptions
##1 3.600
##2 1.800
##3 3.333
# 通过列名选择
head(select(df, "eruptions"))
# 筛选SparkDataFrame中等待时间少于50分钟的字段
head(filter(df, df$waiting < 50))
## eruptions waiting
##1 1.750 47
##2 1.750 47
##3 1.867 48分组,聚合
# 使用 `n` 统计数量
head(summarize(groupBy(df, df$waiting), count = n(df$waiting)))
## waiting count
##1 70 4
##2 67 1
##3 69 2
# 对聚合结果排序
waiting_counts <- summarize(groupBy(df, df$waiting), count = n(df$waiting))
head(arrange(waiting_counts, desc(waiting_counts$count)))
## waiting count
##1 78 15
##2 83 14
##3 81 13列操作
# 增加单位为秒的列
df$waiting_secs <- df$waiting * 60
head(df)
## eruptions waiting waiting_secs
##1 3.600 79 4740
##2 1.800 54 3240
##3 3.333 74 4440应用用户自定义函数
在SparkR中,支持集中用户 自定义函数:
在大数据集中使用dapply 或 dapplyCollect运行自定义函数
dapply
schema <- structType(structField("eruptions", "double"), structField("waiting", "double"), structField("waiting_secs", "double"))
df1 <- dapply(df, function(x) { x <- cbind(x, x$waiting * 60) }, schema)
head(collect(df1))
## eruptions waiting waiting_secs
##1 3.600 79 4740
##2 1.800 54 3240
##3 3.333 74 4440
##4 2.283 62 3720
##5 4.533 85 5100
##6 2.883 55 3300dapplyCollect
类似于dapply,只是把dapply与collect进行了合并
ldf <- dapplyCollect(
df,
function(x) {
x <- cbind(x, "waiting_secs" = x$waiting * 60)
})
head(ldf, 3)
## eruptions waiting waiting_secs
##1 3.600 79 4740
##2 1.800 54 3240
##3 3.333 74 4440在大数据集中使用 gapply 或 gapplyCollect对列进行分组
gapply
schema <- structType(structField("waiting", "double"), structField("max_eruption", "double"))
result <- gapply(
df,
"waiting",
function(key, x) {
y <- data.frame(key, max(x$eruptions))
},
schema)
head(collect(arrange(result, "max_eruption", decreasing = TRUE)))
## waiting max_eruption
##1 64 5.100
##2 69 5.067
##3 71 5.033
##4 87 5.000
##5 63 4.933
##6 89 4.900gapplyCollect
result <- gapplyCollect(
df,
"waiting",
function(key, x) {
y <- data.frame(key, max(x$eruptions))
colnames(y) <- c("waiting", "max_eruption")
y
})
head(result[order(result$max_eruption, decreasing = TRUE), ])
## waiting max_eruption
##1 64 5.100
##2 69 5.067
##3 71 5.033
##4 87 5.000
##5 63 4.933
##6 89 4.900使用spark.lapply运行R本地函数,类似于R中的lapply
spark.lapply
families <- c("gaussian", "poisson")
train <- function(family) {
model <- glm(Sepal.Length ~ Sepal.Width + Species, iris, family = family)
summary(model)
}
model.summaries <- spark.lapply(families, train)
print(model.summaries)从SparkR运行SQL命令
people <- read.df("./examples/src/main/resources/people.json", "json")
# 将SparkDataFrame注册为临时视图
createOrReplaceTempView(people, "people")
teenagers <- sql("SELECT name FROM people WHERE age >= 13 AND age <= 19")
head(teenagers)
## name
##1 Justin3、机器学习
算法
SparkR目前支持以下机器学习算法:
分类
| 函数 | 作用 |
|---|---|
| spark.logit | 逻辑回归 |
| spark.mlp | 多层感知机及其BP算法(MLP) |
| spark.naiveBayes | 朴素贝叶斯 |
| spark.svmLinear | 线性支持向量机 |
回归
| 函数 | 作用 |
|---|---|
| spark.survreg | 叫做加速失效时间生存模型(AFT) |
| spark.glm / glm | 广义线性模型(GLM) |
| spark.isoreg | 保序回归 |
树
| 函数 | 作用 |
|---|---|
| spark.gbt | 梯度提升树 |
| spark.randomForest | 随机森林 |
聚类
| 函数 | 作用 |
|---|---|
| spark.bisectingKmeans | 二分k-means聚类 |
| spark.gaussianMixture | 高斯混合模型(GMM) |
| spark.kmeans | K-Means |
| spark.lda | 主题模型(LDA) |
协同过滤
| 函数 | 作用 |
|---|---|
| spark.als | 交替最小二乘法(ALS) |
频繁模式挖掘
| 函数 | 作用 |
|---|---|
| spark.fpGrowth | 关联分析算法(FP-growth) |
统计分析
| 函数 | 作用 |
|---|---|
| spark.kstest | Kolmogorov-Smirnov检验 |
SparkR使用MLlib训练模型, 可以用来统计分析和预测。可以使用write.ml/read.ml 来保存和加载模型。SparkR支持的操作符有‘~’, ‘.’, ‘:’, ‘+’和‘-‘。
模型稳健性
以下示例展示了SparkR保存和加载MLlib的方法。
training <- read.df("data/mllib/sample_multiclass_classification_data.txt", source = "libsvm")
# Fit a generalized linear model of family "gaussian" with spark.glm
df_list <- randomSplit(training, c(7,3), 2)
gaussianDF <- df_list[[1]]
gaussianTestDF <- df_list[[2]]
gaussianGLM <- spark.glm(gaussianDF, label ~ features, family = "gaussian")
# Save and then load a fitted MLlib model
modelPath <- tempfile(pattern = "ml", fileext = ".tmp")
write.ml(gaussianGLM, modelPath)
gaussianGLM2 <- read.ml(modelPath)
# Check model summary
summary(gaussianGLM2)
# Check model prediction
gaussianPredictions <- predict(gaussianGLM2, gaussianTestDF)
head(gaussianPredictions)
unlink(modelPath)Find full example code at “examples/src/main/r/ml/ml.R” in the Spark repo.
R和Spark数据类型的映射
| R | Spark |
|---|---|
| byte | byte |
| integer | integer |
| float | float |
| double | double |
| numeric | double |
| character | string |
| string | string |
| binary | binary |
| raw | binary |
| logical | boolean |
| POSIXct | timestamp |
| POSIXlt | timestamp |
| Date | date |
| array | array |
| list | array |
| env | map |
R函数命名冲突
| 覆盖函数 | 解决办法 |
|---|---|
| cov in package:stats | stats::cov(x, y = NULL, use = “everything”, method = c(“pearson”, “kendall”, “spearman”)) |
| filter in package:stats | stats::filter(x, filter, method = c(“convolution”, “recursive”), sides = 2, circular = FALSE, init) |
| sample in package:base | base::sample(x, size, replace = FALSE, prob = NULL) |















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









