









1、hive job并行度问题
开发同事问为什么他的hive job 排队 第一个完成后才会开始第二个 ,查询文档后找到这样一个参数
执行程序初始数
spark.dynamicAllocation.initialExecutors
执行程序下限数
spark.dynamicAllocation.minExecutors
这两个参数应该是需要同时配置 只配置第一个不生效
刚开始是1 配置了2 之后开发同事反馈第三个开始排队 ,确认配置的有效
2,hive运行报错
Logging initialized using configuration in jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/hive-common-2.1.1-cdh6.3.2.jar!/hive-log4j2.properties Async: false
之前解决别的错误的时候在hive里加了一行
export HIVE_AUX_JARS_PATH=/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/lib/hive/auxlib
虽然没解决问题但是忘记回滚了 删掉这行就行,应该是依赖冲突了
3 hive beeline 报错
Error: Error running query: java.lang.NoClassDefFoundError: Could not initialize class org.apache.atlas.hive.hook.HiveHook (state=,code=0)
- 需要把atlas-application.properties打入atlas-plugin-classloader-1.2.0.jar不然beeline连接hiveserver2的时候调用hook会找不到配置文件!注意要在同级目录打包!这里我也犯错了,不然atlas-application.properties不会在jar包里的第一级目录,还是会找不到!
zip -u atlas-plugin-classloader-1.2.0.jar atlas-application.properties - hiveserver2也要配置,搜hive-site,在hive-site.xml 的 HiveServer2 高级配置代码段(安全阀)下配置,想要beeline需要配置hive.reloadable.aux.jars.path参数。 这里应该在配置atlas的时候配置过了
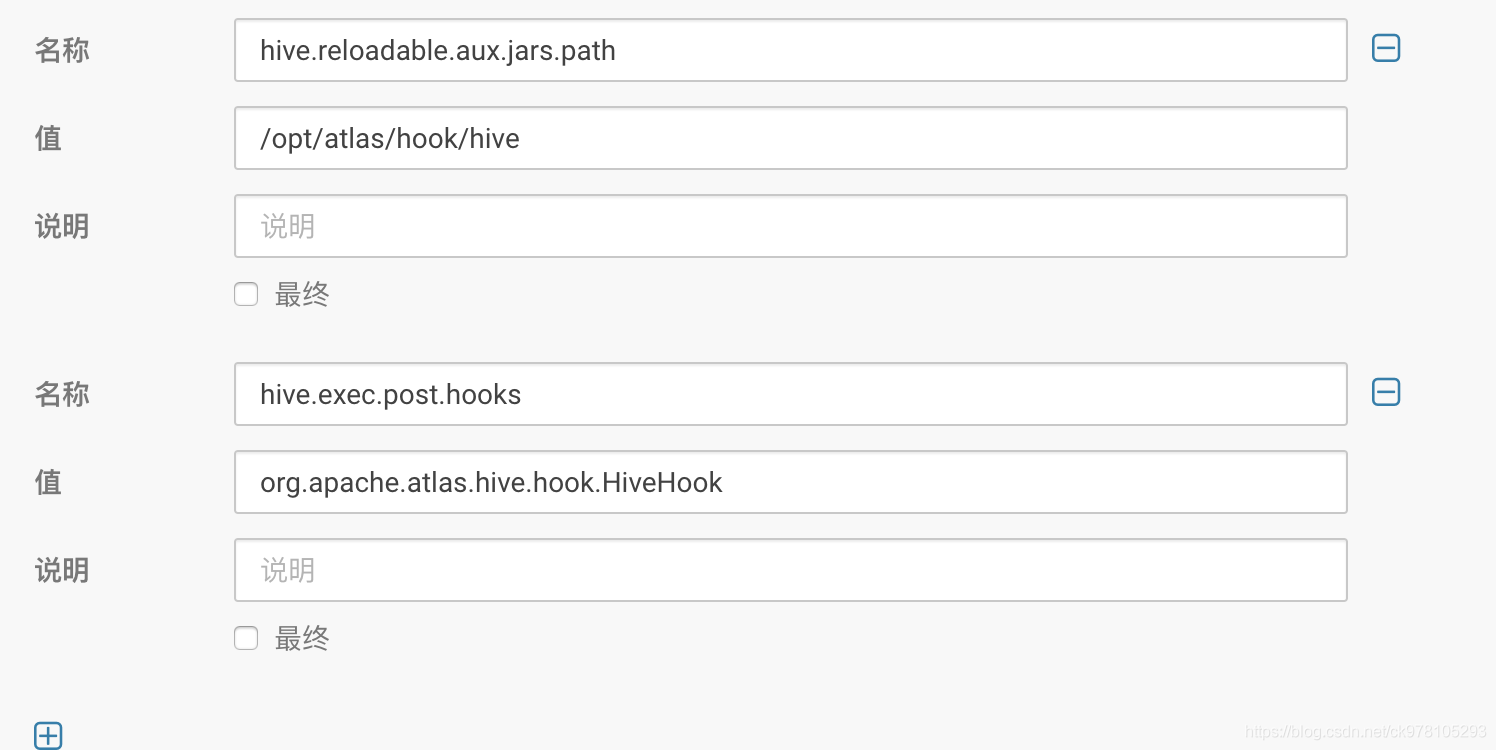
- 搜hiveserver,翻到最后一页,这里也添加上hook依赖的jar包

4 .hive 导入导出es数据报错、
FAILED: RuntimeException org.apache.hadoop.hive.ql.metadata.HiveException: Failed with exception Cannot detect ES version - typically this happens if the network/Elasticsearch cluster is not accessible or when targeting a WAN/Cloud instance without the proper setting 'es.nodes.wan.only'org.elasticsearch.hadoop.EsHadoopIllegalArgumentException: Cannot detect ES version - typically this happens if the network/Elasticsearch cluster is not accessible or when targeting a WAN/Cloud instance without the proper setting 'es.nodes.wan.only'
基本是网络或者服务问题 可以检查一下hive和es之间的网络 同时es的服务状态也需要检查
5,集群加入Kerberos之后 hive 查hbase报错
Caused by: org.apache.hadoop.hbase.ipc.RemoteWithExtrasException(org.apache.hadoop.hbase.security.AccessDeniedException): org.apache.hadoop.hbase.security.AccessDeniedException: Insufficient permissions (user=hive/hive@WC.COM, scope=bdm:ma_crm_customer_contact, params=[table=bdm:ma_crm_customer_contact],action=CREATE)
这是hive这个用户对hbase没权限导致的
grant 'hive','RWX','table'
授权单表
grant 'hive','RWCA'
授权所有,比如创建之类的权限
6、WARN spark.SparkConf: The configuration key 'spark.yarn.driver.memoryOverhead' has been deprecated as of Spark 2.3 and may be removed in the future. Please use the new key 'spark.driver.memoryOverhead' instead.
22/02/25 13:53:37 WARN spark.SparkConf: The configuration key 'spark.yarn.executor.memoryOverhead' has been deprecated as of Spark 2.3 and may be removed in the future. Please use the new key 'spark.executor.memoryOverhead' instead.
CDH上在
hive-site.xml 的 Hive 服务高级配置代码段(安全阀)
添加
spark.driver.memoryOverhead
这个配置就能覆盖本身的spark.yarn.driver.memoryOverhead这个配置

7、hive.exec.post.hooks Class not found: org.apache.atlas.hive.hook.HiveHook
主要是某个节点上的sqoop任务都会发生问题,检查该节点的hive的lib下的jar包 果然发现没有将atlas的包搬过去,
解决方法:
将/usr/local/src/atlas/apache-atlas-2.0.0/hook/hive所有jar包拷贝/opt/cloudera/parcels/CDH/lib/hive/lib目录下
8、UnresolvedAddressException: undefined
解析不了主机名 机器没配hosts 如果没找到 那可能是链路上的某台。。不用找别的问题 肯定是 ,仔细检查吧
9、远程访问时间和本地时间不一致
开发同事反馈任务的时间在各个节点上不一致 ,ssh扫了一下 确实有不一致的 但是登录上去确实是对的,远程访问时间和本地时间不一致
这是因为Local time和本地时间不一致
ll /etc/localtime
看一下localtime文件指向谁 我这指向了newyork
rm -f /etc/localtime
ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime解决
10、Hive数据拉取es报错
数据从hive拉取es Hive表的存储结构不能为 parquet 格式

解决方案:改成默认存储格式就行了
11、hiveOnSpak客户端RemoteSparkDriver超时

原因 集群资源使用率过高时可能会导致Hive On Spark查询失败-查询超时。 从hive on spark的架构看出超时的位置:

修改以下参数,重启集群
# 在Hive client和远程Spark driver通信过程中,随机生成密码的比特数。最好设置成8的倍数。
hive.spark.client.secret.bits
# 远程Spark drive用于处理RPC事件所用的最大线程数,默认是8。
hive.spark.client.rpc.threads
# Hive client和远程Spark driver通信最大的消息大小(单位:byte),默认是50MB。
hive.spark.client.rpc.max.size
# 远程Spark driver的通道日志级别,必须是DEBUG, ERROR, INFO, TRACE, WARN中的一个。
hive.spark.client.channel.log.level
# 用于身份验证的SASL机制的名称。
hive.spark.client.rpc.sasl.mechanisms
#生产集群设置的相应参数:
hive.spark.client.future.timeout=360s ``# Hive client请求Spark driver的超时时间,如果没有指定时间单位,默认就是秒。
hive.metastore.client.socket.timeout=360s ``# 客户端socket超时时间,默认20秒。
hive.spark.client.connect.timeout=360000ms ``# Spark driver连接Hive client的超时时间,如果没有指定时间单位,默认就是毫秒。
hive.spark.client.server.connect.timeout=360000ms ``# Hive client和远程Spark driver握手时的超时时间,这个会在两边都检查的,如果没有指定时间单位,默认就是毫秒。
hive.spark.job.monitor.timeout=180s ``# Job监控获取Spark作业状态的超时时间,如果没有指定时间单位,默认就是秒。
12、Failed to open new session: Couldn't create directory /tmp/
/tmp磁盘满了
13、Failed with exception java.io.IOException:java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:user.name%}
解决方法:
编辑 hive-site.xml 文件,添加下边的属性
<property>
<name>system:java.io.tmpdir</name>
<value>/home/hive/apache-hive-1.2.2-bin/iotmp</value>
<description/>
</property>
并修改属性
hive.exec.local.scratchdir
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hive/apache-hive-1.2.2-bin/tmp/${user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>问题就可以解决了。
14、hive脚本报错 unable to inherit permissions for file
hive的查询结果在在进行move操作时,需要进行文件权限的授权,多个文件的授权是并发进行的,hive中该源码是在一个线程池中执行的,该操作在多线程时线程同步有问题的该异常,这是hive的一个bug,目前截止目前的最新版本Apache Hive 2.1.1还没有修复该问题;
可以通过关闭hive的文件权限继承 来规避该问题。
在你的hql脚本里加一行
set hive.warehouse.subdir.inherit.perms=false;15、hue+hive报错 Bad status: 3 (PLAIN auth failed: Error validating LDAP user) (code THRIFTTRANSPORT): TTransportException('Bad status: 3 (PLAIN auth failed: Error validating LDAP user)',)
hue认证报错。除了网上常见的原因之外。如果你的hive同时集成了ldap和kerberos两种权限方式。需要在hue里添加一个高级参数

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









