







1、字典相关
1.1、删除字典里的某个键:
1.2、合并两个字典或者用一个字典更新另一个字典:

dict1={1:[1,11,111],2:[2,22,222]}
dict2={3:[3,33,333],4:[4,44,444]}
#方法一
dictMerged1=dict(dict1.items()+dict2.items())
#方法二
dictMerged2=dict(dict1, **dict2)
#方法二等同于
dictMerged=dict1.copy()
dictMerged.update(dict2)2、多线程、锁、全局锁、进程、python解释器
2.1、python的GIL
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
3、python2和python3的区别
3.1、range()的区别
python2返回列表,python3返回迭代器,节约内存
4、装饰器
4.1、一句话解释什么样的语言能够用装饰器?
https://www.runoob.com/w3cnote/python-func-decorators.html
函数可以作为参数传递的语言,可以使用装饰器
4.2、装饰器适用的场景:
插入日志、性能测试、事务处理、缓存、权限校验等场景
4.3、装饰器可以用于方法和类
4.4、装饰器可以带参数
5、python中__new__ 和__init__的区别
__init__ 是初始化方法,在创建对象之后调用进行初始化,它没有返回值。
__new__ 是创建对象时的方法,它有返回值,可以返回其父类
super(Person,cls).__new__(cls,name,age)出来的实例,也可以直接return object.__new(cls)出来的实例,注意父类可以有除cls之外的参数,而object只有cls参数,其中cls代表当前类。注意:如果类A的__new__中的cls换成了其它类的名字,那么就不会自动调用类A的__init__方法。
7、各种随机数生成方法
指定区间内的随机整数:random.randint(a,b),生成区间内的整数
n个随机小数:习惯用numpy库,利用np.random.randn(5)生成5个随机小数
1个0-1随机小数:random.random(),括号中不传参
8、python中可变数据类型和不可变数据类型
不可变数据类型:数值型、字符串型string和元组tuple。特点为:对于具有相同的值的不同对象,在内存中地址是一样的。
可变数据类型:列表list和字典dict。特点为:对于具有相同值的不同对象,或值改变了的对象,在内存中地址是不一样的。
主要是和引用计数有关,不可变数据类型涉及到相同对象的引用计数,而不可变数据类型不涉及引用计数。
9、用lambda创建函数
sum = lambda a,b:a*b
print(sum(5,4)) ### 等于20
10、对字典进行排序
针对字典里的值进行排序:sorted(result.items(),key=lambda x:float(x[1][3]),reverse=True)
针对字典里的健进行排序:sorted(result.items(),key=lambda x:x[0],reverse=True)
11、filter过滤方法的使用
a=[1,2,3,4,5,6,7]
def fn(a):
return a%2==1
newlist = filter(fn,a)12、初始化一个元组类型对象
a=(1,)
13、list与numpy的array之间的转换
可以使用numpy里的array的方法
14、zip函数的用法:
对于元组和列表:
a=(1,2)
b=(3,4)
res=[i for i in zip(a,b)]
得到都是list(元组):[(1,3),(2,4)]对于字符串:
a="ab"
b="xyz"
res=[i for i in zip(a,b)]
得到list[元组]:[('a','x'),('b','y')]15、两个list相加等于extend
16、提高python运行效率的方法
使用生成器,因为可以节约大量内存
循环代码优化,避免过多重复代码的执行
核心模块用Cython PyPy等,提高效率
多进程、多线程、协程
多个if elif条件判断,可以把最有可能先发生的条件放到前面写,这样可以减少程序判断的次数,提高效率
17、python创建单例模式
class Singleton(object):
__instance = None
def __new__(cls, age,name):
# 如果类属性__instance的值为None。
# 那么就创建一个对象,并且赋值为这个对象的引用,保证下次调用这个方法时
# 能够知道之前已经创建过对象了,这样就保证了只有1个对象
if not cls.__instance:
cls.__instance = object.__new__(cls)
return cls.__instance
a = Singleton(18,"dongGe")
b = Singleton(9,"dongGe")
a.age = 19 #给a指向的对象添加一个属性
print(b.age)
# 输出
1918、保留n位小数
round(0.333,2) = 0.33
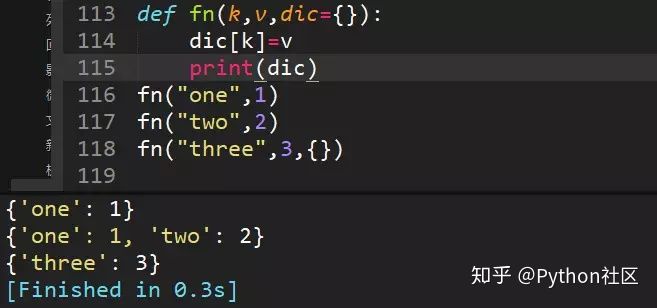
19、python中字典作为函数参数的情况
fn("one",1)直接将键值对传给字典;
fn("two",2)因为字典在内存中是可变数据类型,所以指向同一个地址,传了新的额参数后,会相当于给字典增加键值对
fn("three",3,{})因为传了一个新字典,所以不再是原先默认参数的字典
20、python中any()和all()判断为假的区别,以及python中的假指的是哪些
any():只要迭代器中有一个元素为真就为真
all():迭代器中所有的判断项返回都是真,结果才为真
python中什么元素为假?
答案:(0,空字符串,空列表、空字典、空元组、None, False)
21、可变对象和不可变对象
可变对象是指,一个对象在不改变其所指向的地址的前提下,可以修改其所指向的地址中的值;
不可变对象是指,一个对象所指向的地址上值是不能修改的,如果你修改了这个对象的值,那么它指向的地址就改变了,相当于你把这个对象指向的值复制出来一份,然后做了修改后存到另一个地址上了,但是可变对象就不会做这样的动作,而是直接在对象所指的地址上把值给改变了,而这个对象依然指向这个地址。
22、浅拷贝和深拷贝
https://www.cnblogs.com/xiaxiaoxu/p/9742452.html
深拷贝和浅拷贝需要注意的地方就是可变元素的拷贝:
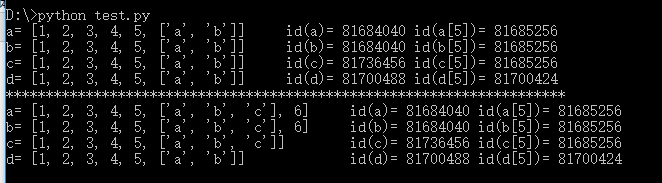
在浅拷贝时,拷贝出来的新对象的地址和原对象是不一样的,但是新对象里面的可变元素(如列表)的地址和原对象里的可变元素的地址是相同的,也就是说浅拷贝它拷贝的是浅层次的数据结构(不可变元素),对象里的可变元素作为深层次的数据结构并没有被拷贝到新地址里面去,而是和原对象里的可变元素指向同一个地址,所以在新对象或原对象里对这个可变元素做修改时,两个对象是同时改变的,但是深拷贝不会这样,这个是浅拷贝相对于深拷贝最根本的区别。
#encoding=utf-8
import copy
a=[1,2,3,4,5,['a','b']]
#原始对象
b=a#赋值,传对象的引用
c=copy.copy(a)#对象拷贝,浅拷贝
d=copy.deepcopy(a)#对象拷贝,深拷贝
print "a=",a," id(a)=",id(a),"id(a[5])=",id(a[5])
print "b=",b," id(b)=",id(b),"id(b[5])=",id(b[5])
print "c=",c," id(c)=",id(c),"id(c[5])=",id(c[5])
print "d=",d," id(d)=",id(d),"id(d[5])=",id(d[5])
print "*"*70
a.append(6)#修改对象a
a[5].append('c')#修改对象a中的['a','b']数组对象
print "a=",a," id(a)=",id(a),"id(a[5])=",id(a[5])
print "b=",b," id(b)=",id(b),"id(b[5])=",id(b[5])
print "c=",c," id(c)=",id(c),"id(c[5])=",id(c[5])
print "d=",d," id(d)=",id(d),"id(d[5])=",id(d[5])结果:
23、几种魔法方法:__init__、__new__、__str__、__del__
__init__:对象初始化方法
__new__:创建对象时候执行的方法,单列模式会用到
__str__:当使用print输出对象的时候,只要自己定义了__str__(self)方法,那么就会打印从在这个方法中return的数据
__del__:删除对象执行的方法
24、将列表推导式转为生成器
[i for i in range(3)]改成生成器:
a=(i for i in range(3))
只需要将中括号改为小括号。
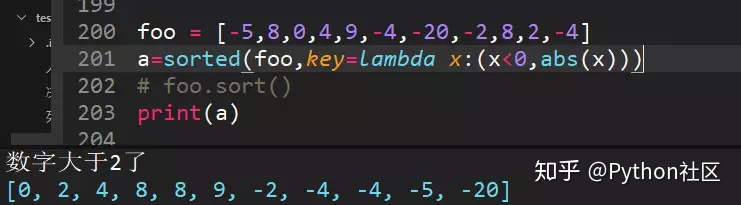
25、sorted排序可以结合lambda表达式进行
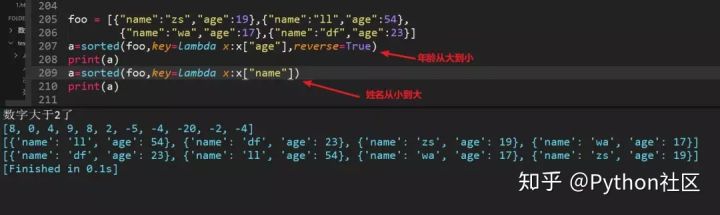
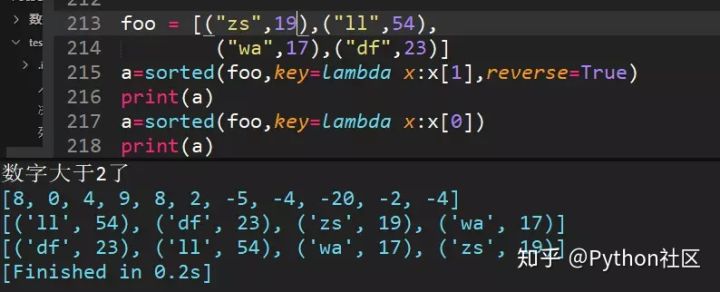
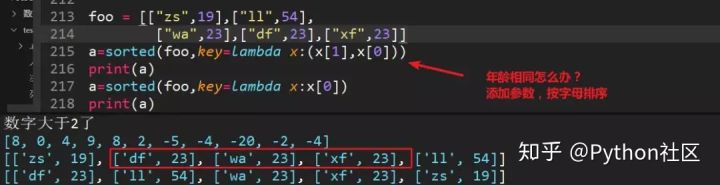
26、列表嵌套字典、嵌套元组、嵌套列表时使用sorted排序:
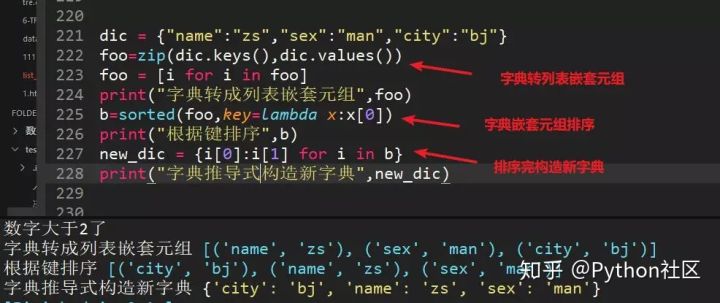
28、对字典排序(排序结果仍为字典,涉及到列表嵌套元组到字典的转换,及字典到列表嵌套元组的转换)
使用zip将字典转为列表嵌套元组,并使用sorted排序
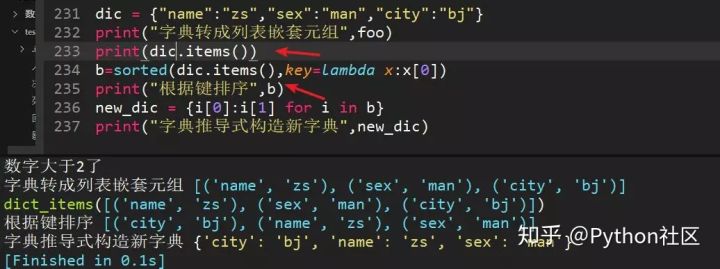
直接使用sorted对字典排序
29、列表推导式的形式、生成器的形式、字典推导式的形式
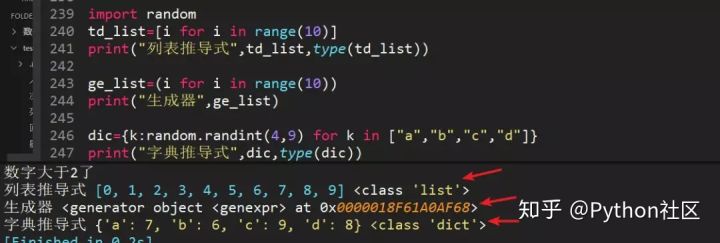
30、python传参数是传值还是传址
Python中函数参数是引用传递(注意不是值传递)。对于不可变类型(数值型、字符串、元组),因变量不能修改,所以运算不会影响到变量自身;而对于可变类型(列表字典)来说,函数体运算可能会更改传入的参数变量。
31、求两个列表(转成set)的交集intersection、差集difference、并集union
32、生成随机数:随机小数,某区间的一个整数
random.random()、random.randint(1,100)
33、lambda结合map处理可迭代对象(比如列表)

34、http请求中get和post的区别
1、GET请求是通过URL直接请求数据,数据信息可以在URL中直接看到,比如浏览器访问;而POST请求是放在请求头中的,我们是无法直接看到的;
2、GET提交有数据大小的限制,一般是不超过1024个字节,而这种说法也不完全准确,HTTP协议并没有设定URL字节长度的上限,而是浏览器做了些处理,所以长度依据浏览器的不同有所不同;POST请求在HTTP协议中也没有做说明,一般来说是没有设置限制的,但是实际上浏览器也有默认值。总体来说,少量的数据使用GET,大量的数据使用POST。
3、GET请求因为数据参数是暴露在URL中的,所以安全性比较低,比如密码是不能暴露的,就不能使用GET请求;POST请求中,请求参数信息是放在请求头的,所以安全性较高,可以使用。在实际中,涉及到登录操作的时候,尽量使用HTTPS请求,安全性更好。
35、@classmethod和@staticmethod装饰器的区别
https://www.jianshu.com/p/bcb294e16ce2
https://blog.csdn.net/u010571844/article/details/50728991
-
类的普通方法,地一个参数需要self参数表示自身。
-
@staticmethod不需要表示自身对象的self和自身类的cls参数,就跟使用函数一样。
-
@classmethod也不需要self参数,但第一个参数需要是表示自身类的cls参数。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









