









1、FP-growth算法可以高效地发现频繁项集,但不能用于发现关联规则。
2、FP-growth发现频繁项集的基本过程:
1)构建FP树
2)从FP树种挖掘频繁项集。
3、FP树有其数据结构,一般用该数据结构对数据集进行编码。
4、一棵FP树看上去与计算机科学中的其他树结构相似,但是它通过链接(link)来连接相似元素,被连起来的元素项可以看成一个链表:
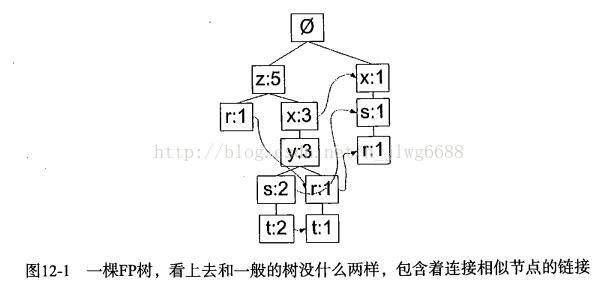
一个元素项可以在一棵FP树种出现多次,FP树会存储项集的出现频率,而每个项集会以路径的方式存储在树中。存在相似元素的集合会共享树的一部分,只有当集合之间完全不同时,树才会分叉。树节点上给出集合中的单个元素及其在序列中的出现次数,路径会给出该序列的出现次数。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









