







1、决策树用做分类和回归
问题:
决策树如何做回归?
2、决策树的生成算法有哪几种
id3、c4.5、CART
3、决策树的结构:
内部节点表示特征,叶节点表示类。
决策树的内部节点的分支是多分支(一个内部节点可以有多个子节点)。
决策树每一层的特征(属性)都不相同。
4、决策树的特征选择:熵、条件熵、互信息、信息增益
决策树的特征选择的简单描述:如果一个特征具有更好的分类能力,那么依此特征将数据集分割成子集,使得子集在当前条件下有最好的分类,那么就应该选择这个特征,也就是说使用该特征划分子集后,各个子集内类别的不确定性更低(就是说各个子集内的样本几乎都属于1个类别)。
熵的公式:
条件熵的公式: ,即X给定的条件下Y的条件概率分布的熵对X的的数学期望,即条件熵的均值。
,即X给定的条件下Y的条件概率分布的熵对X的的数学期望,即条件熵的均值。
信息增益就是互信息。
根据信息增益选择特征的方法是:对训练数据集D,计算每个特征的信息增益,并比较它们的大小,选择信息增益最大的特征。即给定条件下条件熵最小(也就是给定条件下类别纯度最高)。
在实际应用中,经验熵、经验条件熵、信息增益的计算方法:
给定数据集D,类别K,某个特征A:
经验熵:![]()
经验条件熵: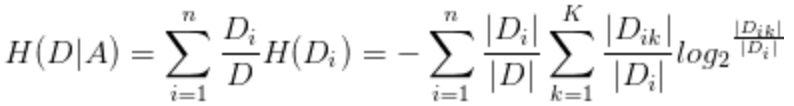
信息增益:相减。
5、信息增益与信息增益比:
信息增益比的公式: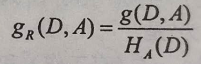 ,其中
,其中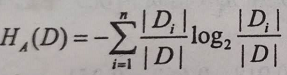 是特征A的值的熵。
是特征A的值的熵。
信息增益会倾向于选择特征的取值较多的特征,比如以物品的id为特征,一个物品对应一个id,则id3算法倾向于将每个数据自成一类,以id为特征的条件信息熵趋向于0,则信息增益最大,但是以id为特征没有意义,所以需要对其进行惩罚,惩罚系数就是以id为特征的情况下,id的个数为熵,将该熵作为分母,也就是说特征的取值个数越多,熵越大,对以该特征为条件得到的信息增益被惩罚的越厉害。
信息增益比也有缺点,倾向于特征取值较少的特征。
所以实际应用中,先用特征增益选取特征,然后再从其中使用信息增益比选取特征。
参考:https://www.zhihu.com/question/22928442/answer/117189907
6、ID3与C4.5的优缺点及区别:
参考:https://www.zhihu.com/question/27205203?sort=created
处理问题的目标相同:
C4.5和ID3都只能做分类。
样本数据差异:
ID3只能对离散变量进行处理,C4.5也可以处理连续变量(使用二分法,先对特征进行排序,然后取两个数的中间值为阈值进行二分切分)。
ID3对缺失值敏感,C4.5可以处理缺失值。
样本特征上的差异:
7、可以使用ID3或者C4.5进行特征选择。
8、决策树剪枝的原理及公式:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 324
324











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









