







原创文章,转载请务必将下面这段话置于文章开头处。
本文转发自技术世界,原文链接 http://www.jasongj.com/spark/committer/
本文所述内容均基于 2018年9月17日 Spark 最新 Release 2.3.1 版本,以及 hadoop-2.6.0-cdh-5.4.4
概述
Spark 输出数据到 HDFS 时,需要解决如下问题:
- 由于多个 Task 同时写数据到 HDFS,如何保证要么所有 Task 写的所有文件要么同时对外可见,要么同时对外不可见,即保证数据一致性
- 同一 Task 可能因为 Speculation 而存在两个完全相同的 Task 实例写相同的数据到 HDFS中,如何保证只有一个 commit 成功
- 对于大 Job(如具有几万甚至几十万 Task),如何高效管理所有文件
commit 原理
本文通过 Local mode 执行如下 Spark 程序详解 commit 原理
sparkContext.textFile("/json/input.zstd")
.map(_.split(","))
.saveAsTextFile("/jason/test/tmp")
在详述 commit 原理前,需要说明几个述语
- Task,即某个 Application 的某个 Job 内的某个 Stage 的一个 Task
- TaskAttempt,Task 每次执行都视为一个 TaskAttempt。对于同一个 Task,可能同时存在多个 TaskAttemp
- Application Attempt,即 Application 的一次执行
在本文中,会使用如下缩写
- ${output.dir.root} 即输出目录根路径
- ${appAttempt} 即 Application Attempt ID,为整型,从 0 开始
- ${taskAttemp} 即 Task Attetmp ID,为整型,从 0 开始
检查 Job 输出目录
在启动 Job 之前,Driver 首先通过 FileOutputFormat 的 checkOutputSpecs 方法检查输出目录是否已经存在。若已存在,则直接抛出 FileAlreadyExistsException
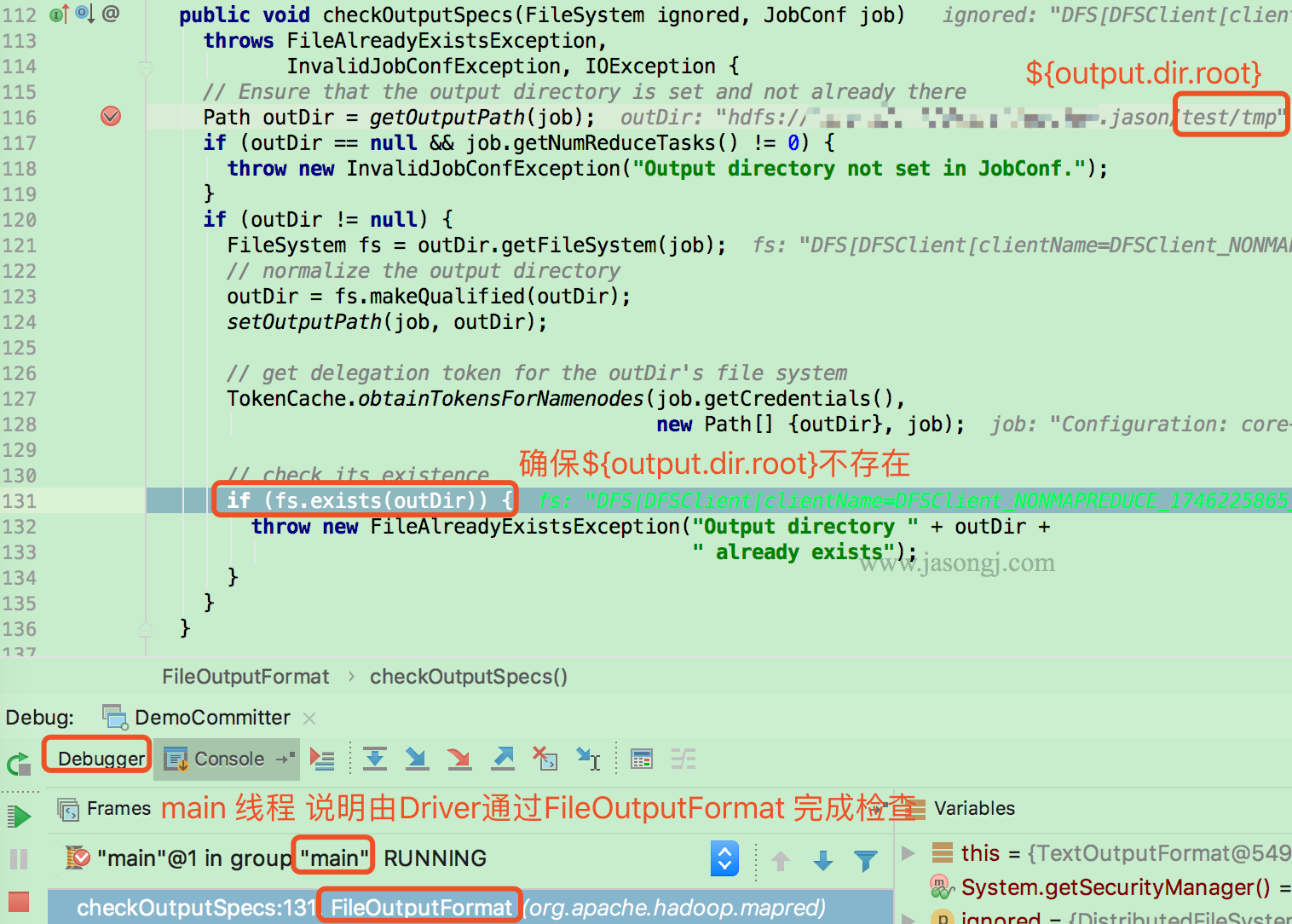
Driver执行setupJob
Job 开始前,由 Driver(本例使用 local mode,因此由 main 线程执行)调用 FileOuputCommitter.setupJob 创建 Application Attempt 目录,即 o u t p u t . d i r . r o o t / t e m
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









