









文章首发于微信公众号《有三AI》
【AI白身境】入行AI需要什么数学基础:左手矩阵论,右手微积分
今天是新专栏《AI白身境》的第九篇,所谓白身,就是什么都不会,还没有进入角色。
咱们这个系列接近尾声了,今天来讲一个非常重要的话题,也是很多的小伙伴们关心的问题。要从事AI行业,吃这碗饭,至少应该先储备一些什么样的数学基础再开始。
下面从线性代数,概率论与统计学,微积分和最优化3个方向说起,配合简单案例,希望给大家做一个抛砖引玉,看完之后能够真正花时间去系统性补全各个方向的知识,笔者也还在努力。
作者 | 言有三
编辑 | 言有三
01 线性代数
1.1 向量
什么是数学?顾名思义,一门研究“数”的学问。学术点说,线性代数是一个数学分支,来源于希腊语μαθηματικός(mathematikós),意思是“学问的基础”。
数学不好,就不要谈学问了,只能算知识(自己瞎加的,欢迎喷)。
按照维基百科定义:数学是利用符号语言研究数量、结构、变化以及空间等概念的一门学科,从某种角度看属于形式科学的一种。所以一看见数学,我们就想起符号,方程式,简单点比如这个。

复杂的比如这个
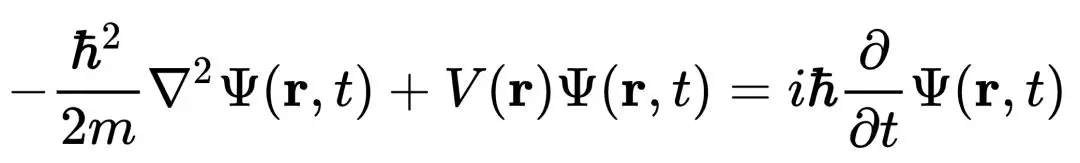
代数是数学的一个分支,它的研究对象是向量,涵盖线、面和子空间,起源于对二维和三维直角坐标系的研究。
我们都知道欧式空间,任何一个向量(x,y,z)可以由三个方向的基组成
(x,y,z) = x(1,0,0)+y(0,1,0)+z(0,0,1)
它的维度是3,拓展至n就成为n维空间,这N维,相互是独立的,也就是任何一个都不能由其他的几维生成,这叫线性无关,很重要。
2.2 线性回归问题
用向量表示问题有什么用呢?
假如基友今天约你去吃饭,没有说好谁买单,而根据之前的惯例你们从来不AA,今天你刚交了房租,没钱了,那么该不该去呢?我们可以先回归一下他主动买单的概率,先看一下和哪些变量有关,把它串成向量。
X=(刚发工资,刚交女朋友,刚分手,要离开北京,有事要我帮忙,无聊了,过生日,就是想请我吃饭,炒比特币赚了,炒比特币亏了,想蹭饭吃),共11维,结果用Y表示
Y=1,表示朋友付款,Y=-1,表示不付款
好,我们再来分析下:
和Y=1正相关的维度: 要离开北京,有事要我帮忙,过生日,就是想请我吃饭,炒比特币赚了
和Y=-1正相关的维度:想蹭饭吃
暂时关系不明朗的维度:刚发工资,刚交女朋友,刚分手,无聊了,炒比特币亏了
好,拿出纸笔,今天是2019年1月22日,据我所知,这货就是一个典型的死宅摩羯工作狂
刚发工资=0,时候没到
刚交女朋友=0,不可能
刚分手=0,没得选
要离开北京=0,不像
有事要我帮忙=0,我能帮上什么忙
无聊了=1,估计是
过生日=0,不对
就是想请我吃饭=0,不可能
炒比特币赚了=?,不知道
炒比特币亏了=?,不知道
想蹭饭吃=?,不知道
这下麻烦了,有这么多选项未知,假如我们用一个权重矩阵来分析,即y=WX,W是行向量,X是列向量

X1到xn就是前面那些维度。现在等于

假如我们不学习参数,令所有的wi与y=1正相关的系数为1,与y=-1正相关为-1,关系不明的随机置为0.001和-0.001,那么就有下面的式子
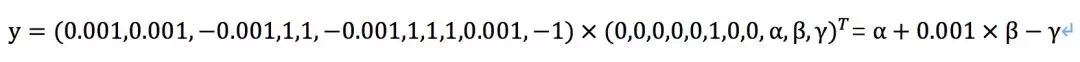
还是3个未知数,问题并没有得到解决。

不过我们还是可以得到一些东西:
-
我们的模型还没有得到训练,现在的权重是手工设定的,这是不合理的,应该先抓比如1万个样本来填一下报告,把X和Y都填上。当然,要保证准确性,不能在报告中填了说自己会请客(y=1),实际吃起来就呵呵呵?。这样就是标签打错了,肯定学不到东西。
-
从X来看,这个朋友还是可以的,与y=1正相关的变量更多,但是,未必!因为现在X的维度太低了,比如这个朋友是不是本来就是小气鬼或者本来就喜欢请人吃饭,比如是来我家附近吃还是他家附近吃,比如他吃饭带不带女孩等等。
-
上面提到了一些随机性,比如权重W的随机性,0.001或者-0.001,X本身的噪声α,β,γ。
是不是很复杂,现实问题本来就很复杂嘛。不过如果你没有经济问题,那就可以简单点,不管这个模型,只问你今天想不想吃饭,是就去,不想吃就不去。
线性代数就说这么多,后面想好好学,一定要好好修行线性代数和矩阵分析,咱们以后再说,书单如下。


以下是一些关键词,如果都熟练了解了第一阶段也就OK了。
标量,向量,特征向量,张量,点积,叉积,线性回归,矩阵,秩,线性无关与线性相关,范数, 奇异值分解,行列式,主成分分析,欧氏空间,希尔伯特空间。
02 概率论与统计学
2.1 概率论
概率大家都知道吧,研究的是随机性事件。大家应该都曾经饱受贝叶斯公式的折磨。
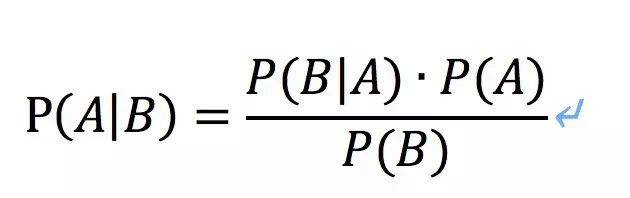
概率论中有以下几个概念,还是以之前的吃饭问题,朋友主动叫我吃饭为事件X,也叫观测数据,他请客了事件为Y,有以下几个概率,其中P(A|B)是指在事件B发生的情况下事件A发生的概率。
(1) X的先验概率,即朋友主动喊我吃饭的概率p(X),与Y无关。
(2) Y的先验概率p(Y):即单纯的统计以往所有吃饭时朋友请客的概率p(Y),与X无关。
(3) 后验概率p(Y|X):就是给出观测数据X所得到的条件概率,即朋友喊我吃饭,并且会请客的概率。
anyway,饭我们吃完了,现在回家,结果未来的女朋友打来电话问去干嘛了,气氛有点严肃,原来是吹牛皮过程中没有看微信漏掉了很多信息。只好说去应酬了,妹子不满意问你还有钱吃饭,谁请客。我说不吃白不吃啊,朋友请。
妹子又问,谁主动提出吃饭的!
正好,那不就是要算后验概率p(X|Y)吗?也就是饭吃了,谁提议的。
于是故作聪明让妹子猜,还给了一个提示可以用贝叶斯公式,并且已知p(Y)=0.2,p(X)=0.8,再加上上面算出来的p(Y|X)
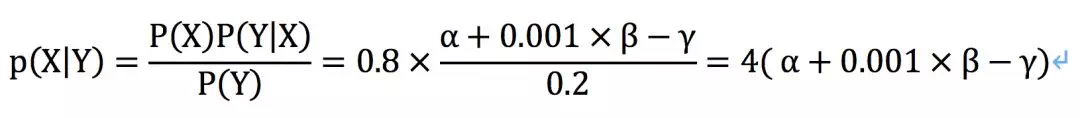
好了又回到了这个问题,3个未知变量。
不过没关系,我们可以先用它们的数学期望来替换掉,数学期望就是一个平均统计。
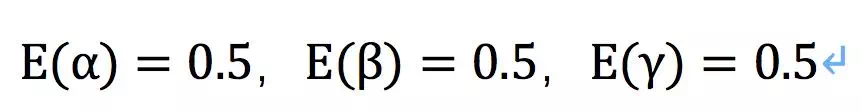
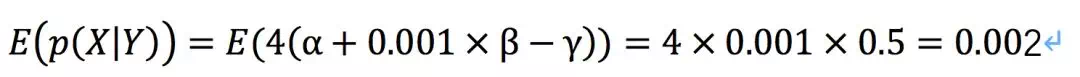
这说明什么?说明这一次吃饭,是朋友先动的嘴的概率p(X|Y)=0.002,那么今天99.8%是自己跑出去蹭吃吹牛皮了。
接下来的问题就是搓衣板是跪还是不跪,贝叶斯公式解决不了。
事情结束后,要想好好搞下去,肯定是要学好概率论和统计学习的。

同样,有一些关键词要掌握。
不确定性,随机变量,大数定律,联合分布,边缘分布,条件概率,贝叶斯公式,概率密度,墒与交叉墒,期望,最大似然估计,正态分布/高斯分布,伯努利分布,泊松分布,概率论与统计推断,马尔可夫链,判别模型,生成模型。
有意思的是:概率论还有一些东西是有点违背认知的,比如生日悖论。
一个班上如果有23个人,那么至少有两个人的生日是在同一天的概率要大于50%,对于60或者更多的人,这种概率要大于99%。大家都是上过学的少年,你在班上遇到过同一天生日的吗?
2.2 传统机器学习算法基础
传统机器学习算法本来不应该放在这里说,但是因为其中有一部分算法用到了概率论,所以也提一句。
有很多人在知乎上问,搞深度学习还需要传统机器学习基础吗?当然要!且不说这个传统机器学习算法仍然在大量使用,光是因为它经典,就值得学习一下,依旧推荐一本书。

机器学习完成的任务就是一个模式识别任务,机器学习和模式识别这两个概念实际上等价,只是历史原因说法不同。
一个模式识别任务就是类似于识别这个图是不是猫,这封邮件是不是垃圾邮件,这个人脸是不是你本人之类的高级的任务。
传统的机器学习算法有两大模型,一个是判别模型,一个是生成模型,我们以前讲过,大家可以去看。
传统机器学习算法就不展开了,太多。
03 微积分与最优化
3.1 导数
机器学习就是要学出一个模型,得到参数嘛,本质上就是优化一个数学方程,而且通常是离散的问题,这个时候大杀器就是微积分了。
微积分是什么,根据维基百科:
微积分学(Calculus,拉丁语意为计数用的小石头)曾经指无穷小的计算,就是一门研究变化的学问,更学术点说就是研究函数的局部变化率,如下。
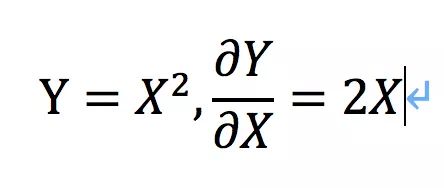
可知,在不同的X处它的导数是不相等的。如果遇到了一个导数为0的点,它很有可能就是最大值或者最小值,如下面的x=0点取得最小值y=0。

导数反映了y的变化趋势,比如这个方程x>0时,导数大于0,则y随着x的增加而增加。x<0时,导数小于0,则y随着x的增加而减小。
所以看导数,我们就得到了目标y的变化趋势,而深度学习或者说机器学习中需要优化的目标就是一个Y,也称之为目标函数,价值函数,损失函数等等。通常我们定义好一个目标函数,当它达到极大值或者极小值就实现了我们的期望。
不过还有个问题,就是导数等于0,一定是极值点吗?未必,比如鞍点。

上面的小红点就是鞍点,在这个曲面上,它在某些方向的导数等于0,但是显然它不是极值点,不是极大也不是极小,正因如此,给后面的优化埋下了一个坑。
如果你真的微积分也忘了,就需要补了。

3.2 数值微分
前面说了,机器学习就是要求解目标的极值,极大值极小值是等价的不需要纠结,通常我们求极小值。
上面的函数我们轻轻松松就求解出了导数,从而得到了唯一的极值,这叫做解析解,答案很唯一,用数学方程就能手算出来。
但是实际要优化的神经网络上百万个参数,是不可能求出解析解的,只能求数值近似解,就是用数值微分的方法去逼近。
数值微分的核心思想就是用离散方法近似计算函数的导数值或偏导数值,相信同学们在课程中都学过。
向前差商公式:
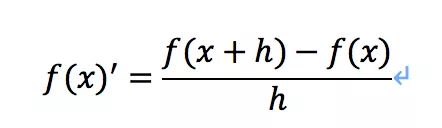
向后差商公式:
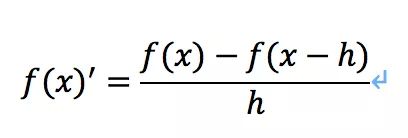
中心差商公式:
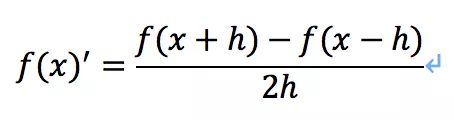
有了感觉咱们接着说
那么,一般情况下要求解任意函数极值的方法是什么呢?在深度学习中就是梯度下降法。
梯度下降法可以说是最广泛使用的最优化方法,在目标函数是凸函数的时候可以得到全局解。虽然神经网络的优化函数通常都不会是凸函数,但是它仍然可以取得不错的结果。
梯度下降法的核心思想就是(公式比较多,就截图了):

这一套对所有的函数f(x)都通用,所以以导数的反方向进行搜索,就能够减小f(x),而且这个方向还是减小f(x)的最快的方向,这就是所谓的梯度下降法,也被称为“最速下降法”,参数更新方法如下。

关于微积分和最优化,咱们就点到为止了,不然就超出了白身境系列的要求。要补这方面的知识,就比较多了,建议先找花书中的对应章节看看,找找感觉再说。

最优化的方法还有很多,目前在神经网络优化中常用的是一阶优化方法,不过二阶优化方法也慢慢被研究起来,最后还是给出一些关键词去掌握。
导数,偏导数,线性规划,二次规划,动态规划,Hessian matrix,损失函数,正则项,一阶优化方法(梯度下降法),二阶优化方法(牛顿法)等等。
好嘞,掌握了这些,就大胆往前走,不用怕了。
总结
数学这种东西,学习就是三步曲,一看书,二做题,三应用,其他学习方法比如看视频听课基本都是扯淡。
另外,数学怎么好都不过分。希望小白看完还能爱数学,毕竟这才刚刚开始一点点。
下期预告:下一期我们讲AI在当前各大研究方向。
转载文章请后台联系
侵权必究

AI白身境系列完整阅读:
第二期:【AI白身境】Linux干活三板斧,shell、vim和git
第五期:【AI白身境】搞计算机视觉必备的OpenCV入门基础
第六期:【AI白身境】只会用Python?g++,CMake和Makefile了解一下
第八期: 【AI白身境】深度学习中的数据可视化
第九期:【AI白身境】入行AI需要什么数学基础:左手矩阵论,右手微积分
第十二期:【AI白身境】究竟谁是paper之王,全球前10的计算机科学家
AI初识境系列完整阅读
第三期:【AI初识境】近20年深度学习在图像领域的重要进展节点
第六期:【AI初识境】深度学习模型中的Normalization,你懂了多少?
第七期:【AI初识境】为了围剿SGD大家这些年想过的那十几招
第八期:【AI初识境】被Hinton,DeepMind和斯坦福嫌弃的池化,到底是什么?
第十期:【AI初识境】深度学习模型评估,从图像分类到生成模型
第十二期:【AI初识境】给深度学习新手开始项目时的10条建议
感谢各位看官的耐心阅读,不足之处希望多多指教。后续内容将会不定期奉上,欢迎大家关注有三公众号 有三AI!
















 705
705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











