







 文章讲述了如何对彩票开奖数据进行预处理,包括数据标准化和特征提取,然后使用Python和随机森林算法进行预测模型的构建。虽然最终仅为娱乐目的,但展示了数据科学在预测问题上的应用。
文章讲述了如何对彩票开奖数据进行预处理,包括数据标准化和特征提取,然后使用Python和随机森林算法进行预测模型的构建。虽然最终仅为娱乐目的,但展示了数据科学在预测问题上的应用。
一、数据标准化
首先,我们需要对原始数据进行处理,将其转换为可用于机器学习的格式。我们可以将开奖号码中的红球和蓝球分开,将其转换为独热编码,然后将其与期数一起作为特征输入到机器学习模型中。
这里的数据集是我找到的2017年至今的数据集
import re
import csv
# 定义正则表达式
pattern = re.compile(
r'(\d{7})双色球开机号码:红球:(\d{2}),(\d{2}),(\d{2}),(\d{2}),(\d{2}),(\d{2}) 蓝球:(\d{2}) 开奖号:(\d{2}) (\d{2}) (\d{2}) (\d{2}) (\d{2}) (\d{2}) \+ (\d{2})')
# 读取 test.txt 文件
with open('test.txt', 'r',encoding="utf-8") as f:
lines = f.readlines()
# 初始化数据列表
data = [['期数', '红球1', '红球2', '红球3', '红球4', '红球5', '红球6', '蓝球', '开奖红球1',
'开奖红球2', '开奖红球3', '开奖红球4', '开奖红球5', '开奖红球6', '开奖蓝球']]
# 解析每一行数据
for line in lines:
match = pattern.match(line)
if match:
# 提取匹配结果
qishu = match.group(1)
shijihongqiu = [match.group(i) for i in range(2, 8)]
shijilanqiu = match.group(8)
kaijianghongqiu = [match.group(i) for i in range(9, 15)]
kaijianglanqiu = match.group(15)
# 将提取到的数据添加到 data 列表中
data.append([qishu] + shijihongqiu + [shijilanqiu] + kaijianghongqiu + [kaijianglanqiu])
# 将数据写入 csv 文件
with open('lottery.csv', 'w', newline='') as f:
writer = csv.writer(f)
writer.writerows(data)
二、预测代码
接下来,我们需要选择一个机器学习模型进行预测。由于该数据集中没有常规的y参数,因此我们可以采用无监督学习的方法,对球号之间的关系进行建模,然后根据建好的模型进行预测。
常见的无监督学习算法包括聚类和降维算法。聚类算法可以将数据集中的数据分为不同的组别,每个组别中的数据具有相似的特征。降维算法可以将高维数据降低到低维空间,以便更好地进行可视化和处理。
在这里,我们可以采用聚类算法,例如k-means算法,来将球号进行聚类。具体步骤如下:
读取数据集,将红球1到红球6的6个特征作为X。
对X进行标准化处理,使得每个特征的均值为0,标准差为1。
使用k-means算法对X进行聚类,将样本划分为k个不同的组别。
对于2023048期的数据,提取红球1到红球6的6个特征作为X,并进行标准化处理。
将2023048期的数据输入到k-means模型中,预测它所属的组别。
根据模型预测出的组别,从训练集中找到同一组别中的数据,并计算这些数据中蓝球出现的频率,将频率最高的蓝球作为预测结果。
但是这里并不使用聚类算法,因为我发现写到最后开机号码是提前给出来的,所以我们用开机号码和开奖号码进行分析。
使用随机森林算法进行预测,下面是Python代码实现:
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
# 读取数据
data = pd.read_csv('lottery.csv',encoding="gbk")
# 提取特征和标签
X = data.drop(['期数', '开奖红球1', '开奖红球2', '开奖红球3', '开奖红球4', '开奖红球5', '开奖红球6', '开奖蓝球'], axis=1)
y = data[['开奖红球1', '开奖红球2', '开奖红球3', '开奖红球4', '开奖红球5', '开奖红球6', '开奖蓝球']]
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestRegressor(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 在测试集上评估模型
from sklearn.metrics import mean_squared_error
y_pred = model.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
print('Mean squared error:', mse)
# 使用模型进行预测
predict_data = pd.DataFrame({
'红球1': [2],
'红球2': [10],
'红球3': [13],
'红球4': [17],
'红球5': [22],
'红球6': [26],
'蓝球': [1]
})
predict_result = model.predict(predict_data)
rounded_result = np.round(predict_result)
print('预测结果:', rounded_result)
结果如下:
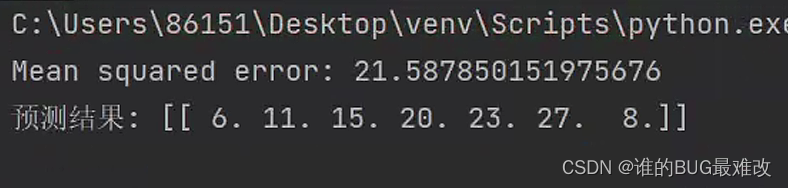
(注:本代码纯属娱乐,投资有风险)
三、后续
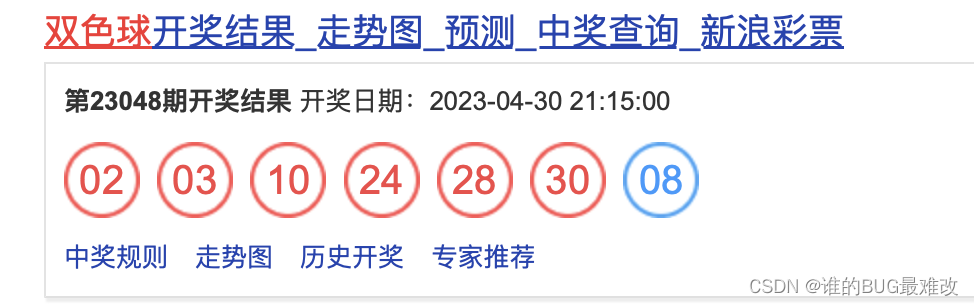
中了五块钱




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











