






https://github.com/mmehra12/cml_churn_demo/tree/master
1 示例介绍
在本次研讨会中,我们将向您介绍World Wide Telco organization的一个真实案例。该企业有许多机器学习用例,今天重点关注一个特定场景的用例。在该用例中,企业试图减少客户的流失(即取消),并且大多数取消来自企业的呼叫中心。在本次的动手实操中,客户Francisco会打电话表示取消,呼叫中心应用程序将根据Francisco的取消来预测取消原因,向WW Telco的客户经理Stefan提供建议。然后,他将向Francisco提供报价,用户将选择接受或不接受。

实操环节将带着大家完成CML的登录、代码获取以及使用已部署的模型构建完全工作应用程序的整个过程,具体操作流程如下:
- 初始化一个属于自己的CML Workspace
- 创建一个属于自己的Project(基于提供的代码模版)
- 将数据接入到属于我们自己的工作目录下
- 使用代码进行数据探索(基于Spark On K8s的环境进行数据探索)
- 构建一个模型实验环境,用于训练模型
- 模型部署(使模型有对外提供服务的能力)
- 应用程序部署(基于部署好的模型,与自己的应用程序打通)
2 创建一个Workspace
本次以参与客户公司为单位,每个公司初始化一个Workspace,接下来介绍如何初始化一个Workspace,具体操作流程如下:
- 使用个人账号登录到Cloudera Manager的控制台

- 点击ECS服务进入到服务的管理页面

- 点击”Web UI“,打开Storage UI、ECS Web UI、Console页面

Storage UI:该页面主要是Longhorn提供的查看和管理K8S分布式存储的功能

ECS Web UI:主要是K8S的原生管理界面,用于查看和管理调度、部署、job及pod等功能

Console:主要是Cloudera提供的DataService服务的管理控制台,可以实现(资源的统一监控、Base集群环境的管理、用户体系的管理、Data Warehouse、ML Workspace、Data Engineering、提供资源利用率报告等)

- 进入到Console控制台后,点击”Machine Learning”进入到CML的管理页面

- 点击”Provision Workspace“进入到配置Workspace页面
| 名称 | 值 | 备注 |
|---|---|---|
| Workspace Name | cloudera-workspace | 以公司名称创建一个相应的Workspace |
| Select Environment | pvc01 | 选择默认环境即可(这里就是对应的CDP Base集群) |
| Namespace | cloudera-workspace | 自动生成 |
| NFS Server | Internal | 选择内建NFS服务 |
| Custom NFS Settings | 不用设置 | |
| Enable Governance | 勾选 | |
| Governance Principal Name | mlgov | 默认即可 |
| Enable Model Metrics | 勾选 | |
| Enable Monitoring | 勾选 | |
| CML Static Subdomain | cldrws | 可不填写 |


6. 点击”Provision Workspace“,初始化Workspace

在初始化Workspace的过程中,会有一个比较长的等待时间(约20分钟),在此期间主要是K8S上启动需要的pods等动作
可以查看相应的Event Logs:


此时也可以进入到ECS Web UI页面查看自己的Workspace启动所涉及到的动作
可以看到当前Workspace初始化的过程及进度

点击”pods“,也可以看到启动失败pod的日志信息,有助于排查异常


此时也可以打开Storage Web UI页面,查看自己创建的Workspace有初始化相应的存储空间

7. 当看到所有工作负载均已正常启动则表示相应的Workspace以初始化成功

8. 回到CML的控制台页面可以看到对应的Workspace已Ready

到此为止完成了Workspace的初始化,接下来可以开启我们的CML之旅了。
3 Workspace全局配置
- 进入Console控制台,点击Machine Learning菜单

- 点击自己创建的Workspace进入

- 点击”Site Administration“菜单,进入到Workspace的全局配置页面

- 点击”Runtime“菜单配置Hadoop CLI版本

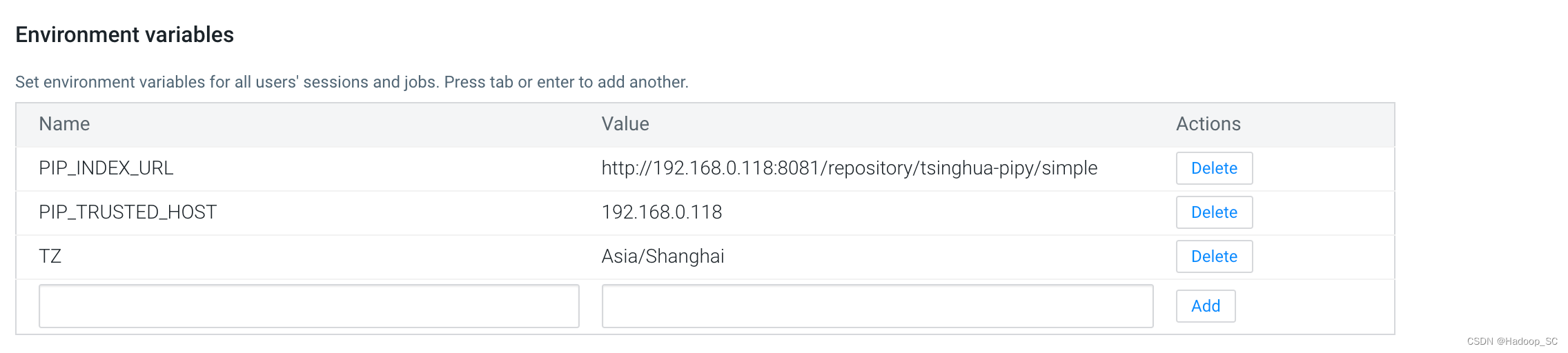
- 将滚动条拉到最下面,配置全局的环境变量
| 参数名 | 值 |
|---|---|
| PIP_INDEX_URL | http://192.168.0.118:8081/repository/tsinghua-pipy/simple |
| PIP_TRUSTED_HOST | 192.168.0.118 |
| TZ | Asia/Shanghai |
注意:此处主要配置Python的pip repo源,方便在Project中安装Python依赖包,示例中是使用Nexus搭建的私有源,这里可以将源修改为其他的公有源,具体参考如下:
| 镜像名 | 镜像地址 |
|---|---|
| 清华大学 | https://pypi.tuna.tsinghua.edu.cn/simple/ |
| 阿里云 | http://mirrors.aliyun.com/pypi/simple/ |
| 中国科技大学 | https://mirrors.bfsu.edu.cn/pypi/web/simple/ |
| 豆瓣 | http://pypi.doubanio.com/simple/ |
- 点击”User Settings“,进入到用户环境配置页面,绑定Kerberos账号

输出Principal及对应的密码信息,进行绑定,绑定成功提示如下:

完成上述的全局环境配置后,接下来就可以创建自己的Project开发机器学习的模型了。
4 创建一个Project
- 通过如下地址下载准备好的示例工程代码,获取到一个cml-demo.zip包
上课时老师会发给大家
- 进入到已经创建好的Workspace页面
- 点击”New Project“,创建一个属于自己的Project

注意:这里将上面下载好的cml-demo.zip包上传至”Local Files“下
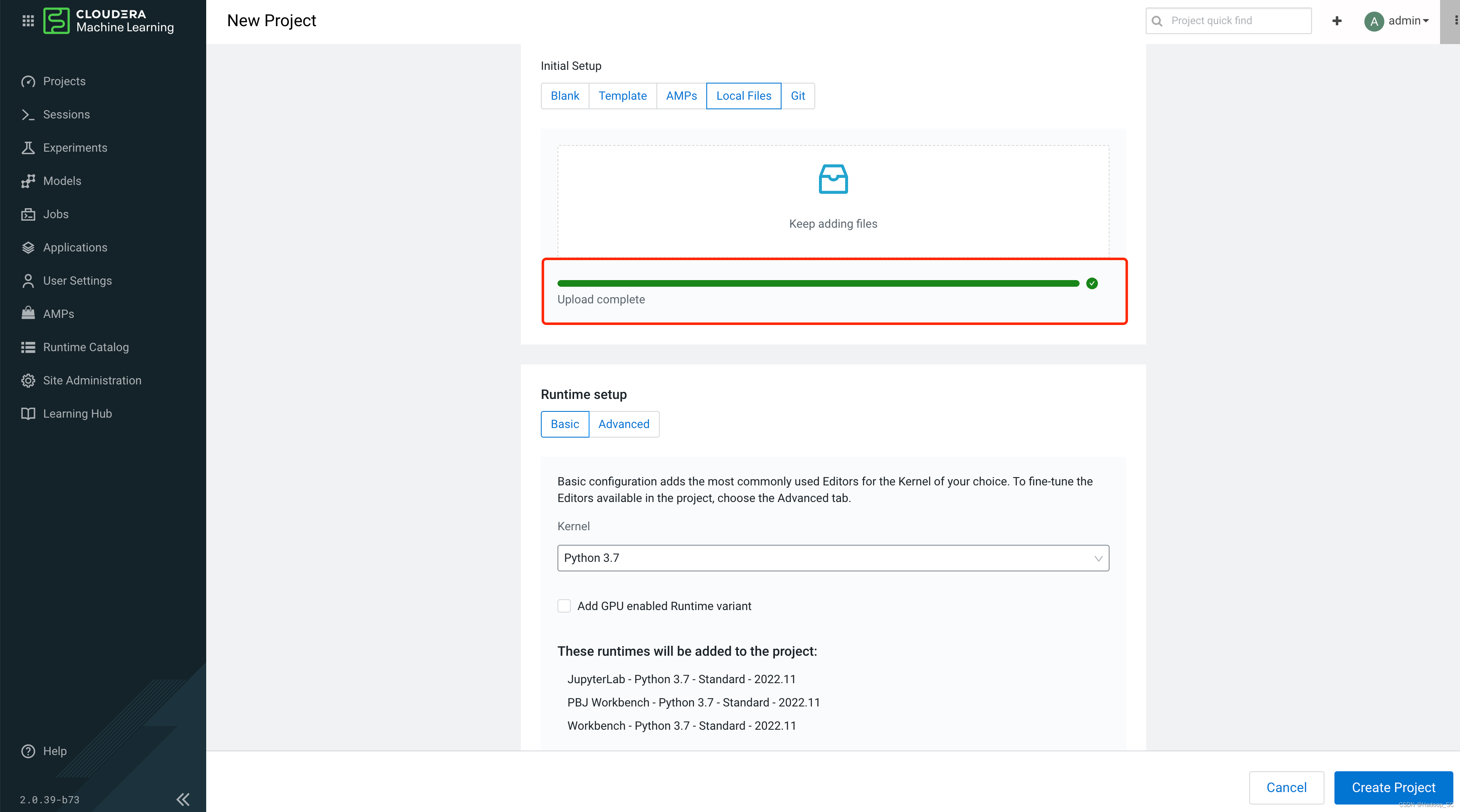
等待示例代码上传完成,点击”Create Project“即可完成Project的创建。
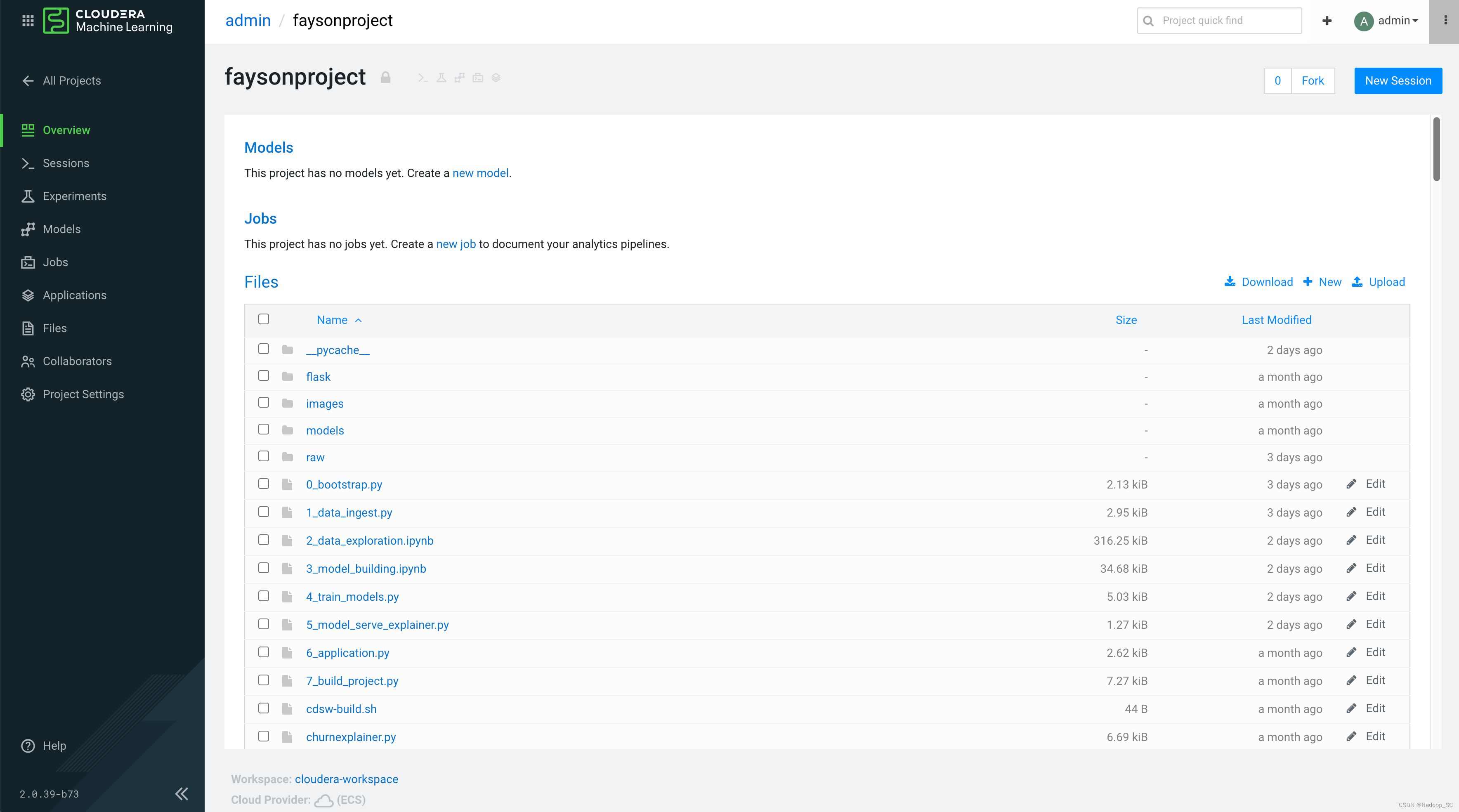
到此完成了Project的创建,接下来可以开始默写代码的编写、调试、运行及部署了。
5 示例运行及编写
该阶段主要分为几个部分,主要如下:
- 数据接入部分(将本地或其他数据源数据接入到Base CDP集群)
- 数据探索部分(基于接入的数据,进行数据探索分析,找出模型需要的特征数据)
- 基于探索得到的特征数据,进行模型的训练
- 将训练好的模型部署上线,并对外提供API服务的能力
- 部署应用程序并实现模型服务的调用
5.1 数据接入
- 点击创建好的Project,进入到如下页面
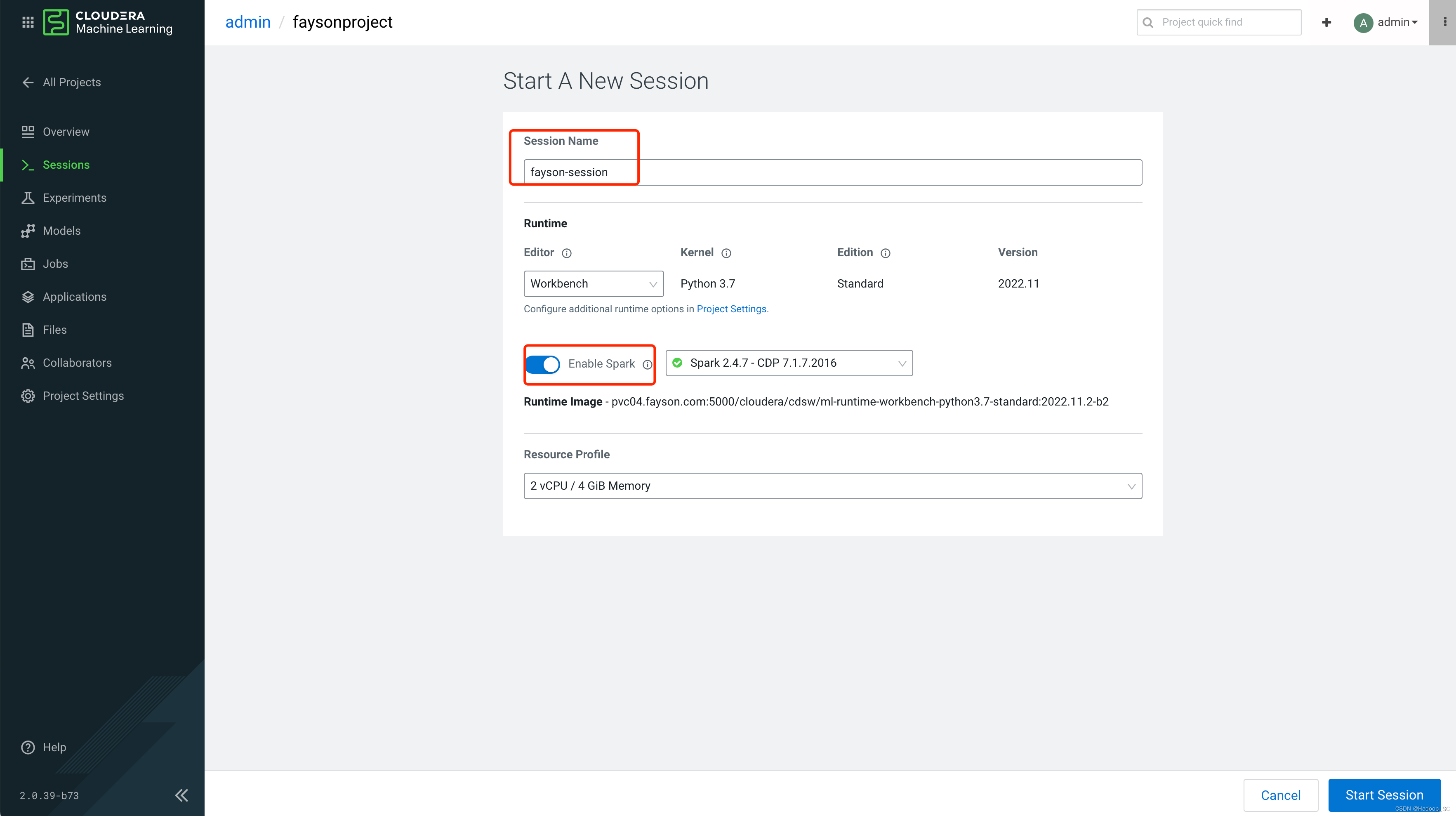
- 点击”New Session“,进入到启动Session的页面,填写启动Session的基本信息,并勾选Enable Spark
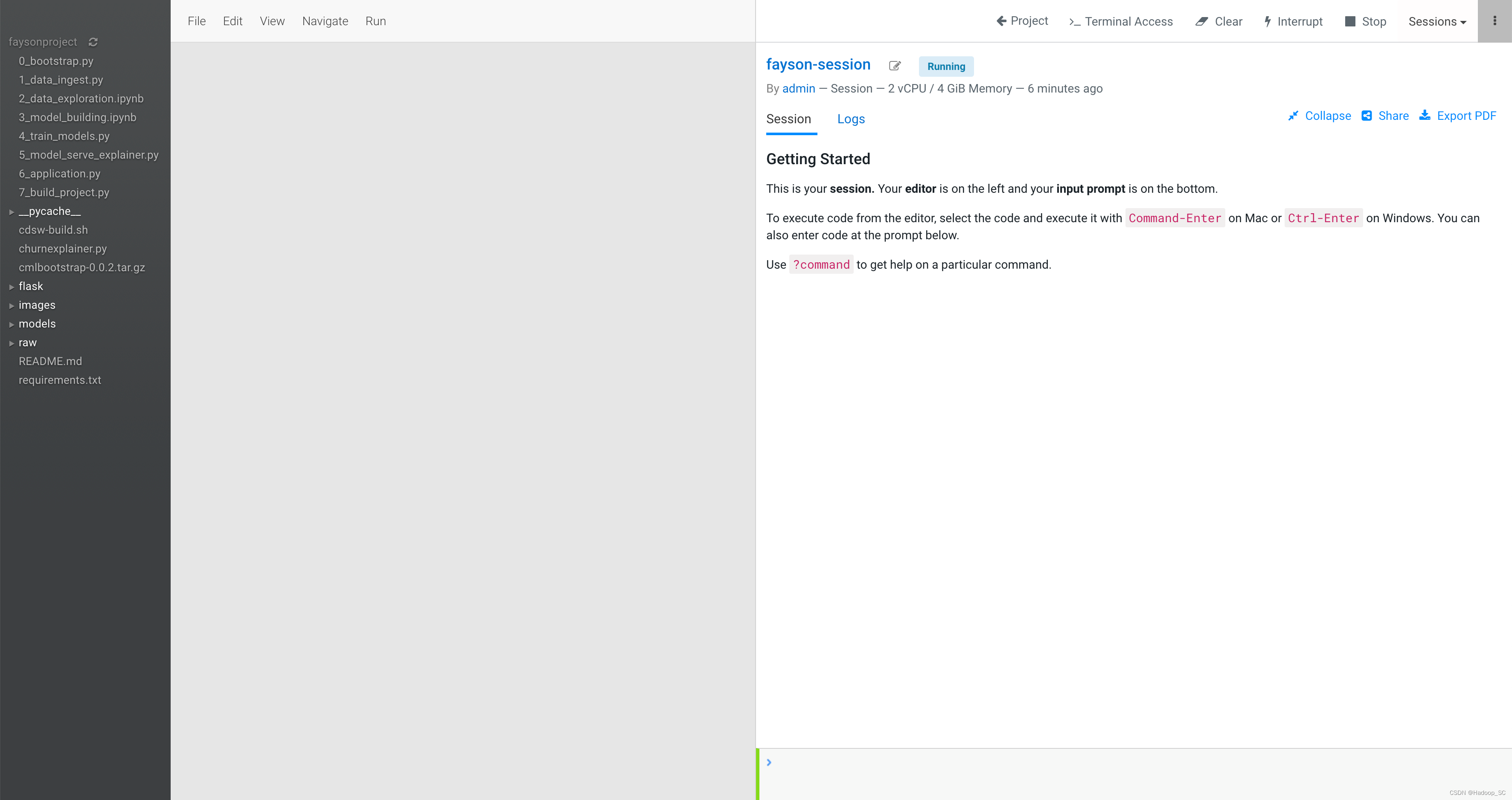
- 点击”Start Session“按钮,启动Session,如下图启动成功
- 打开左侧0_bootstrap.py文件
点击运行,可以看到运行代码即可看到运行结果
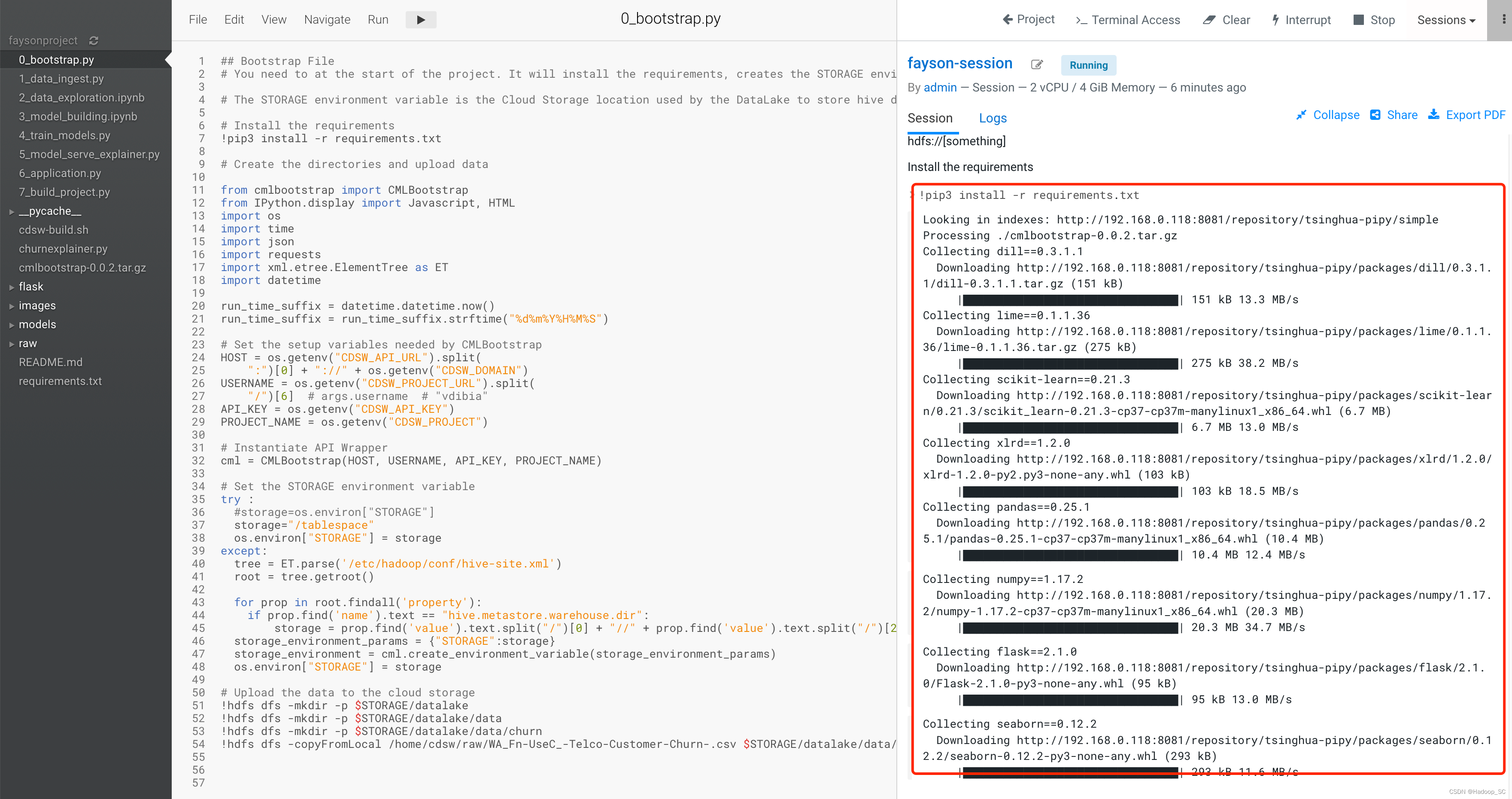
- 运行成功,将数据文件上传到Base CDP集群指定的目录下
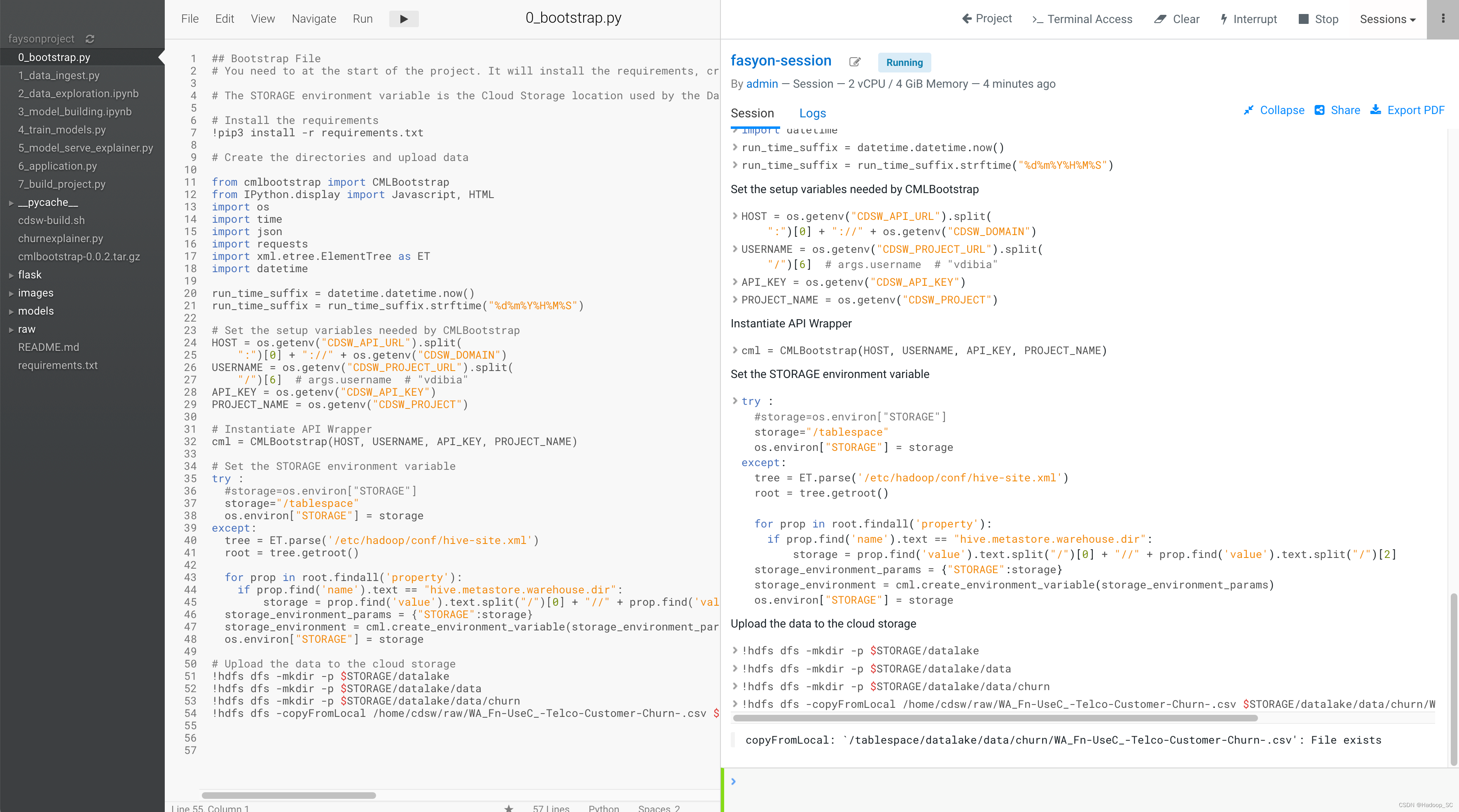
在命令行查看HDFS路径,确认文件是否已上传至HDFS
!hadoop fs -ls /tablespace/datalake/data/churn

注意:需要将数据文件上传至自己的用户空间,如/user/${username}/datalake/data/churn目录下,这里会涉及到修改代码片段,以及后续代码中的环境变量。
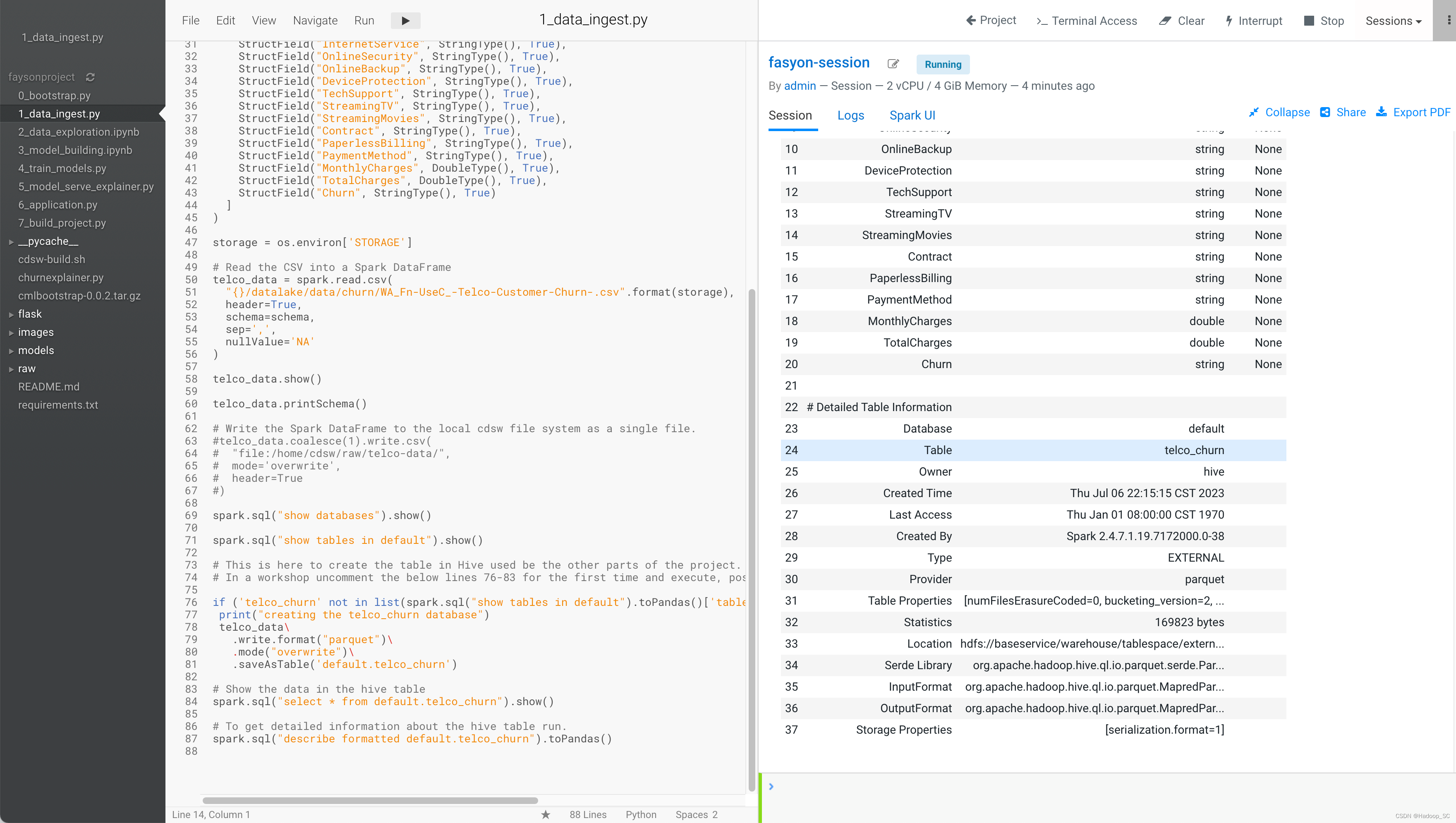
6. 打开1_data_ingest.py代码,该代码主要是将上一步上传到HDFS的数据文件,通过Spark读取到Dataframe中,并创建一个相应的Hive表
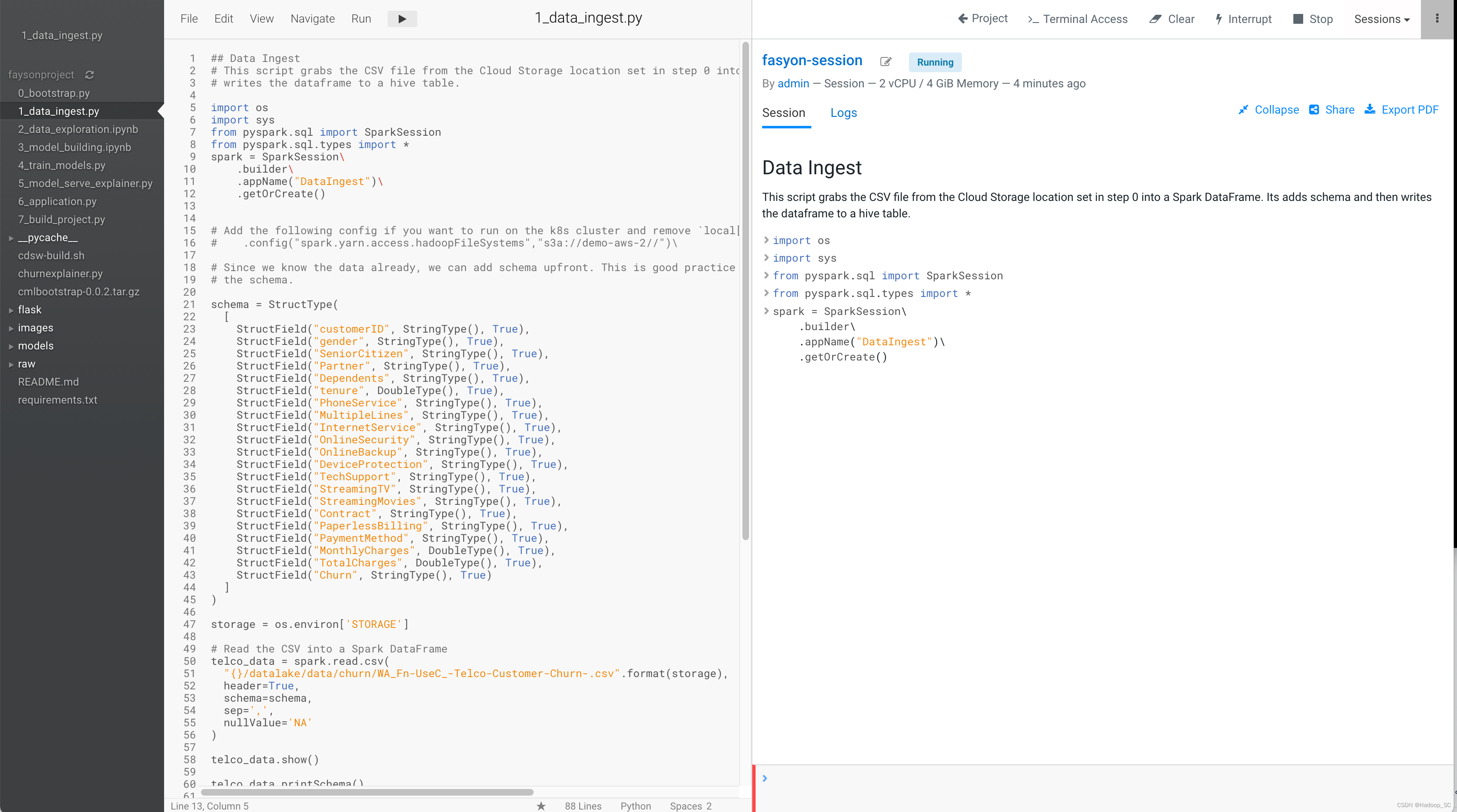
点击运行代码,会创建一个Spark作业,该作业为Spark on K8s任务,可以通过ECS Web UI界面查看
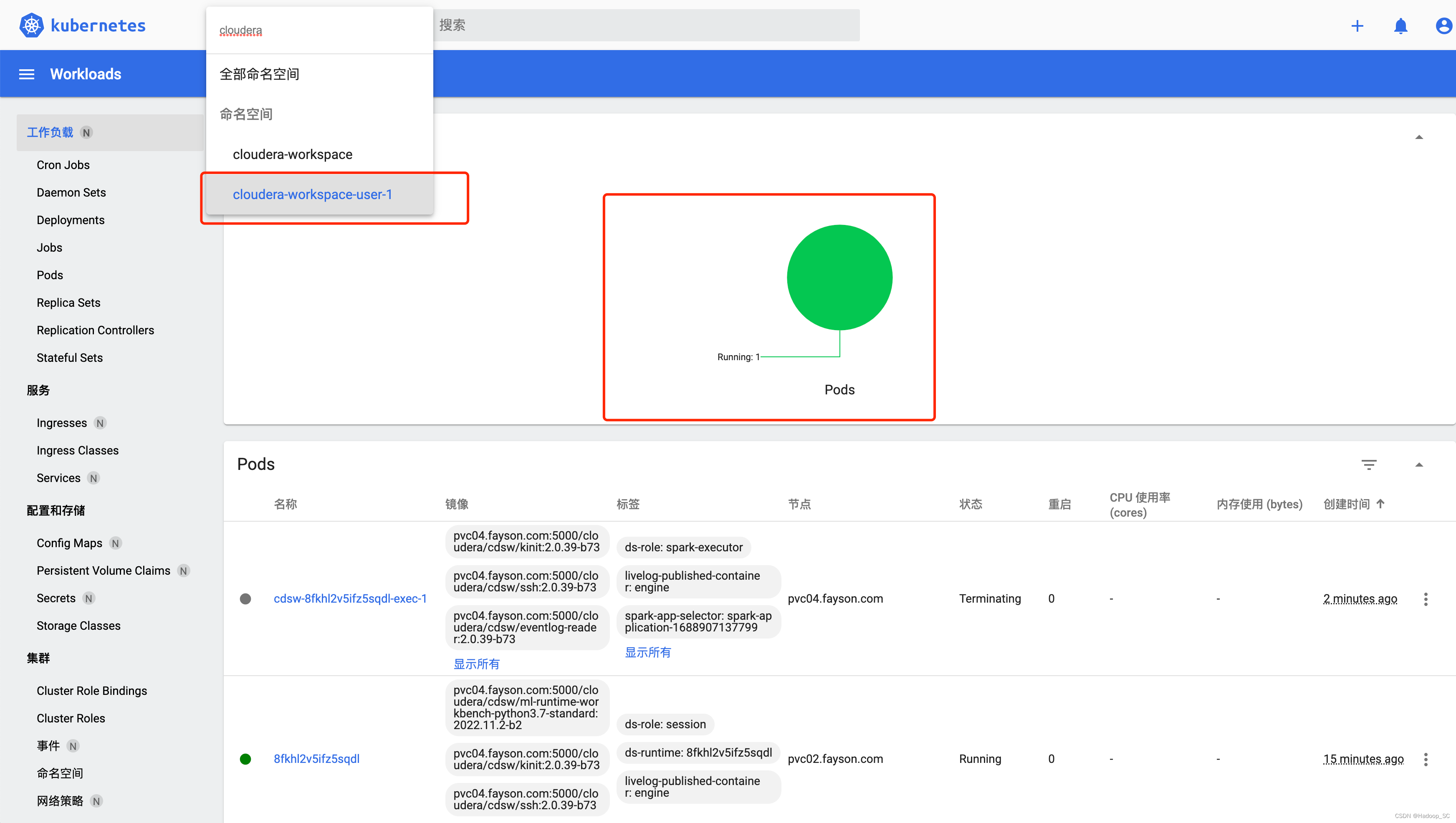
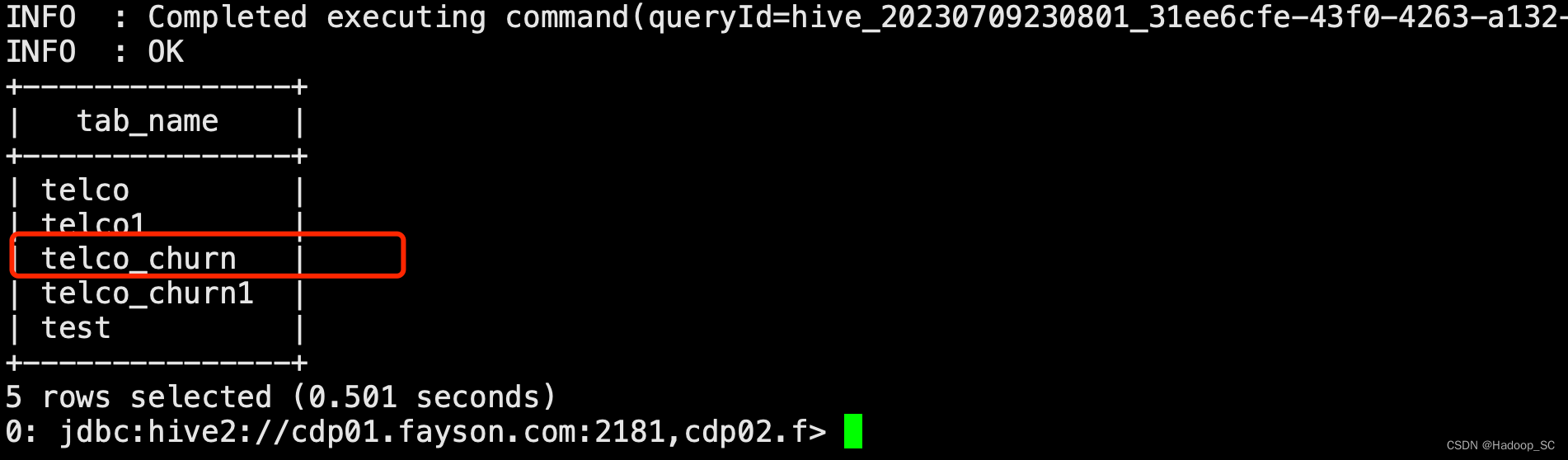
代码运行成功,相应的Hive表创建成功
注意:要求创建一个属于自己的数据表,用于做数据分析及探索使用,在default库下创建一以自己账号为后缀的Hive表(如:telco_churn_taopl),并在后续的数据探索分析中使用。
5.2 数据探索
在数据探索阶段,将使用CML中集成的Jupyter Lab编辑器来进行,它支持你使用自定义的编辑器,接下来主要采用现阶段流程的Jupyter运行试验代码。
- 点击“Project”,返回项目页面

- 点击“New Session”,启动一个新的Session
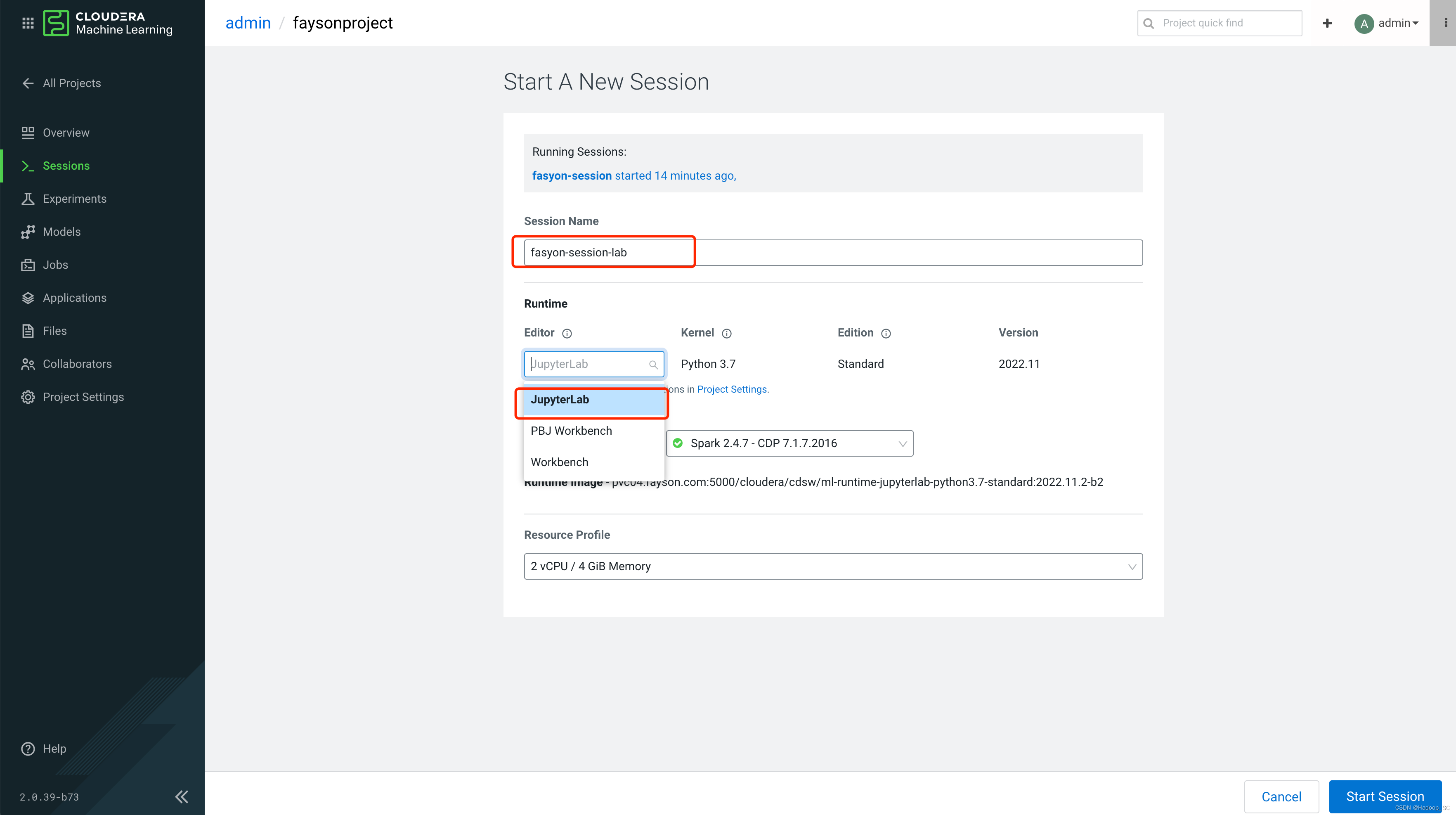
- 点击“Start Session”,启动会话
- 双击左侧的2_data_exploration.ipynb文件,打开Jupyter的notebook
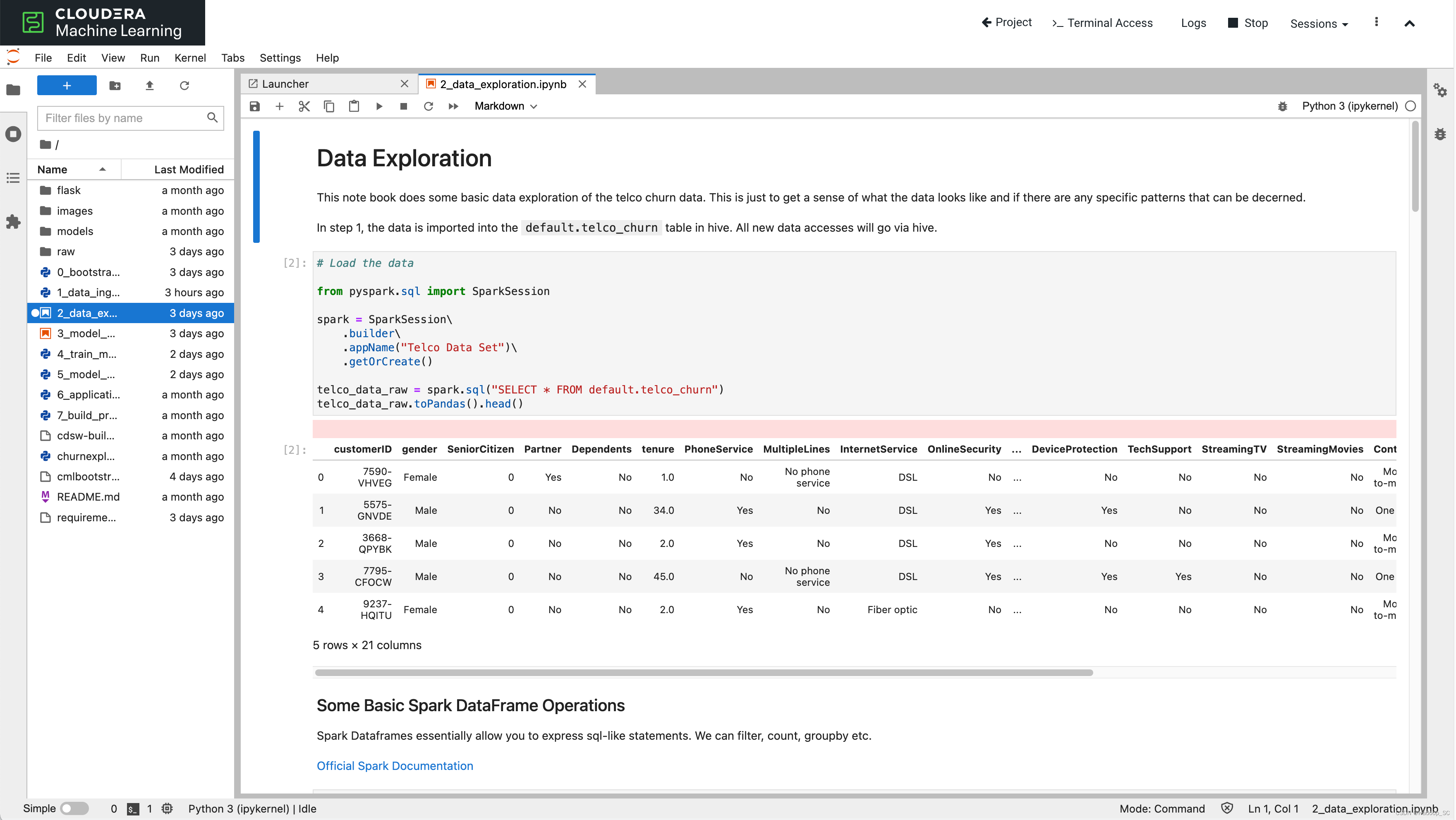
- 点击run all运行所有的代码段
当在运行的过程中会发现,有时会遇到Python的依赖包不存在,而直到运行失败的情况
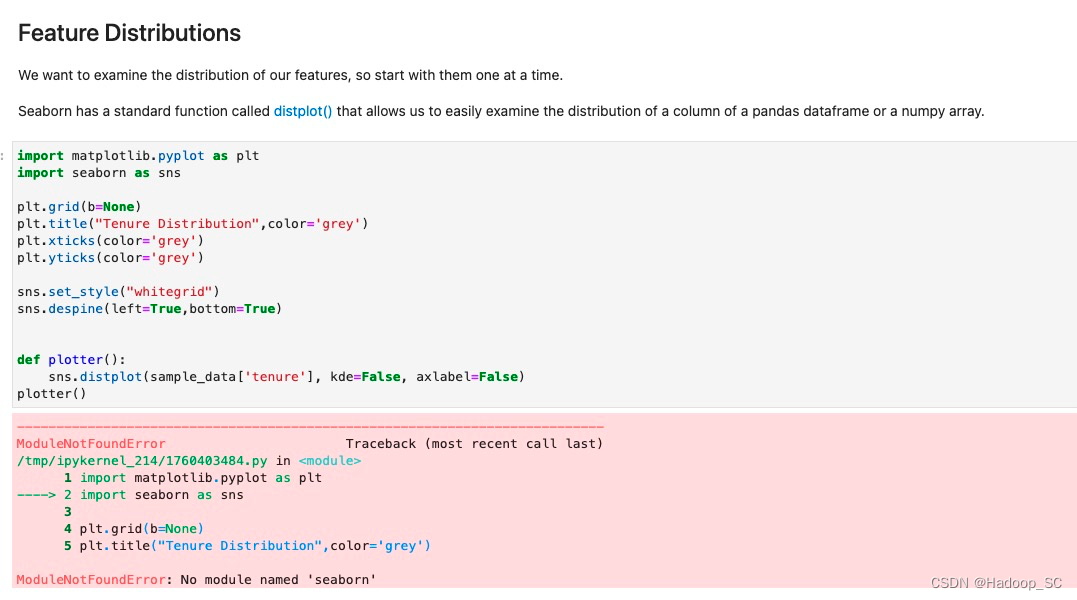
在这个情况下,可以通过在前面0_bootstrap.py阶段来添加缺少的依赖包解决,当然也可以在代码段中添加如下代码,使用pip3 install命令安装依赖包的方式实现
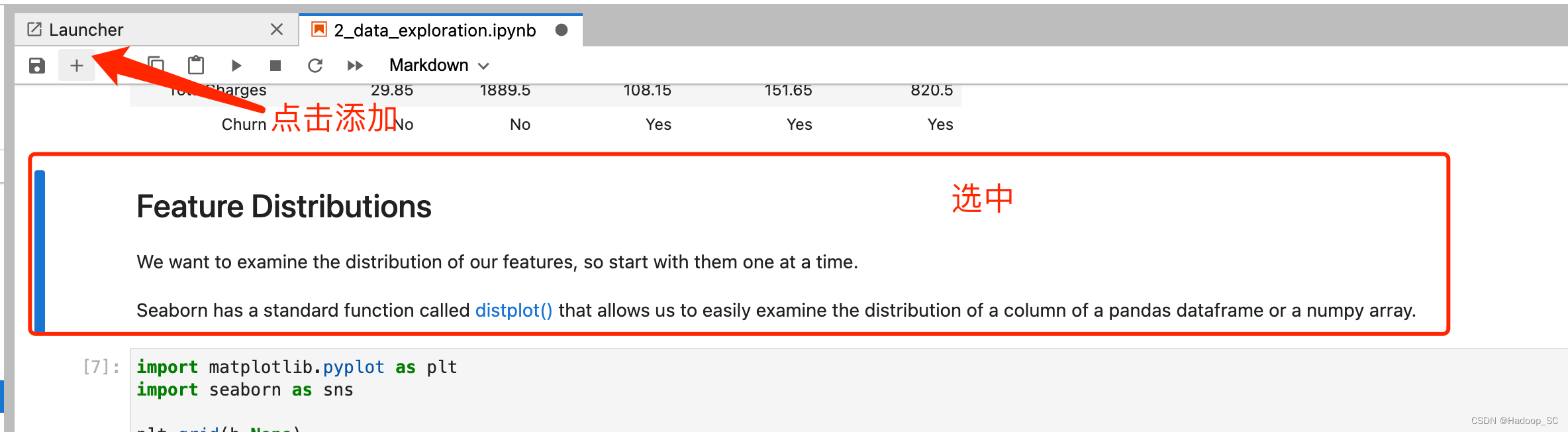
在新插入的cell种输入如下代码安装缺失的依赖包
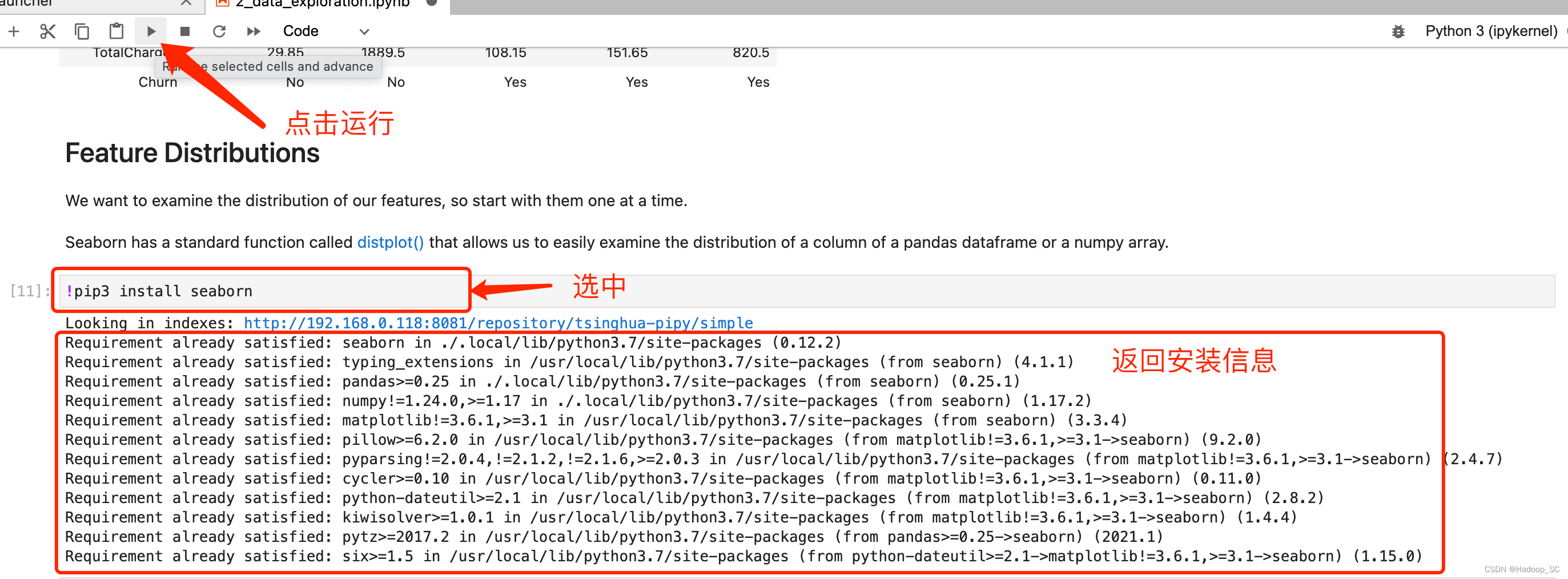
完成依赖包的添加后,可以继续运行如下代码,进行数据探索分析。 - 可以输出各种各样的图表用于分析
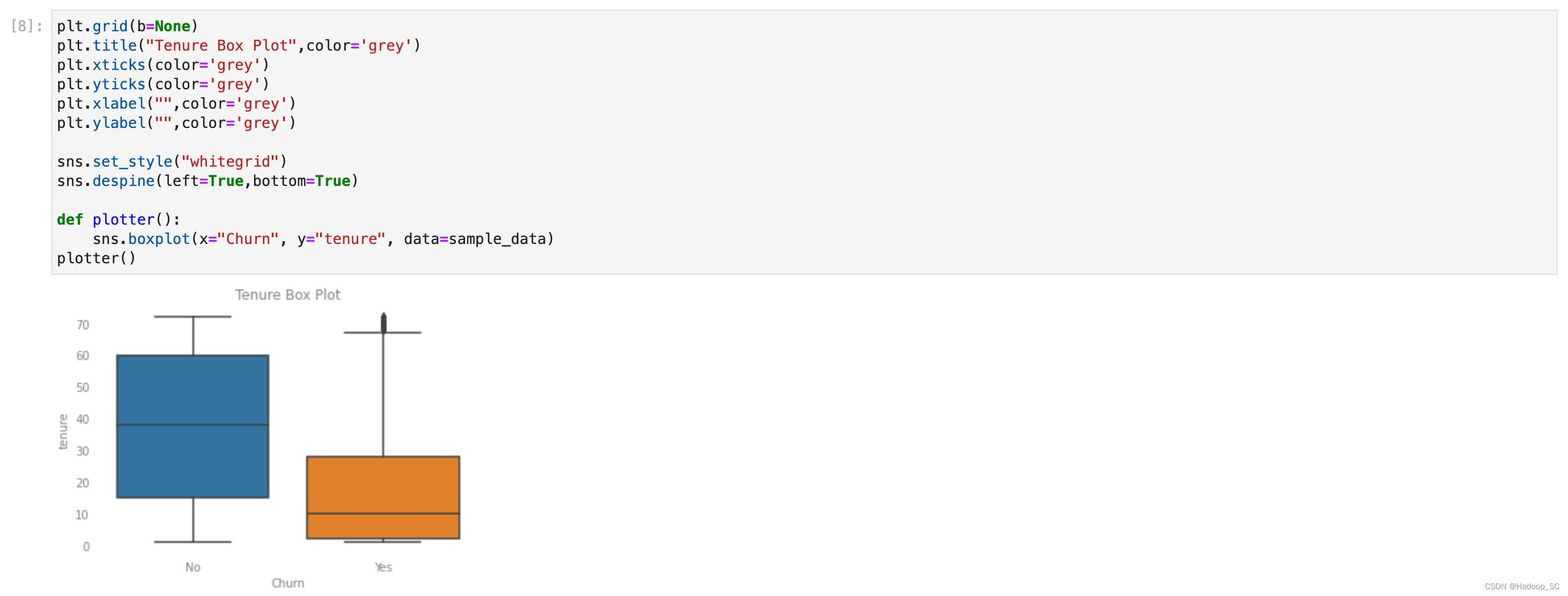
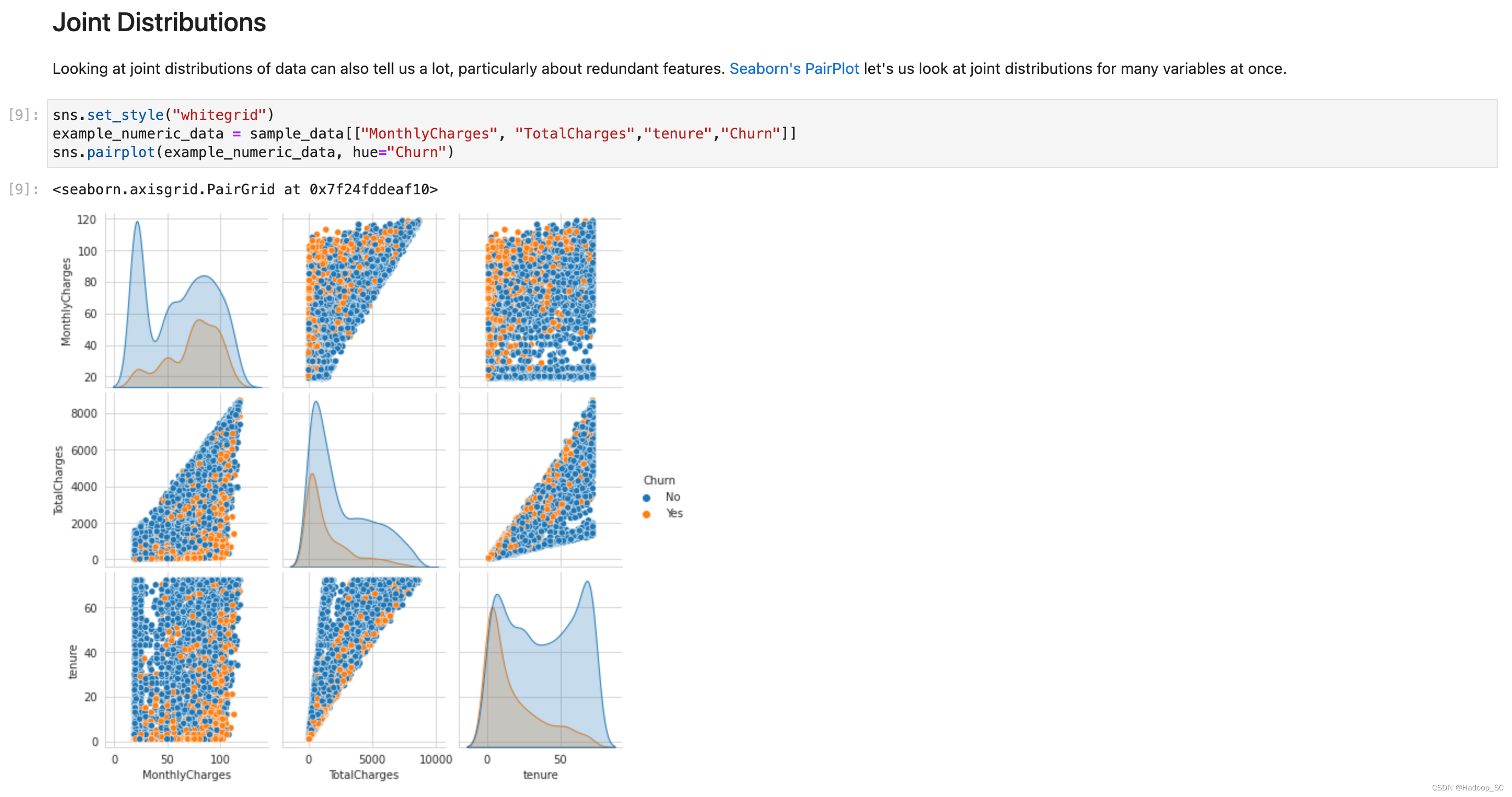
到此为止数据探索环节完成。
5.3 模型构建
模型构建主要做了如下几个步骤:
- 读取数据(也就是前面阶段我们准备好的数据,通过Spark作业将Base CDP集群Hive的数据加载到Spark并转换成pandas对象)
- 通过读取的数据构建基础特征工程(将数据转换为 LogisticRegression 和 LIMEExplainer 所需的格式)
- 使用sklearn构建一个机器学习模型
- 使用 OneHotEncoder 对分类特征进行编码
- 使用 StandardScaler 转换数字特征
- 将此数据拟合到 LogisticRegressionCV 模型
- 生成AUROC曲线
- 解释器使用 LIME
- 解释单个实例(Lime 将该实例解释为从 -1 到 1 的特征权重。越接近 -1 ,出现的影响越大,预测结果为0(不会流失),反之亦然。)
- 使用ExplainedModel类方便的输出模型文件
- 在数据探索的session中,双击打开3_model_building.ipynb文件
- 点击Run > Run All Cells,运行所有的Cells代码段
- 拉到代码运行的最后,可以看到会输出一个pkl的模型文件

查看是否有生成对应的模型文件
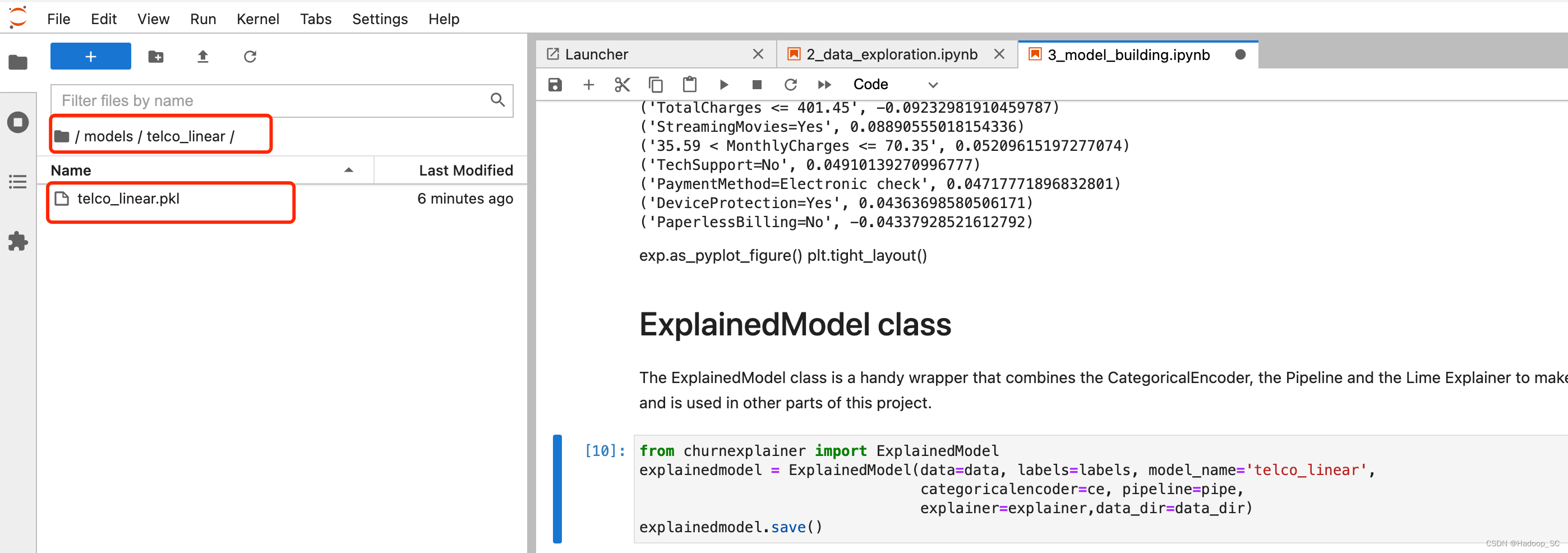
- 点击“Stop”关闭此Session,到此完成了模型的构建
5.4 模型训练
- 点击“Project”,返回项目页面,启动一个新的Session
- 打开4_train_models.py文件,熟悉模型训练的示例代码
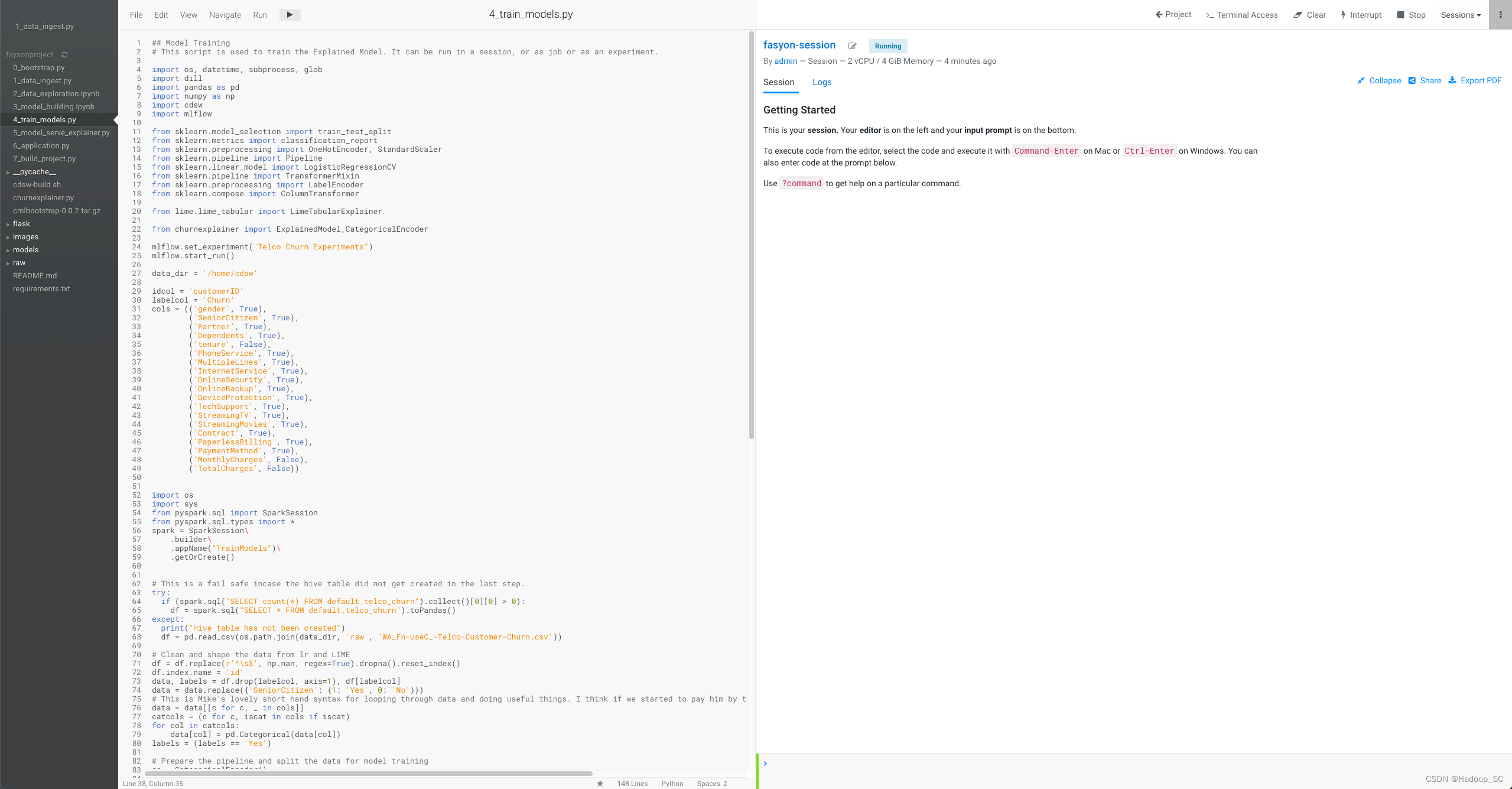
- CML平台中引入了机器学习平台MLFlow,这是一个能覆盖机器学习全流程(从数据准备到模型训练到最终部署)的新平台。MLFlow是一款管理机器学习工作流程的工具,核心由以下4个模块组成:
MLflow Tracking:如何通过API的形式管理实验的参数、代码、结果,并且通过UI的形式做对比。
MLflow Projects:代码打包的一套方案。
MLflow Models:一套模型部署的方案。
MLflow Model Registry:一套管理模型和注册模型的方案。
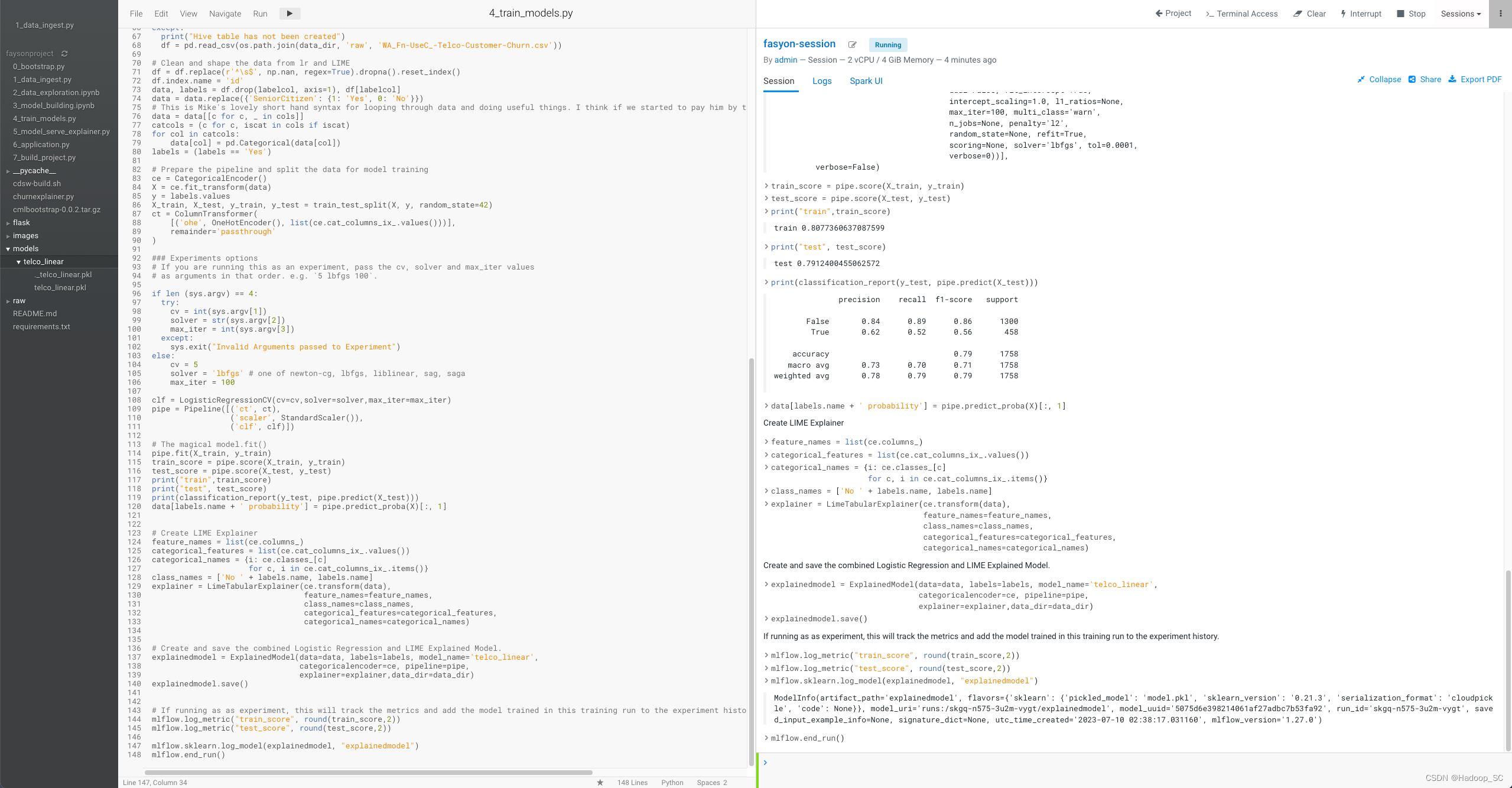
- 模型训练的代码中,还包含指标记录代码段,在模型训练时可以通过该方法将训练的指标记录下来并进行追踪分析
# If running as as experiment, this will track the metrics and add the model trained in this training run to the experiment history.
mlflow.log_metric("train_score", round(train_score,2))
mlflow.log_metric("test_score", round(test_score,2))

5. 点击Run -> Run All运行所有代码,如下显示则表示运行成功
6. 点击“Project”返回到项目信息页面,点击“Experiments”

在4_train_models.py文件中设置了训练的名称
点击“Telco Churn Experiments”进入查看详情,可以看到模型训练过程中输出的技术指标
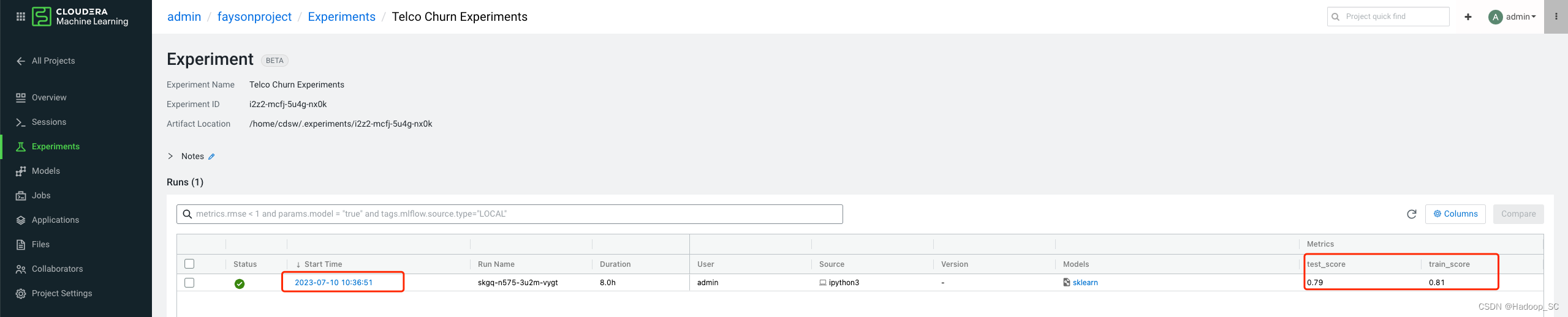
根据模型训练输出的评分来评估模型训练的好坏,可以通过点击“Models”栏对应的名称查看具体的模型保存的目录及模型引入方式

提供了在Spark和Pandas上的预测的示例代码。
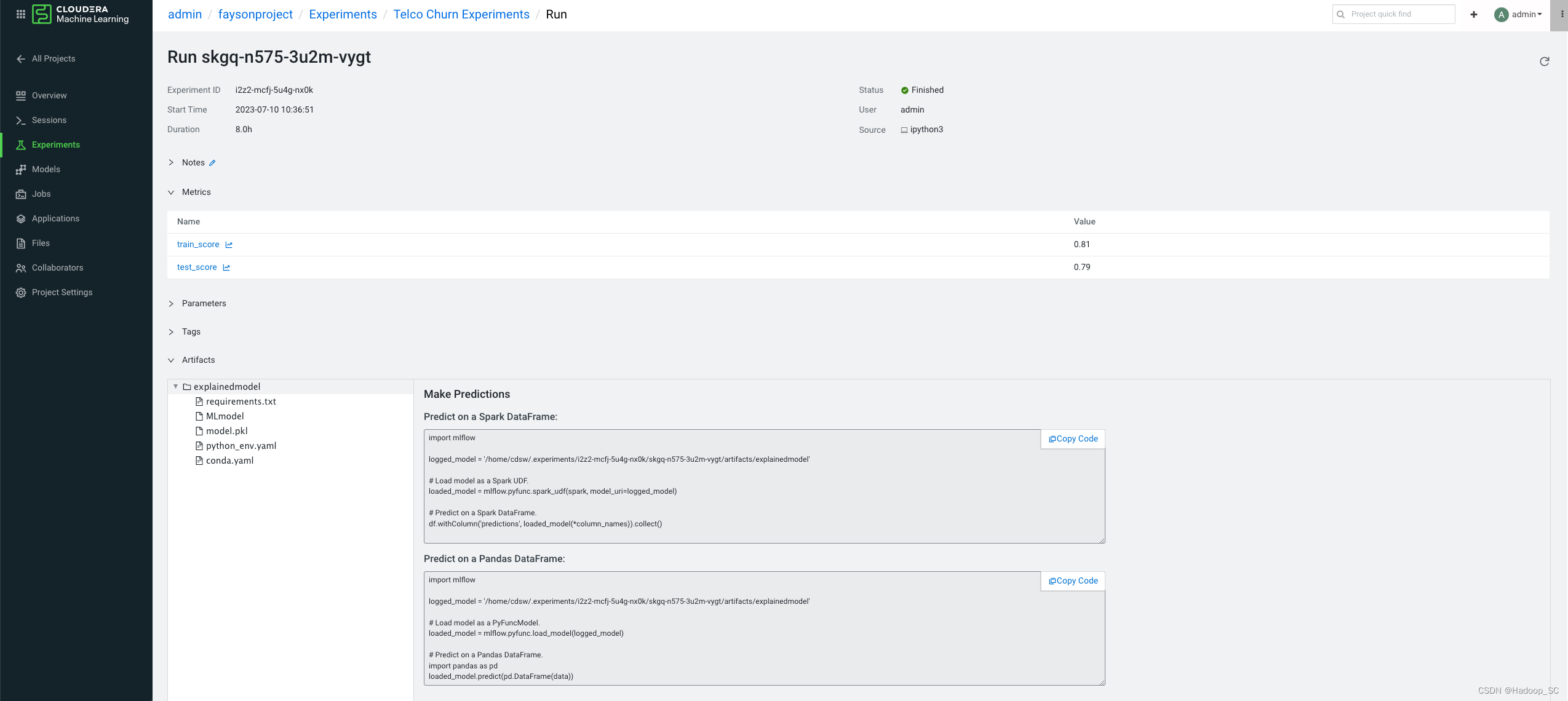
到此为止完成了模型的训练实操。
5.5 模型部署/服务
在本实验中,可以将5.4章节训练好的模型部署成一个Rest API接口,对外提供服务能力,该模型可以根据业务的需要提供实时和批量的预测方式。5_model_serve_explainer.py脚本中提供了pkl模型文件的加载及对外提供API接口的代码定义。
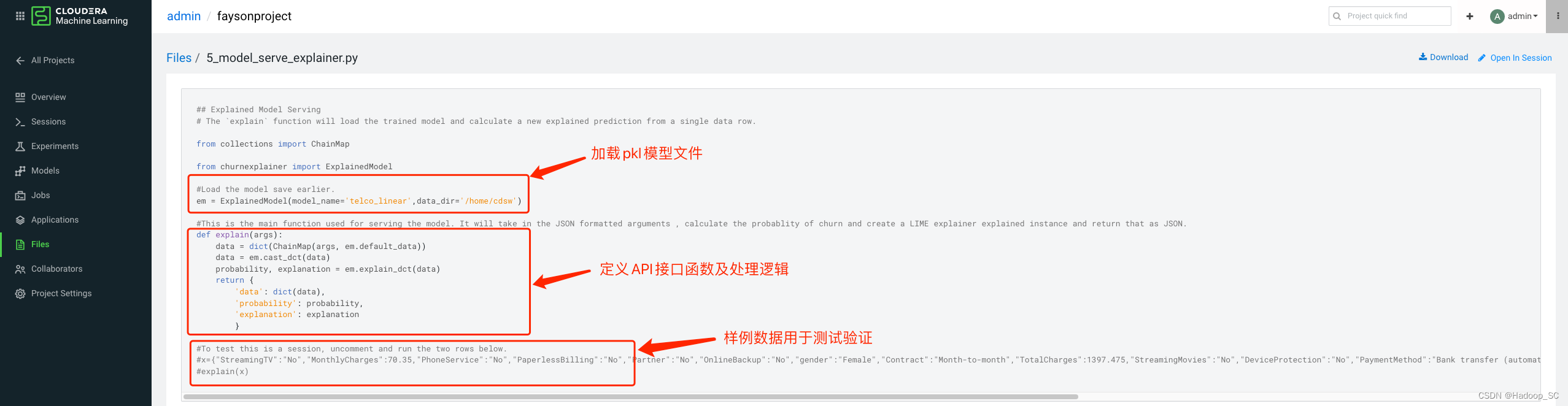
- 点击“Models”菜单,进入到模型部署页面

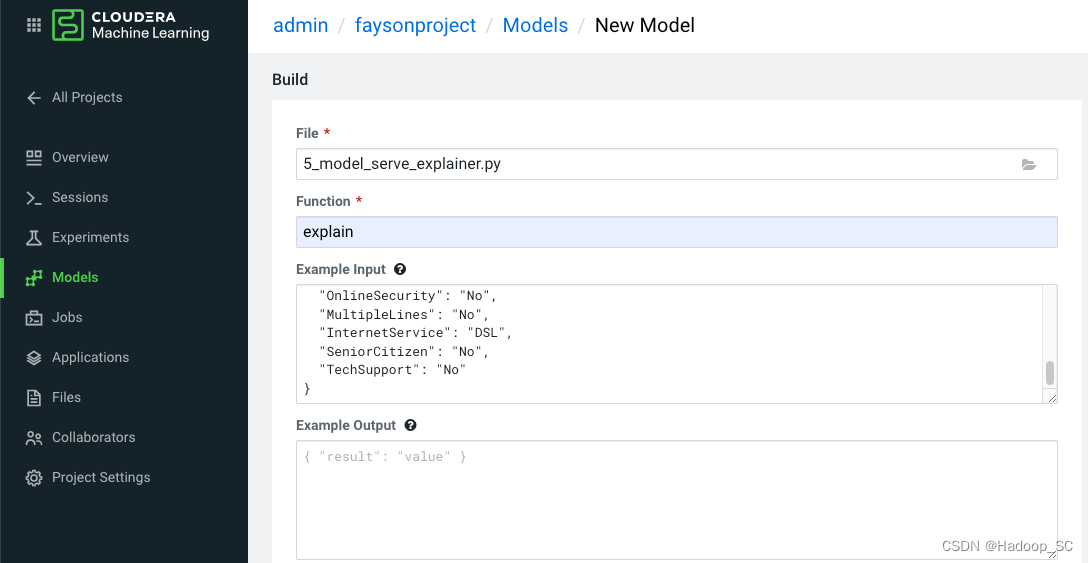
- 点击“New Model”按钮,进入模型部署页面,填写部署相关信息
| 名称 | 值 | 备注 |
|---|---|---|
| Name | my-model | |
| Description | my-model | 描述下该服务主要实现的能力 |
| Enable Authentication | false | 是否开启认证的方式访问接口 |
| File | 5_model_serve_explainer.py | 选择编写好的代码,作为服务的入口 |
| Function | explain | 代码中定义好的function名称 |
| Example Input | {“StreamingTV”:“No”,“MonthlyCharges”:70.35,“PhoneService”:“No”,“PaperlessBilling”:“No”,“Partner”:“No”,“OnlineBackup”:“No”,“gender”:“Female”,“Contract”:“Month-to-month”,“TotalCharges”:1397.475,“StreamingMovies”:“No”,“DeviceProtection”:“No”,“PaymentMethod”:“Bank transfer (automatic)”,“tenure”:29,“Dependents”:“No”,“OnlineSecurity”:“No”,“MultipleLines”:“No”,“InternetService”:“DSL”,“SeniorCitizen”:“No”,“TechSupport”:“No”} | |
| Runtime | Workench | |
| Enable Spark | TRUE - Spark 2.4.7 | |
| Comment | ||
| Resource Profile | 2 vCPU / 4 GiB Memory | |
| Replicas | 2 |
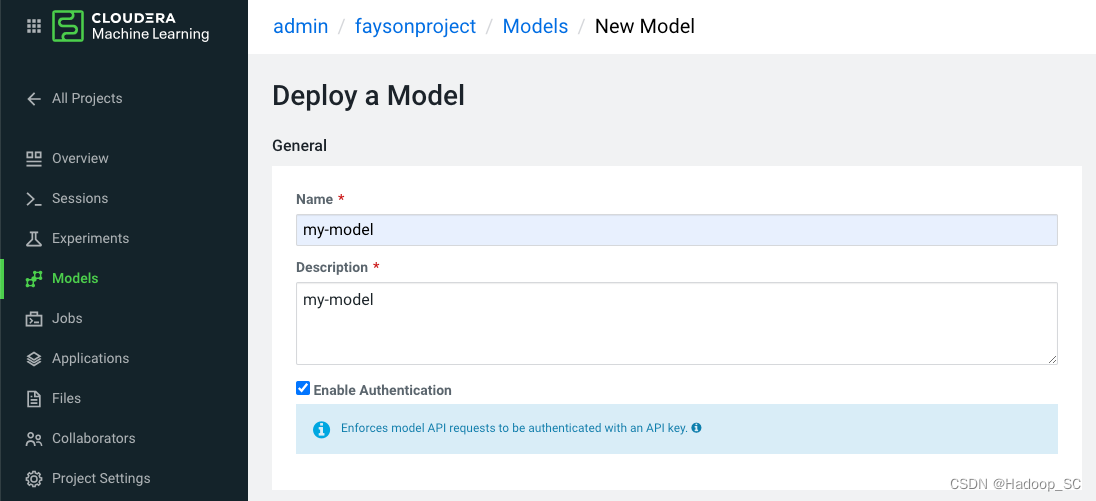
3. 点击“Deploy Model”按钮提交部署模型

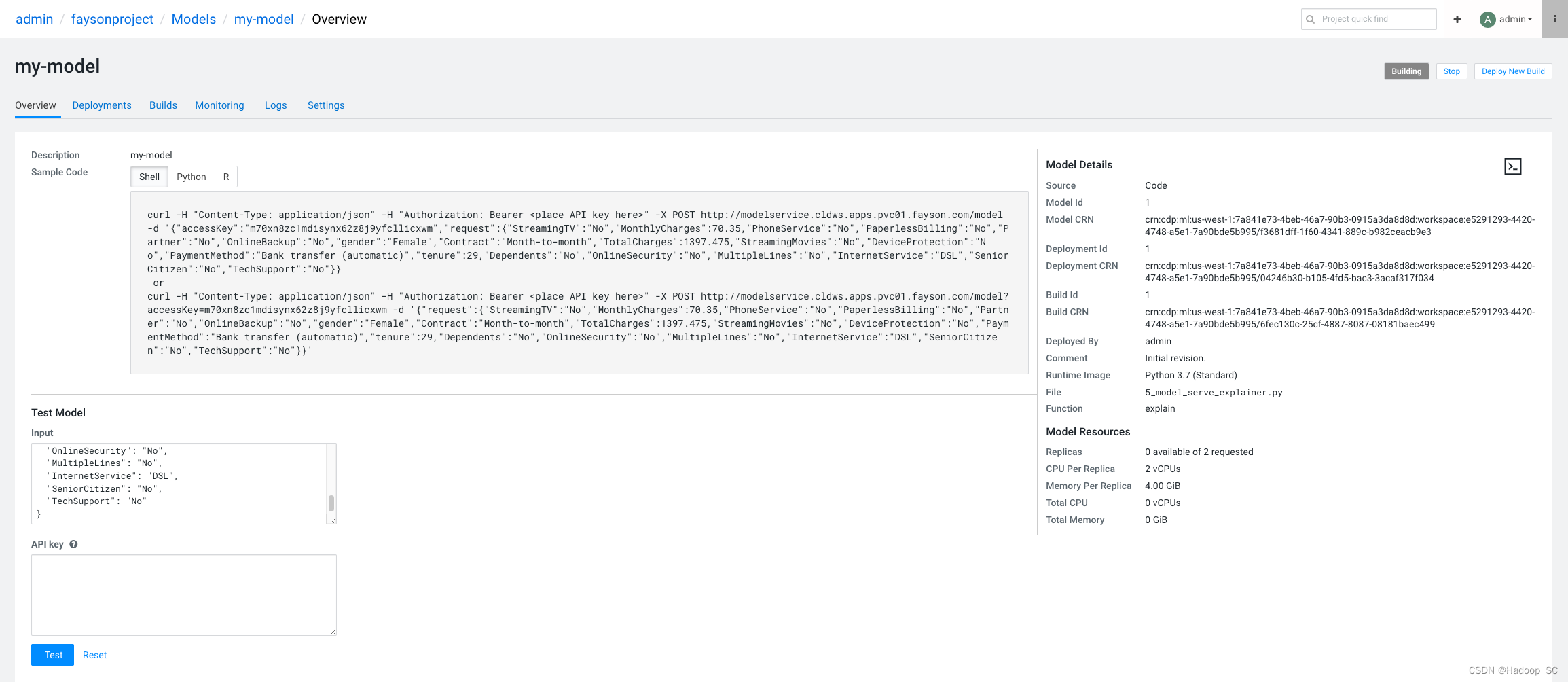
点击“my-model”,进入到模型的概览页面
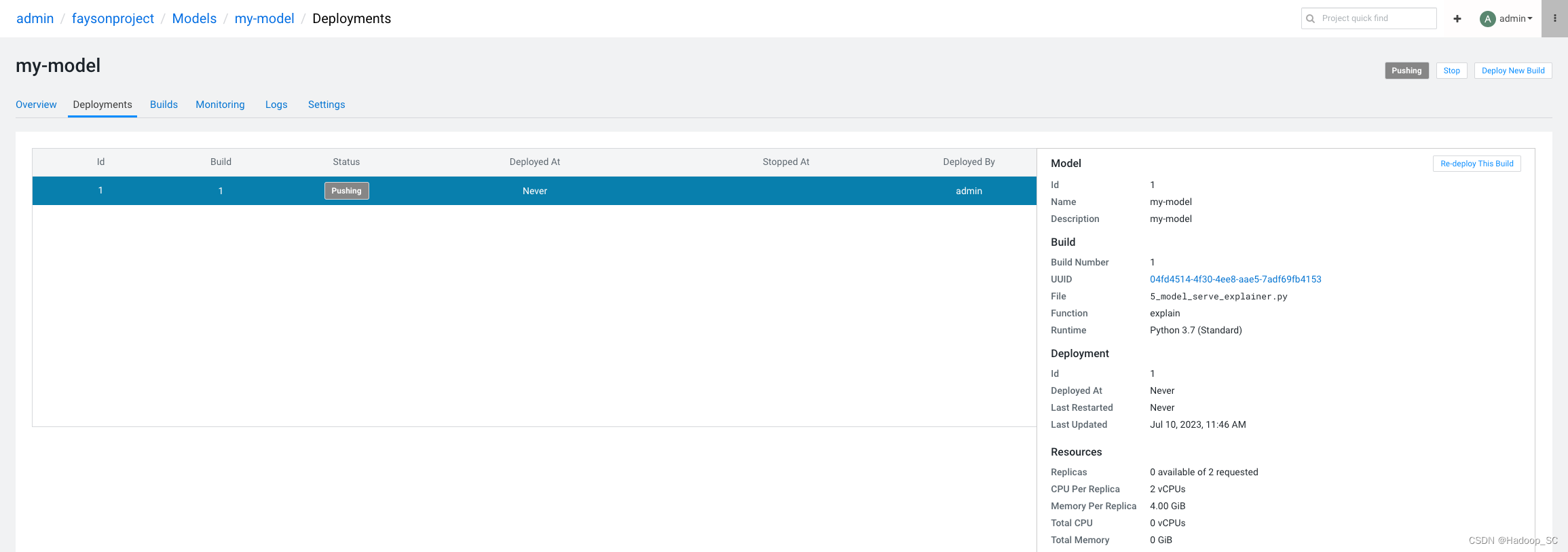
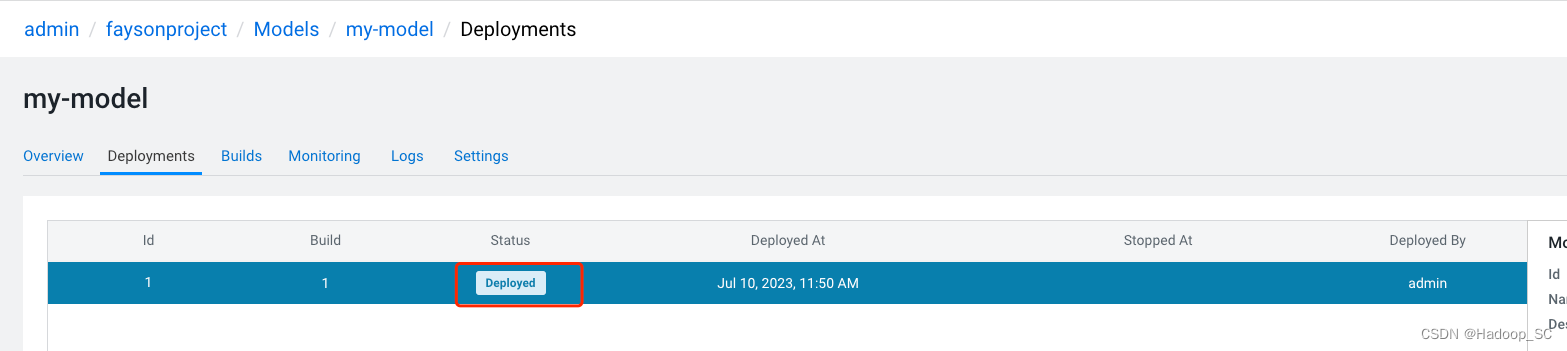
点击“ Deployments”,查看模型部署的状态以及历史部署情况
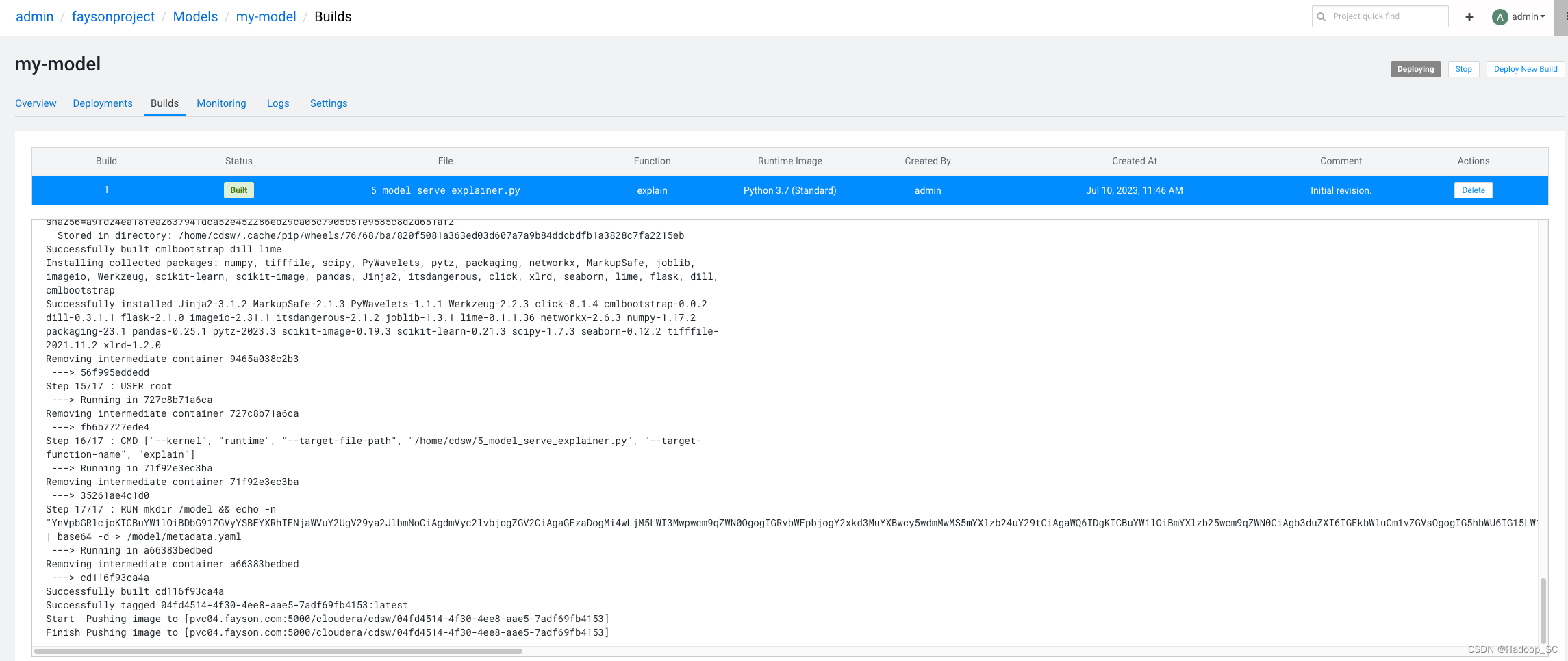
点击“Builds”,查看模型的部署进度日志
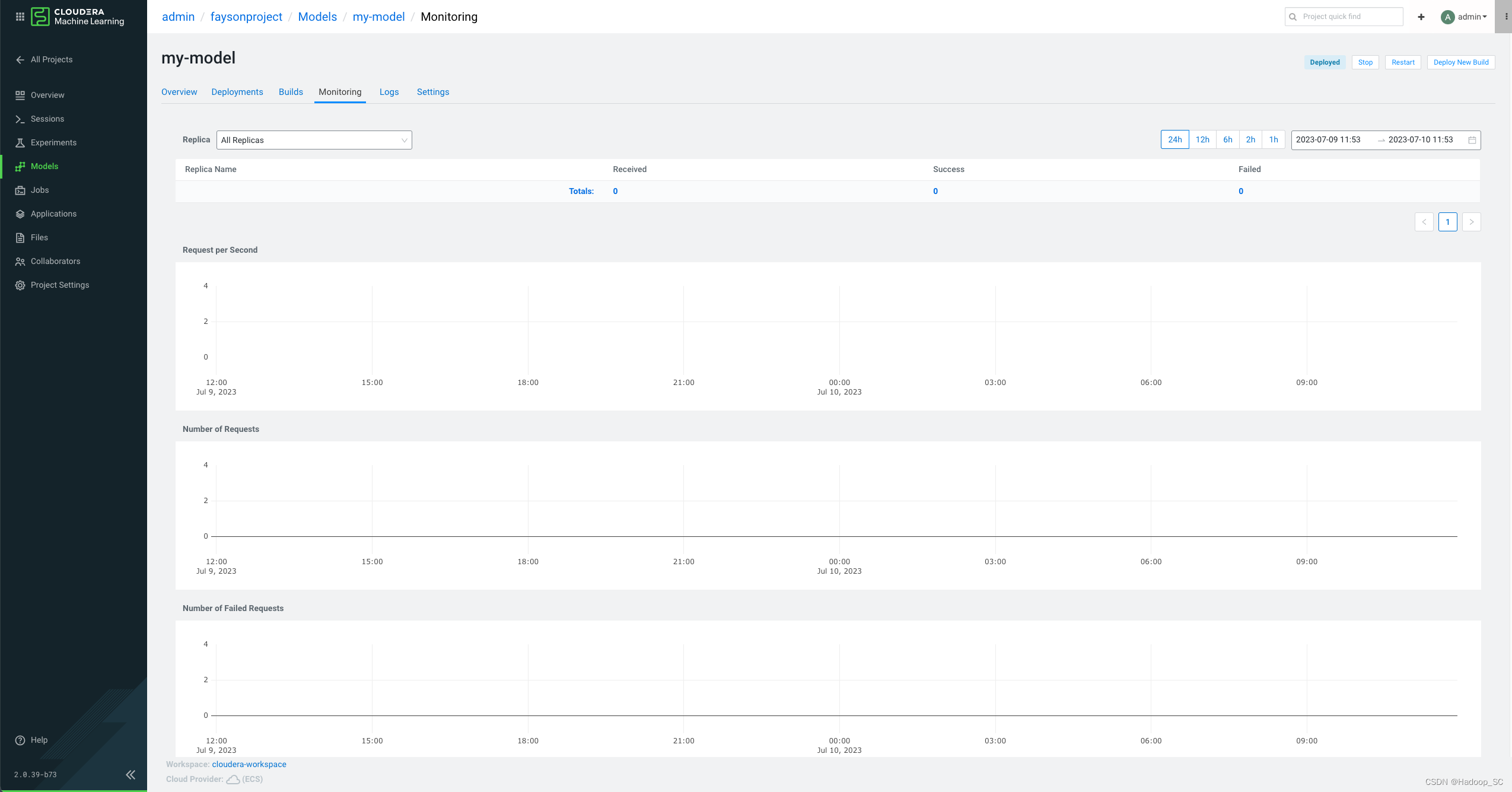
点击“Monitoring”,查看模型监控信息,有模型API接口请求响应的各项指标监控图表
点击“Logs”,查看模型部署的运行日志

点击“Settings”,可以对模型进行配置
4. 模型部署成功后,显示如下
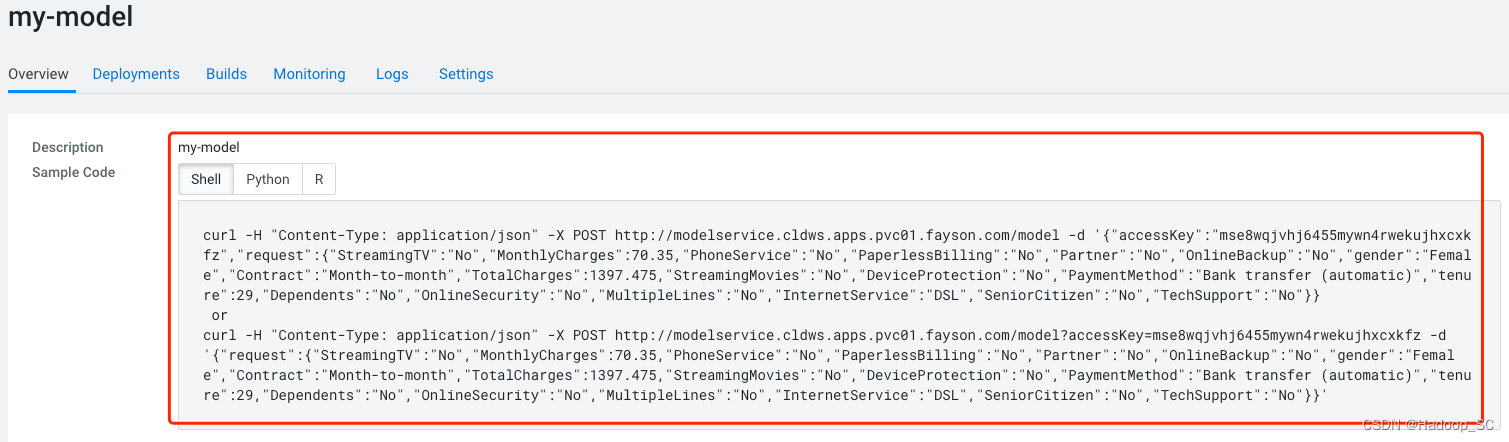
回到“Overview”页面,可以看到有提供shell、python和R的访问代码
在命令行执行提供的shell命令测试是否能够正常访问

到此为止本章节实操结束。
5.6 应用程序部署
在本实验中,指引大家创建一个应用程序,与5.5章节部署的模型结合形成一个完整的应用场景链路。允许业务用户、非数据科学家用户进行交换并深入了解这些分析的背景。
- 点击Project左侧的“Applications”菜单

此时该Project下未部署任何Application应用程序。 - 回到Project的Overview页面,6_application.py文件未本次提供的后台示例代码
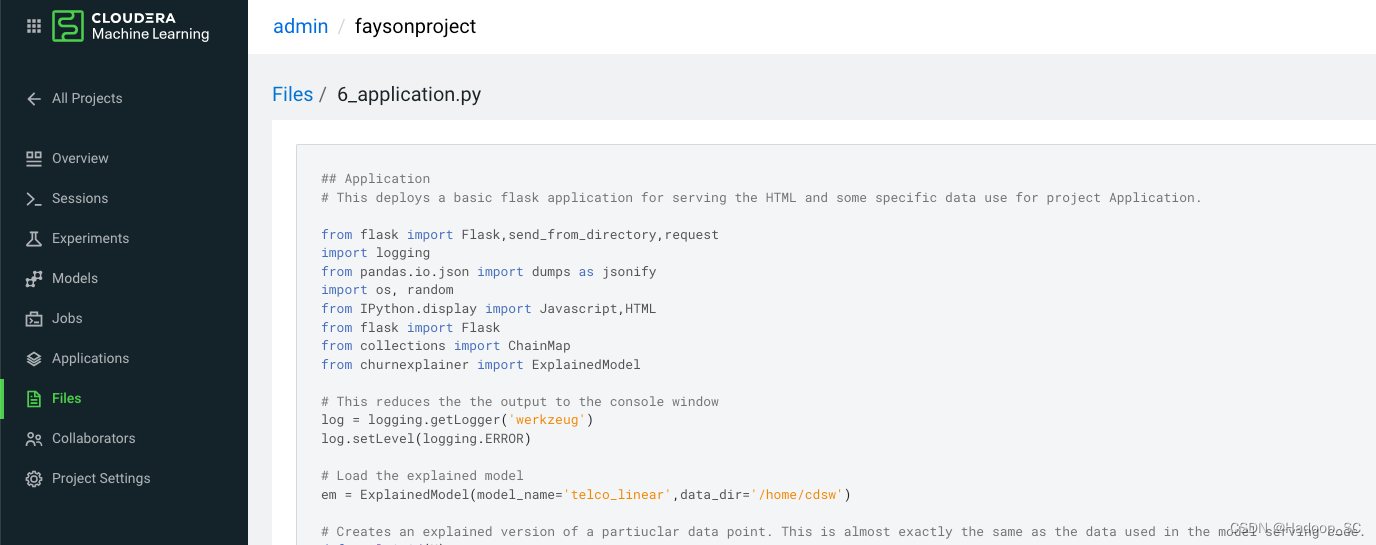
在后端代码中找到前端加载的静态页面地址
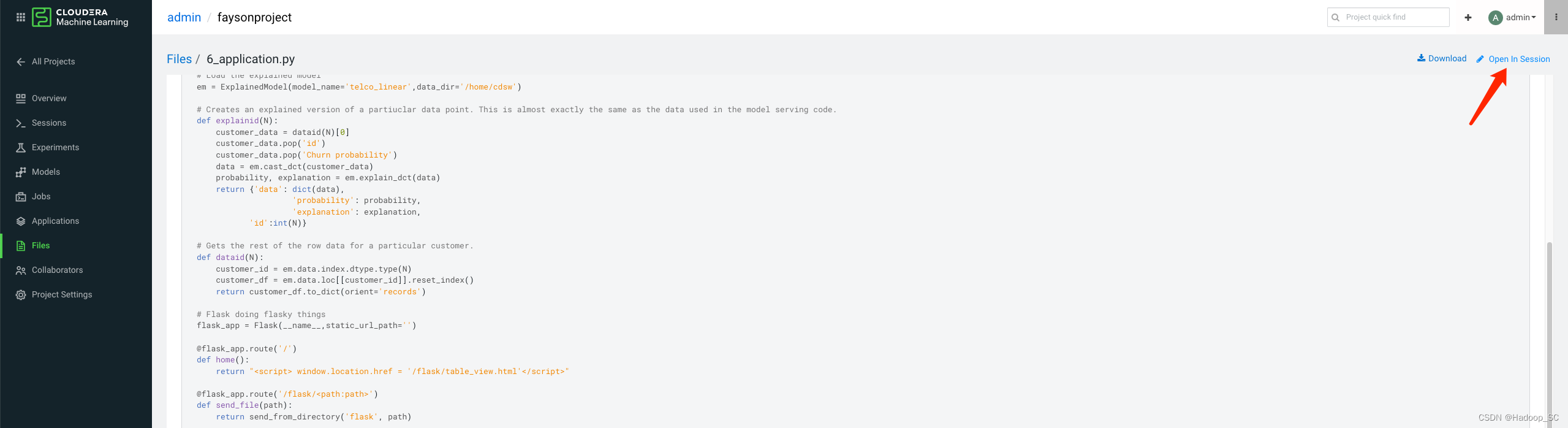
- 点击“Open In Session”,不需要启动Session即可,进入到如下页面编辑html配置
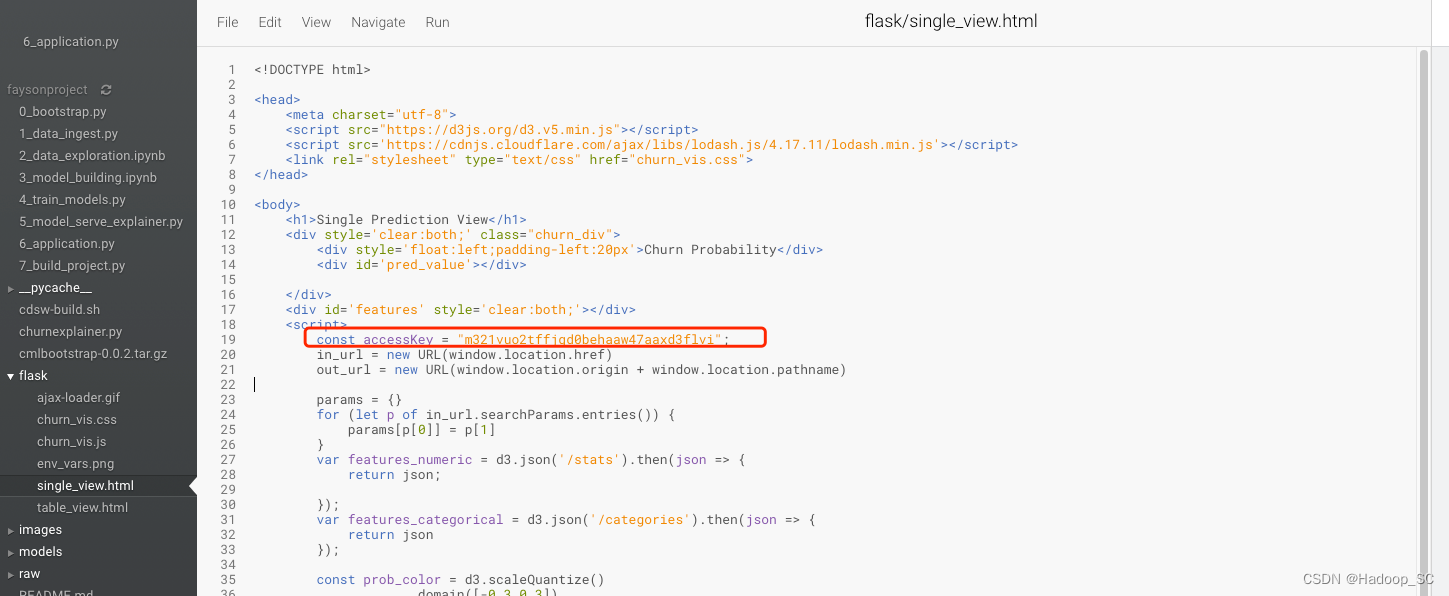
打开flask/single_view.html静态页面,将自己部署模型的Access key替换掉静态页面里面默认的key
- 然后返回到Project页面,点击Applications菜单,进入创建应用
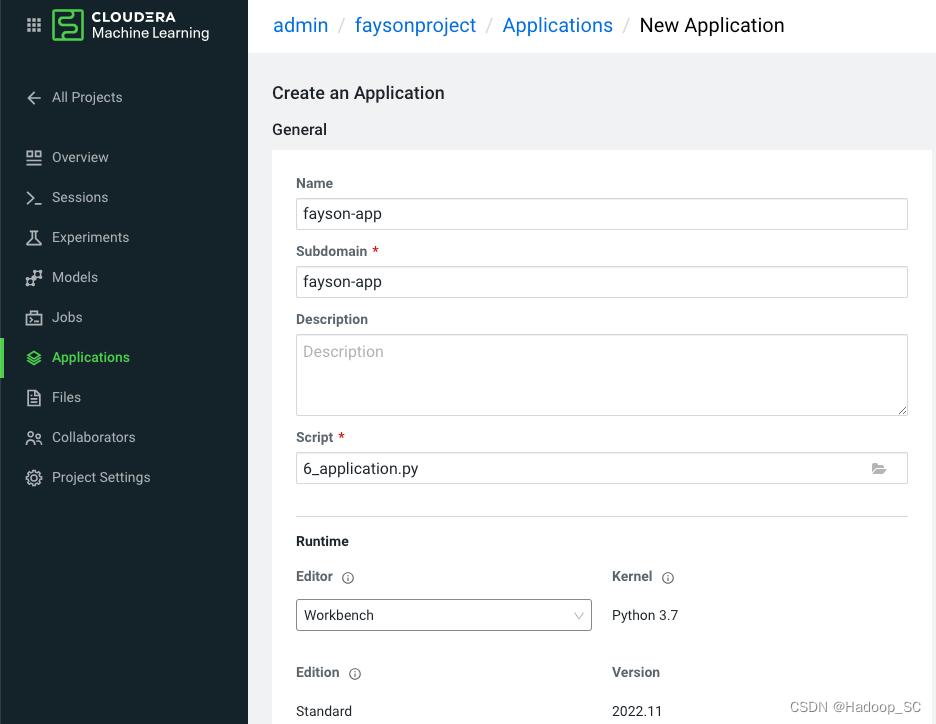
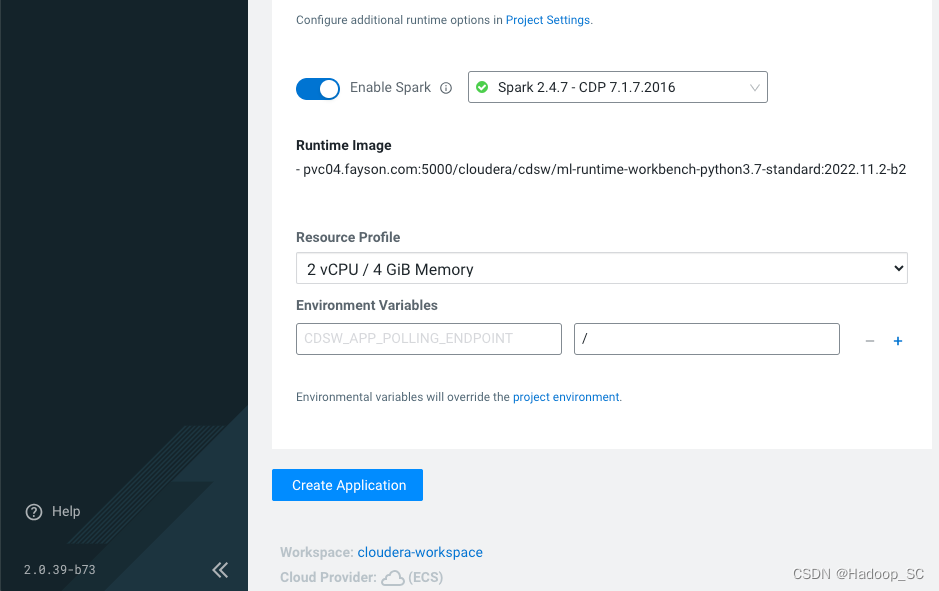
- 点击“Create Application”按钮创建应用
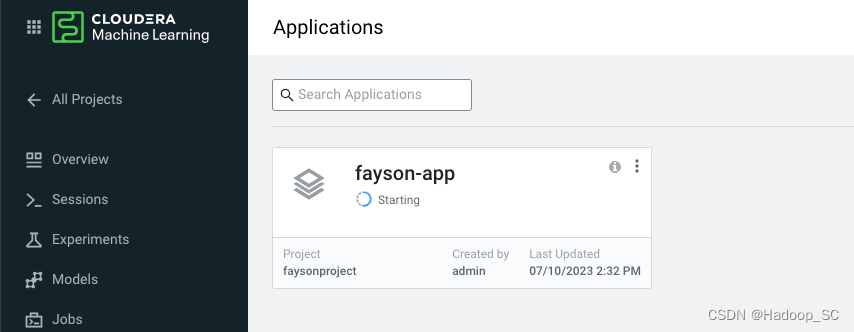
等待应用状态成Running则表示应用创建成功
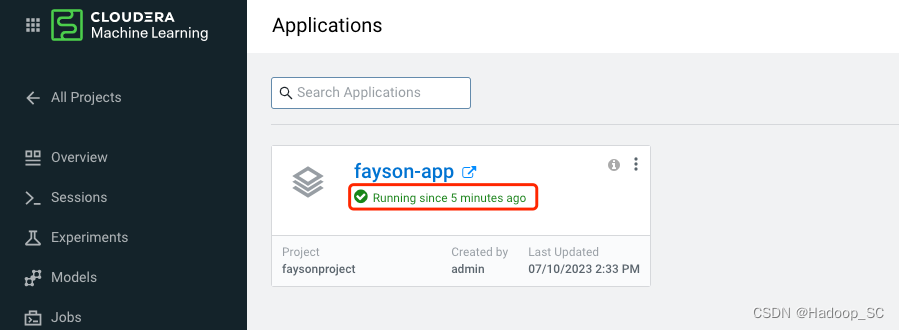
- 点击“fayson-app”打开一个web页面
等待数据加载成功后显示如下表格

点击“Probability”对应的cell概览数据,获取详细信息

如果我们修改某些值,可以通过5.5部署的模型来重新预测更新流失率
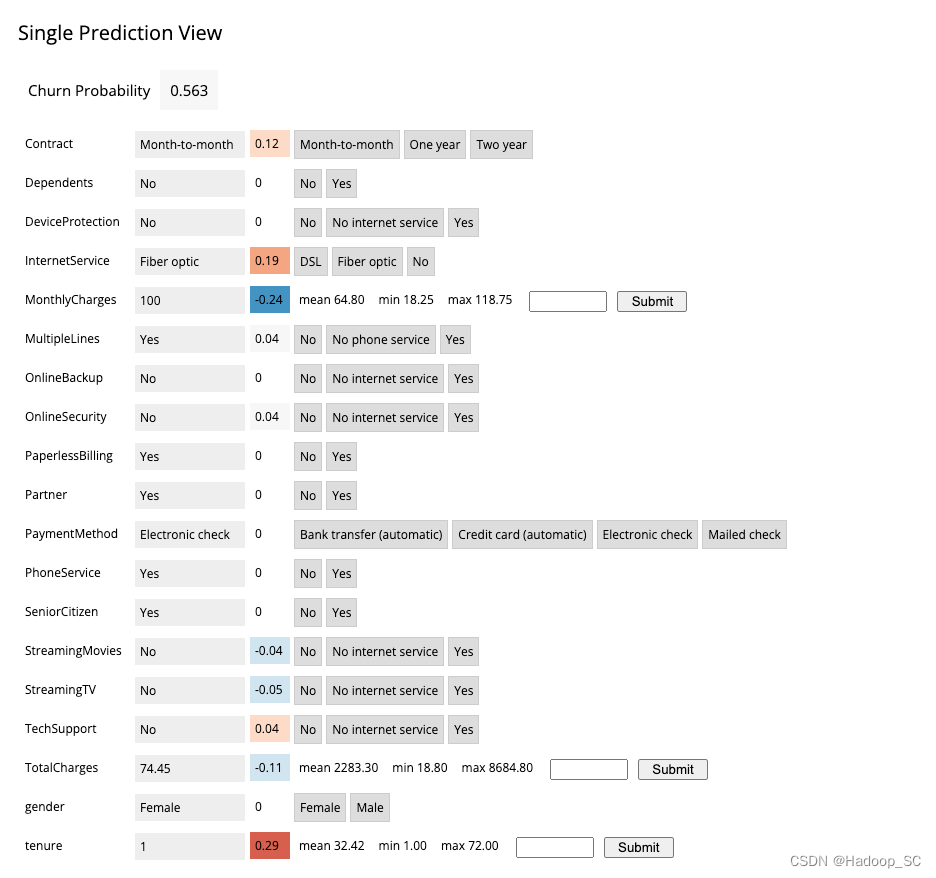
到此为止本章节的应用程序部署实操结束。














 1986
1986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









