







1.nutch中文分词
Nutch对中文查询时默认采用的分词器为NutchAnalyzer,对中文默认采用单字切分.这种效果不是很理想,我们可以自定义切词器,以实现对中文支持.
可以采用的两种方式添加对中文的支持.
1. 直接修改nutch的系统代码,对默认的分词器代码进行修改
使其使用自定义中文分词程序.
2. 采用插件的方式,不修改系统代码的基础上,编写中文分词插件实现对中文
分词的支持。类似我们在nutch的系统中看到的关于法语和德语解析的插件
进行分词解析。
通过修改代码的方式实现对中文的支持,可以看到很多文章介绍.常见的方式类似
而在nutch的系统设计中,采用插件的方式,可以在不修改系统代码的基础上即可实现
多语言支持功能.我们只需要编写对应的插件部署在系统下即可.
2.实现中文分词插件步骤
2.1 插件流程
当我们对一个插件进行解析时,首先会根据文档内容获取对应的分词解析器.
这里我们可能有疑问,根据文档内容如何获取对应的分词解析器.这里用到
另一个插件languageidentifier 语言标示插件,可以通过这个插件获取当前文
档所属的语言,在每个文档上会添加一个lang的属性.
NutchAnalyzer analyzer = factory.get(doc.get("lang"));
Factory 为AnalyzerFactory会根据不同的语言获取切词器而这里的lang属性则通过
Languageidentifier
我们可能会产生另一个问题,Languageidentifier如何知道当前文档语言类别呢?
在这里我们首先查看下
src/plugin/languageidentifier 文件结构
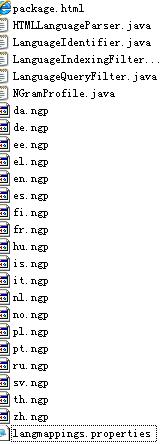
我们可以看到有很多ngp为扩展名的文件,插件正是通过这些ngp文件来判断文档的语言类型对于中文的我生成的文件为zh.ngp这个文件名代表是解析中文文档使用的ngp关于对应的语言产生的文件信息。可以通过langmappings.properties中定义的信息,可以扩展更多国家的语言支持.ngp文件的生成,可以参看这里.有比较详细的介绍.
2.2 建立插件类
我们在这里建立的插件类,很简单。调用的分词器直接用lucene2.0中的CJKAnalyer
具体代码如下.
 package org.apache.nutch.analysis.zh; // JDK importsimport java.io.Reader; // Lucene importsimport org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.TokenStream; // Nutch importsimport org.apache.nutch.analysis.NutchAnalyzer;
package org.apache.nutch.analysis.zh; // JDK importsimport java.io.Reader; // Lucene importsimport org.apache.lucene.analysis.Analyzer;import org.apache.lucene.analysis.TokenStream; // Nutch importsimport org.apache.nutch.analysis.NutchAnalyzer; 
 /** *//**
/** *//** * A simple Chinese Analyzer that wraps the Lucene one. * @author sy zhang
* A simple Chinese Analyzer that wraps the Lucene one. * @author sy zhang */public class CJKAnalyzer extends NutchAnalyzer ...{ private final static Analyzer ANALYZER = new org.apache.lucene.analysis.cjk.CJKAnalyzer();
*/public class CJKAnalyzer extends NutchAnalyzer ...{ private final static Analyzer ANALYZER = new org.apache.lucene.analysis.cjk.CJKAnalyzer(); 
 /** *//** Creates a new instance of CJKAnalyzer */ public CJKAnalyzer() ...{ } public TokenStream tokenStream(String fieldName, Reader reader) ...{ return ANALYZER.tokenStream(fieldName, reader);
/** *//** Creates a new instance of CJKAnalyzer */ public CJKAnalyzer() ...{ } public TokenStream tokenStream(String fieldName, Reader reader) ...{ return ANALYZER.tokenStream(fieldName, reader); } /**//* * it's only for test */ public static void main(String[] args) throws Exception ...{ Analyzer analyzer = new CJKAnalyzer(); String fieldName ="test"; String test="这是一个简单测试this is a cjk test"; char[] testArray =test.toCharArray(); java.io.Reader r = new java.io.CharArrayReader(testArray); TokenStream t = analyzer.tokenStream(fieldName, r); org.apache.lucene.analysis.Token token =null; try ...{ token = t.next(); } catch(Exception ex) ...{ } while(token!=null) ...{ System.out.println(token.termText()); try ...{ token = t.next(); } catch(Exception ex) ...{ } } r.close(); }}
} /**//* * it's only for test */ public static void main(String[] args) throws Exception ...{ Analyzer analyzer = new CJKAnalyzer(); String fieldName ="test"; String test="这是一个简单测试this is a cjk test"; char[] testArray =test.toCharArray(); java.io.Reader r = new java.io.CharArrayReader(testArray); TokenStream t = analyzer.tokenStream(fieldName, r); org.apache.lucene.analysis.Token token =null; try ...{ token = t.next(); } catch(Exception ex) ...{ } while(token!=null) ...{ System.out.println(token.termText()); try ...{ token = t.next(); } catch(Exception ex) ...{ } } r.close(); }}
2.3 建立插件配置信息
我们需要建立一个插件信息xml文件默认为plugin.xml。在这里定义了插件名称,位置
调用中需要一些类信息等.具体信息如下:
<
property
>
<
name
>
plugin.includes
</
name
>
<
value
>
...|analysis-(zh)|...
</
value
>
...
</
property
>
2.4 插件使用
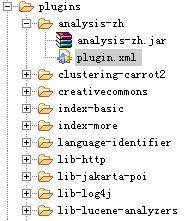
1. 我们通过在源码系统目录下的build.xml差生一个analysis-zh文件夹其中包含analysis-zh.jar和plugin.xml文件.在部署的时将此复制到plugin目录下即可。这样我们的插件系统开发基本完成.如下图.
2. 在使用过程中和其他插件方式类似
我们需要修改nutch-site.xml下的plugin.includes如下
可以在这里添加其他语言类插件.
3. 小结
关于此插件的实现是一个非常简单的中文插件实现的例子.基本上参看法语和德语解析的例子.写的代码也非常少,当然如果对中文分词很好的支持,我们需要定义算法更好一些的分词解析程序。基本的流程还是一样。
感觉nutch的插件系统设计还是比较灵活,我们不用关心系统内核实现,只需要实现我们需要的功能配置到系统中即可.
这个按现在nutch系统的目录结构编写,看能否提交到nutch的plugin中,还不知道怎么提交上去。知道的朋友帮介绍下步骤.先谢了.:)















 1896
1896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









