






前言
作为背井离乡的打工人,一到节假日经常要买火车票乘车回家。很多时候我们都买不到直达的车票,需要中转换乘。
火车的车站、车次等信息可以天然形成一个图结构,将火车车站车次信息入图,借助图数据库可以更方便地查询中转换乘方案。
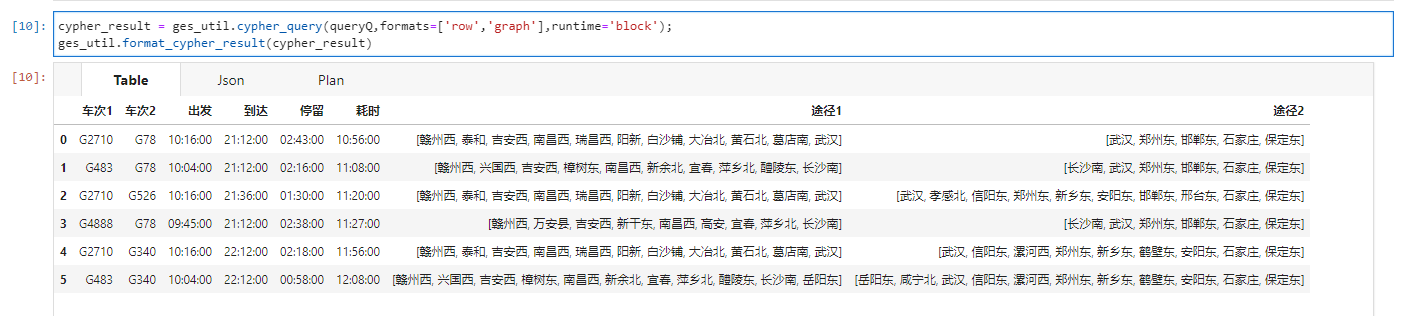
如上图所示是使用GES图数据库查询赣州西到保定东的部分换乘车次。
注: 本文同步发布至华为云AI Gallery,文中所有代码皆可以在AI Gallery上运行:使用图引擎GES查询列车换乘方案。
数据准备
数据获取
本文不提供数据获取方案,全国火车车次等信息可以通过公开渠道获取,本文通过知乎文章《火车最快中转方案搜索软件,支持多次中转、前K最短路径》中提供的链接,下载了列车时刻表.txt等车站车次信息,并进行了数据处理。如果你也下载了相同的数据,可以放在jupyter的train_raw_data目录下,下面将简述数据处理的过程。
数据建模
为了导入图数据库,需要定义一下车次数据的schema信息,我们使用如图所示结构来描述schema。
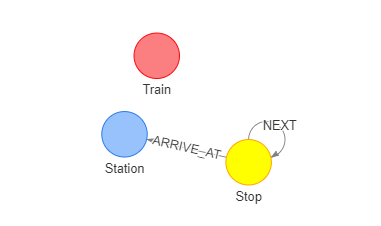
如图,定义火车站(Station)、火车到达(Stop)以及火车(Train)三种类型的节点,Stop节点代表列车的一次到达,每次到达都关联着一个车站。例如,对于C7714次车,其在图中是下列各式。
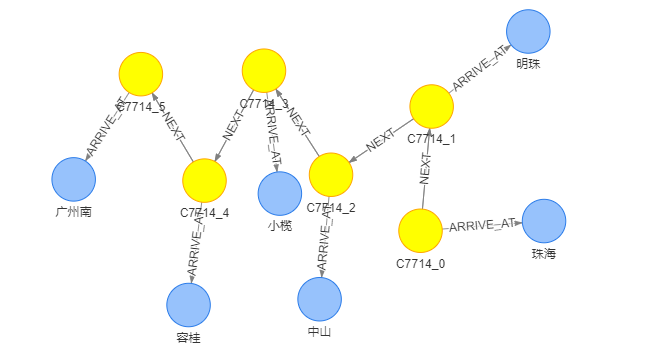
这样可以查询两个车站之间是否关联着连续的Stop节点,来查询两个城市之间是否有直达列车,通过(:Stop)–(:Station)–(:Stop)这样的Pattern,来描述一次换乘。
具体schema附在文末。
数据处理
数据处理的过程就是从原始数据中将车站、车次、列车等信息抽取出来。首先抽取车站信息:
mkdir -p graph_data/edge
mkdir -p graph_data/vertex
def read_files(path,skip_comment=False, skip_header=False):
space_read = True if not skip_comment else False
header_read = True if not skip_header else False
with open(path, 'r') as f:
for line in f.readlines():
if not header_read:
header_read = True
continue
if not space_read:
if line == "\n":
space_read = True
continue
yield line
with open("graph_data/vertex/station.csv","w") as f:
for line in read_files("train_raw_data/火车站经纬度.txt",False, True):
names = line.split("\t")
pos = names[1].split(",")
f.write(names[0]+",Station,"+names[0]+","+pos[0]+","+pos[1])
而后定义一系列数据结构,将车次信息写在内存里。
class Stop:
def __init__(self, station, arrives, departs):
self.station = station
self.arrives = arrives
self.departs = departs
class Train:
def __init__(self, trainNo):
self.trainNo = trainNo
self.stops = list()
currentTrain = None
trainList = list()
for line in read_files("train_raw_data/列车时刻表.txt",True, False):
names = line.split("\t")
if len(names) == 1:
if currentTrain is not None and len(currentTrain.stops) > 0:
trainList.append(currentTrain)
currentTrain = Train(names[0].strip())
else:
currentTrain.stops.append(Stop(names[0].strip(), names[1].strip(), names[2].strip()))
if currentTrain is not None and len(currentTrain.stops) > 0:
trainList.append(currentTrain)
最后生成车次相关的点集合。
with open("graph_data/vertex/train.csv","w") as f:
for x in trainList:
f.write(x.trainNo.strip() + ",Train," + x.trainNo.strip()+"\n")
with open("graph_data/vertex/stop.csv","w") as f:
count = 0
for t in trainList:
trainNo = t.trainNo.strip()
idx = 0
for s in t.stops:
dep = True if idx == 0 else False
arr = True if idx == len(t.stops) - 1 else False
arrive_time = "1970-01-01 " + s.arrives + ":00"
depart_time = "1970-01-01 " + s.departs + ":00"
f.write(trainNo + "_" + str(idx)+",Stop,"+ arrive_time + "," + depart_time + ","+ ("true" if dep else "false") + ","+ ("true" if arr else "false") + "," + trainNo + "," + s.station + "\n")
idx = idx + 1
count = count + 1
以及车次相关的边集合。
with open("graph_data/edge/next.csv","w") as f:
for t in trainList:
trainNo = t.trainNo
for s in range(0, len(t.stops) - 1):
f.write(trainNo + "_" + str(s) + "," + trainNo + "_" + str(s + 1) + ",NEXT\r\n")
with open("graph_data/edge/arrive_at.csv","w") as f:
for t in trainList:
trainNo = t.trainNo
idx = 0
for s in t.stops:
f.write(trainNo + "_" + str(idx) + "," + s.station + ",ARRIVE_AT\r\n")
idx = idx + 1
这样我们就得到了所需的图的原始数据格式。
创图和数据导入
下面将使用华为云图数据库 GES 对以上数据集进行探索和演示,需要将上述数据集上传至OBS、在GES 中创图并将刚刚生成的数据集导入。详细指导流程可参见华为图引擎文档-快速入门和华为云图引擎服务 GES 实战——创图。
数据探索
依赖的软件包
首先通过moxing包从对象存储服务obs中下载ges4jupyter。ges4jupyter是jupyter连接GES服务的工具文件。文件中封装了使用 GES 查询的预置条件,包括配置相关参数和对所调用 API 接口的封装,如果你对这些不感兴趣,可直接运行而不需要了解细节,这对理解后续具体查询没有影响。
import moxing as mox
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/ges4jupyter.py', 'ges4jupyter.py')
mox.file.copy('obs://obs-aigallery-zc/GES/ges4jupyter/beta/ges4jupyter.html', 'ges4jupyter.html')
GESConfig的参数都是与调用 GES 服务有关的参数,依次为“公网访问地址”、“项目ID”、“图名”、“终端节点”、“IAM 用户名”、“IAM 用户密码”、“IAM 用户所属账户名”、“所属项目”,其获取方式可参考调用 GES 服务业务面 API 相关参数的获取。这里通过read_csv_config方法从配置文件中读取这些信息。如果没有配置文件,可以根据自己的需要补充下列字段。对于开启了https安全模式的图实例,参数port的值为443。
from ges4jupyter import GESConfig, GES4Jupyter, read_csv_config
eip = ''
project_id = ''
graph_name = ''
iam_url = ''
user_name = ''
password = ''
domain_name = ''
project_name = ''
port = 80
eip, project_id, graph_name, iam_url, user_name, password, domain_name, project_name, port = read_csv_config('local.csv')
config = GESConfig(eip, project_id, graph_name,
iam_url = iam_url,
user_name = user_name,
password = password,
domain_name = domain_name,
project_name = project_name,
port = port)
ges_util = GES4Jupyter(config, False);
查询对应列车车次
可以使用GES Cypher语言方便的检索两个站点之间的车次,例如,可以发送Cypher语句,检索北京南到杭州之间的车次。
cypher_result = ges_util.cypher_query("""
match (n:Station)<-[:ARRIVE_AT]-(s:Stop) where id(n) in ['北京南']
match p=(s)-[:NEXT*1..30]->(s1) with s,s1,p
where s1.station contains '杭州'
return s.trainNo as `车次`, subString(toString(s.arrives),11) as `出发`,subString(toString(s1.departs),11) as `到达`,subString(toString(datetime(timestamp(s1.departs) - timestamp(s.arrives))),11) as `耗时`, [x in nodes(p)|x.station] as `途径`
""",formats=['row','graph']);
ges_util.format_cypher_result(cypher_result)
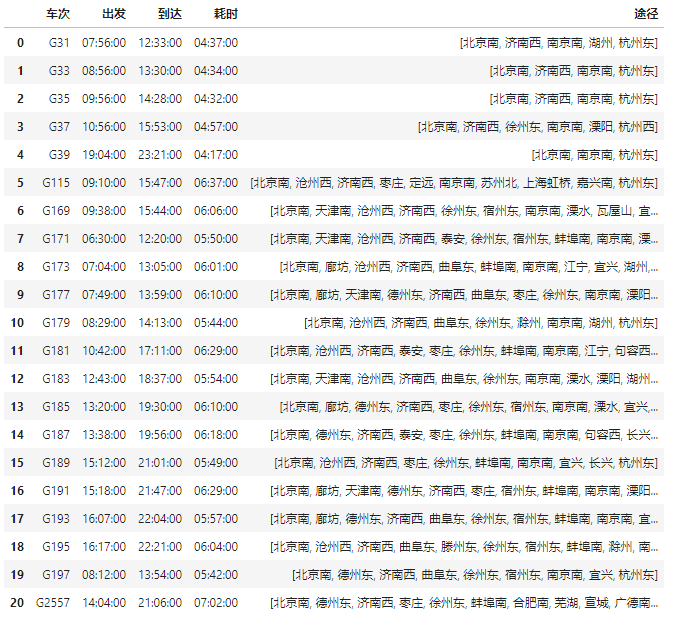
也可以检索从某个车站出发,可以直达哪些车站。比如检索下前段时间比较火的淄博(为了展示效果取了limit)。
cypher_result = ges_util.cypher_query("""
match (n:Station)<-[:ARRIVE_AT]-(s:Stop)
where id(n) in ['淄博','淄博北']
match p1=(s)-[:NEXT*1..30]->(s1) return distinct s1.station limit 10
""",formats=['row','graph']);
ges_util.format_cypher_result(cypher_result)

查询列车中转换乘
有多种方式查询中转换乘,这里介绍两种:
- 构造特殊的边表示换乘
目前不同Stop之间通过Label为NEXT的边连接,NEXT边连接的两个Stop代表同一列列车。可以根据换乘条件构造一些Label为TRANSFER的边,这样上文中的cypher语句就可以写作:
match (n:Station)<-[:ARRIVE_AT]-(s:Stop) where id(n) in ['北京南']
match p=(s)-[:NEXT|:TRANSFER*1..30]->(s1) with s,s1,p
where s1.station contains '杭州'
return s.trainNo as `车次`, subString(toString(s.arrives),11) as `出发`,subString(toString(s1.departs),11) as `到达`,subString(toString(datetime(timestamp(s1.departs) - timestamp(s.arrives))),11) as `耗时`, [x in nodes(p)|x.station] as `途径`
具体来说,需要定义一些换乘条件,例如:
- 需要限定在哪些车站换乘,如果是所有车站,可能对图的改动较多。
- 换乘有哪些时间限制,如上一班车到达时间早于下一班车发车时间,中间间隔多久?一般来说要大于15分钟才预留有足够的时间。
由于这种方法比较依赖具体线路,如果不依赖具体线路,对所有车站建边会导致数据量膨胀,所以本文暂不尝试。
- 使用查询语言描述换乘
使用查询语言可以方便的描述换乘,但是带来的问题是由于描述换乘需要特定的Pattern,换乘操作在图中被建模为了一个两跳操作,所以查询会比较慢,但是通用性高。本文使用这种方法来描述换乘。
这里查询一下知乎文章中赣州西到保定东之间的换乘路径:
queryQ = """
match (n:Station)<-[:ARRIVE_AT]-(s:Stop)
where id(n) in ['赣州西']
match p1=(s)-[:NEXT*1..15]->(s1) where all(x in nodes(p1) where not x.station contains '保定东')
match (s1)-[ARRIVE_AT]->(m:Station)<-[:ARRIVE_AT]-(s2:Stop) where s1.departs < s2.arrives
match p2=(s2)-[:NEXT*1..15]->(s3) where all(x in nodes(p2) where not x.station contains '赣州西') and s3.station contains '保定东' and timestamp(s2.departs) - timestamp(s1.arrives) >= 900
with
s1.trainNo as `车次1`,
s2.trainNo as `车次2`,
subString(toString(s.arrives),11) as `出发`,
subString(toString(s3.departs),11) as `到达`,
subString(toString(datetime(timestamp(s2.departs) - timestamp(s1.arrives))),11) as `停留`,
subString(toString(datetime(timestamp(s3.departs) - timestamp(s.arrives))),11) as `耗时`,
[x in nodes(p1)|x.station] as `途径1`,
[x in nodes(p2)|x.station] as `途径2`
where `耗时` <> '00:00:00'
return `车次1`,`车次2`,`出发`,`到达`,`停留`,`耗时`,`途径1`,`途径2` order by `耗时`"""
cypher_result = ges_util.cypher_query(queryQ,formats=['row','graph']);
ges_util.format_cypher_result(cypher_result)

可以得到和文章《火车最快中转方案搜索软件,支持多次中转、前K最短路径》中一样的结果,同样比12306官网的快。
附录:
使用的schema(也可到链接使用华为图引擎GES查询列车中转换乘-schema 进行下载):
<?xml version="1.0" encoding="ISO-8859-1"?>
<PMML version="3.0"
xmlns="http://www.dmg.org/PMML-3-0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema_instance" >
<labels>
<label name="default">
</label>
<label name="Station">
<properties>
<property name="name" cardinality="single" dataType="string"/>
<property name="x" cardinality="single" dataType="float"/>
<property name="y" cardinality="single" dataType="float"/>
</properties>
</label>
<label name="Location">
<properties>
<property name="name" cardinality="single" dataType="string"/>
</properties>
</label>
<label name="Stop">
<properties>
<property name="arrives" cardinality="single" dataType="date"/>
<property name="departs" cardinality="single" dataType="date"/>
<property name="departure" cardinality="single" dataType="bool"/>
<property name="terminal" cardinality="single" dataType="bool"/>
<property name="trainNo" cardinality="single" dataType="string"/>
<property name="station" cardinality="single" dataType="string"/>
</properties>
</label>
<label name="Train">
<properties>
<property name="name" cardinality="single" dataType="string"/>
</properties>
</label>
<label name="NEXT">
<properties>
</properties>
</label>
<label name="TRANSFER">
<properties>
</properties>
</label>
<label name="DEPARTURE">
<properties>
</properties>
</label>
<label name="TERMINAL">
<properties>
</properties>
</label>
<label name="ARRIVE_AT">
<properties>
</properties>
</label>
<label name="LOCATED_IN">
<properties>
</properties>
</label>
</labels>
</PMML>


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









