







为什么需要⽆锁队列
锁引起的问题:
Cache损坏(Cache trashing)
在同步机制上的争抢队列
动态内存分配
Cache损坏(Cache trashing)
无锁队列在保存和恢复上下⽂的过程中还隐藏了额外的开销:Cache中的数据会失效,因为它缓存的是将被换出任务的数据,这些数据对于新换进的任务是没⽤的。处理器的运⾏速度⽐主存快N倍,所以⼤量的处理器时间被浪费在处理器与主存的数据传输上。这就是在处理器和主存之间引⼊Cache的原因。Cache是⼀种速度更快但容量更⼩的内存(也更加昂贵),当处理器要访问主存中的数据时,这些数据⾸先被拷⻉到Cache中,因为这些数据在不久的将来可能⼜会被处理器访问。Cache misses对性能有⾮常⼤的影响,因为处理器访问Cache中的数据将⽐直接访问主存快得多。线程被频繁抢占产⽣的Cache损坏将导致应⽤程序性能下降。
在同步机制上的争抢队列
阻塞不是微不⾜道的操作。它导致操作系统暂停当前的任务或使其进⼊睡眠状态(等待,不占⽤任何的处理 器)。直到资源(例如互斥锁)可⽤,被阻塞的任务才可以解除阻塞状态(唤醒)。在⼀个负载较重的应⽤程序 中使⽤这样的阻塞队列来在线程之间传递消息会导致严重的争⽤问题。也就是说,任务将⼤量的时间(睡 眠,等待,唤醒)浪费在获得保护队列数据的互斥锁,⽽不是处理队列中的数据上。 ⾮阻塞机制⼤展伸⼿的机会到了。任务之间不争抢任何资源,在队列中预定⼀个位置,然后在这个位置上 插⼊或提取数据。其中机制使⽤了⼀种被称之为CAS(⽐较和交换)的特殊操作,这个特殊操作是⼀种特殊的 指令,它可以原⼦的完成以下操作:它需要3个操作数m,A,B,其中m是⼀个内存地址,操作将m指向的 内存中的内容与A⽐较,如果相等则将B写⼊到m指向的内存中并返回true,如果不相等则什么也不做返回 false。
动态内存分配
在多线程系统中,需要仔细的考虑动态内存分配。当⼀个任务从堆中分配内存时,标准的内存分配机制会阻 塞所有与这个任务共享地址空间的其它任务(进程中的所有线程)。这样做的原因是让处理更简单,且它⼯作 得很好。两个线程不会被分配到⼀块相同的地址的内存,因为它们没办法同时执⾏分配请求。显然线程频 繁分配内存会导致应⽤程序性能下降(必须注意,向标准队列或map插⼊数据的时候都会导致堆上的动态内存 分配)动态内存分配 在多线程系统中,需要仔细的考虑动态内存分配。当⼀个任务从堆中分配内存时,标准的内存分配机制会阻 塞所有与这个任务共享地址空间的其它任务(进程中的所有线程)。这样做的原因是让处理更简单,且它⼯作 得很好。两个线程不会被分配到⼀块相同的地址的内存,因为它们没办法同时执⾏分配请求。显然线程频 繁分配内存会导致应⽤程序性能下降(必须注意,向标准队列或map插⼊数据的时候都会导致堆上的动态内存 分配)
无锁队列的实现
首先,无锁队列并不是真正意义上的无锁,是在原子操作的条件下完成的队列的读写。避免了线程陷入内核态。
一读一写无锁队列实现(参考zmq的无锁队列实现)
zmq实现了队列queue_t (队列) pipe_t(对queue_t 读写的封装)
其中queue_t 的实现:
queue_t 有一个结构:
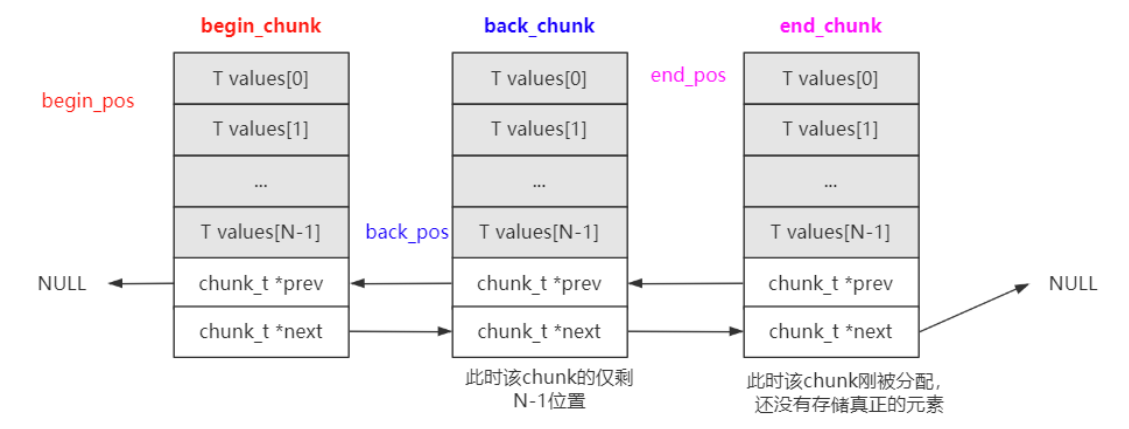
yqueue_t内部有三个chunk_t类型指针以及对应的索引位置:
begin_chunk/begin_pos:
begin_chunk 用于指向队列头的chunk,begin_pos 用于指向队列第一个
元素在当前chunk中的位置。
back_chunk/back_pos:
back_chunk 用于指向队列尾的chunk,back_pos 用于指向队列最后一个元素在当前chunk的位置。
end_chunk/end_pos:
由于chunk是批量分配的,所以end_chunk⽤于指向分配的最后一个chunk位置。
pipe_t是对queue_t的读写封装,
主要有几个要注意的:基本的代码阅读应该好理解,就是有一个函数比较难理解
ypipe_t 的实现:
写入的过程

取出队列的尾部,然后调用push,这里很简单,如果是完成则要刷新f指针

刷新数据,只有刷新了数据,读线程才能读取得到。
如果w=f: 说明没有push数据,因为push完成f指针会移动
否则:尝试将c=f指针,
如果c不等于w,说明c原来的值为null,说明读线程挂起,这时候要可以直接更新c=f,w=f,返回false让写线程通知读线程可读
否则:直接更新w=f,return true;
读取的过程

如果指针r指向的是队头元素(r==&queue.front())或者r没有指向任何元素(NULL)则说明队列中并没有可读的数据,下一步
进入尝试去预取数据。预取就是令 r=c,⽽c在write中被指向f,这时从queue.front()到f这个位置的数据将被预取出来。

如果已经预取,每次调⽤read都能取出⼀个数据,这时不会触发原子锁操作。
当预取不到数据,线程睡眠,等待写线程写入发送信号来触发读操作。
测试代码:
测试代码实现:
单独线程压入队列
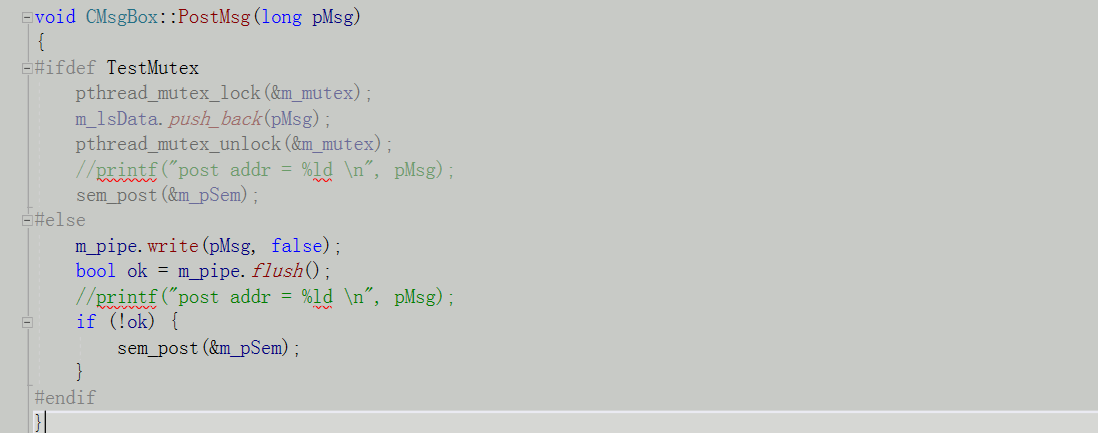
单线程读取:
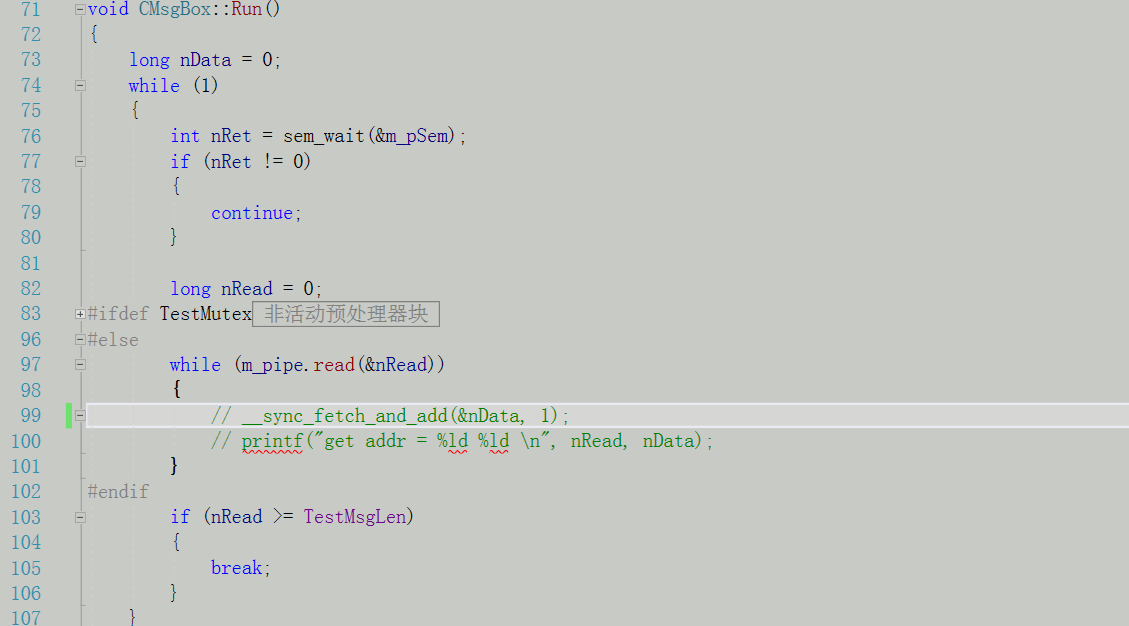
具体实现源码后续会更新到gitee















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









