






1.1 Spark:超越Hadoop MapReduce的一步
本节讨论与Spark和图相关的大数据。大数据是数据科学团队面临的主要挑战,部分原因是单个机器不太可能具有以所需规模运行处理的能力和能力。此外,即使是为大数据设计的系统(如Hadoop)也可能由于该数据的某些特点而无法有效地处理图数据,本章稍后会介绍。
Apache Spark与Apache Hadoop类似,因为它存储将数据分布式存储在节点集群上。不同之处在于Apache Spark将数据存储在内存(RAM)中,而Hadoop则将数据存储在磁盘(传统机械硬盘或固态磁盘(SSD))上,如图1.1所示。
定义 当涉及图和集群计算时,单词节点有两个不同的用途。图数据由顶点和边组成,在该上下文中,节点是顶点的同义词。在集群计算中,构成集群的物理机器也称为节点。为了避免混淆,我们将图节点/顶点仅称为顶点,这也是Spark GraphX采用的术语。当我们在本书中使用词节点时,我们的意思是指一个参与集群计算的物理计算机。

除了在计算期间处理数据的区别之外(RAM与磁盘),Spark的API比Hadoop Map Reduce API更容易使用。结合Spark的原生编程语言Scala的简洁性,对于Hadoop Map / Reduce Java代码数量到Spark Scala代码行的比率为100:1是常见的。虽然这本书主要使用Scala,不要担心,如果你不知道Scala。第3章提供了一个快速熟悉Scala的指南,同时伴随着本书的深入,我们会一路解释scala的技巧和神秘的语法。但是,您至少需要熟悉一种编程语言 - 如Java,C ++,C#或Python。
1.1.1大数据定义
大数据的概念如今被大肆炒作,它最早可追溯到2003年google关于GFS的论文,以及2004年关于MapReduce的论文,这些启发了现在的Hadoop的发展。
大数据这个术语现在有很多定义,不过它最简单的核心概念就一个:数量太大以至于难以存储在单个机器的数据。
数据爆炸的时代,数据来源多种多样:网站点击流,服务器日志,各类传感器日志等等。上述有些数据是图结构的,可以有边和点组成,例如有合作关系的网站。大量图数据被有效地包含在众包中,例如维基百科中包含的互联知识的主体或由Facebook好友,LinkedIn连接或Twitter关注者构成的图。
1.1.2 Hadoop: Spark前的世界
在我们讨论spark之前,我们回顾下Hadoop是如何解决大数据处理问题的。因为spark也是基于Hadoop的核心思想。
Hadoop提供了一个框架来在机器集群上实现容错并行处理。 Hadoop提供了两个关键功能:
l HDFS:分布式存储
l MapReduce:分布式计算
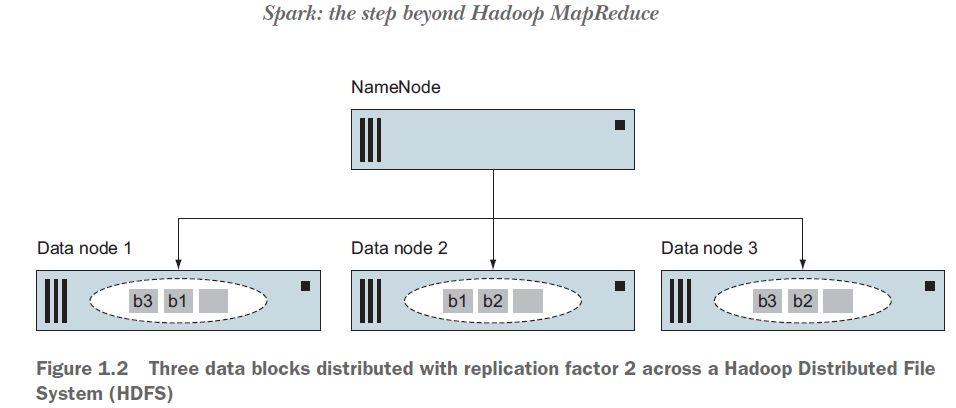
HDFS提供分布式容错存储。 NameNode将单个大文件分割为一个个小的块。典型的块大小为64 MB或128 MB。块分散在集群中的计算机上。通过将文件的每个块复制到多个节点(默认为三个,但为了使图更简单,图1.2为复制到两个节点的情况)提供了容错。如果某个节点失败,则该节点上的所有文件块都不可用,其他节点可以无缝地提供丢失的块,整个过程对上层应用透明。这是Hadoop架构中的一个关键思想:将机器故障作为正常操作的一部分。
MapReduce(见图1.3)是提供并行和分布式计算的Hadoop并行处理框架。MapReduce允许程序员编写一段代码,封装在map和reduce函数中,这些函数对存储在HDFS上的数据集进行操作。为了实现数据本地化处理特性(data locality),将代码(以.jar形式)发送到数据节点,并在那里执行Map。这避免了消耗网络带宽来在集群间传输数据。然而,对于Reduce操作,需要将Map的结果传输到一些Reduce节点,并进行reduce处理(这被称为shuffling)。并行性主要在Map期间实现。同时Hadoop还提供操作容错机制,如果某个节点或进程失败,则计算可以在另一台节点上重新启动。
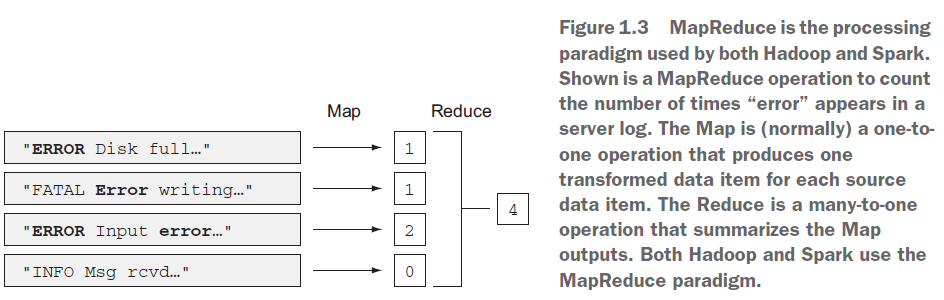
MapReduce编程框架将数据集抽象为要处理的键值对数据流,并将输出写回HDFS。这是一个有限的范式,但是通过将多个MapReduce读-处理-写操作链接起来,它已被用于解决许多数据并行问题。一些简单的任务,如图1.3中的计数(word count),就受益于这种方法。但是像机器学习这种需要大量迭代的算法则不适用,这也是Spark改进的部分。
1.1.3 Spark: 基于内存的MapReduce处理
本节讨论一个可替代Hadoop的分布式处理系统,Spark,它建立在Hadoop基础之上。在本节中,您将了解弹性分布式数据集(RDD),它们在Spark如何表示图数据方面发挥了重要作用。
Hadoop有以下几个缺陷:
l 交互式查询
l 迭代算法
Hadoop适用于对大型数据集运行单个查询,但在许多情况下,一旦我们有了一个查询结果,我们马上需要再进行一次查询,这被称为交互式查询。使用Hadoop,这意味着需要从磁盘重新加载数据并再次处理它。
迭代算法在机器学习中很普遍,例如随机梯度下降,以及诸如PageRank的基于图的算法。迭代算法对一组数据集反复计算,直到满足一些标准。在Hadoop中实现这样的算法通常需要一系列MapReduce作业,而每次迭代时都需要加载数据。对于大型数据集,可能会有成百上千次迭代,从而导致运行时间较长。
接下来,您将看到Spark如何解决这些问题。像Hadoop一样,Spark运行在一个服务器集群上。Spark中的关键是弹性分布式数据集(RDD)。RDD由Spark应用程序(驻留在Spark驱动程序中)通过Cluster Manager创建,如图1.4所示。

RDD由称为分区的数据的分布式子集组成,这些分区可以加载到集群上各个节点的内存中。
Spark在内存中执行大部分操作。因为Spark是基于内存的,所以它比Hadoop MapReduce更适合处理图数据,因为Map Reduce依次处理数据,而内存本质上是随机访问。
Spark在交互式查询和迭代处理中的占优势的关键是它在内存中缓存RDD的能力。缓存RDD避免了每次返回结果时重新处理父RDD链的需要。
当然,这意味着为了利用Spark的内存处理,集群中的机器必须有大量的内存。但是如果可用内存不足,Spark会将数据写到磁盘并继续工作。
Spark集群需要一个地方来永久存储数据。它必须是一个分布式存储系统,我们可以选择HDFS,Cassandra和Amazon的S3。















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









