









算法通关村第十四关——堆高效解决的经典问题(白银)
算法通关村第十四关——堆高效解决的经典问题(白银)
1 在数组中找到第K大的元素
这道题是一个非常经典和重要的题目,解决方法主要有三种:
- 选择法(先遍历一遍找到最大的元素,然后再遍历找到第二大,直到找到第K大的元素)
- 快速排序法(前面讲解过了,这里略)
- 堆排序法(找最大用小堆,找最小用大堆,找中间用两个堆)
这个专题那我们肯定是用堆排序法,那我们使用java自带的一个结构PriorityQueue(优先队列)
PriorityQueue 实现的是 Queue 接口 ,可以使用 Queue 提供的方法,以及自带的方法。
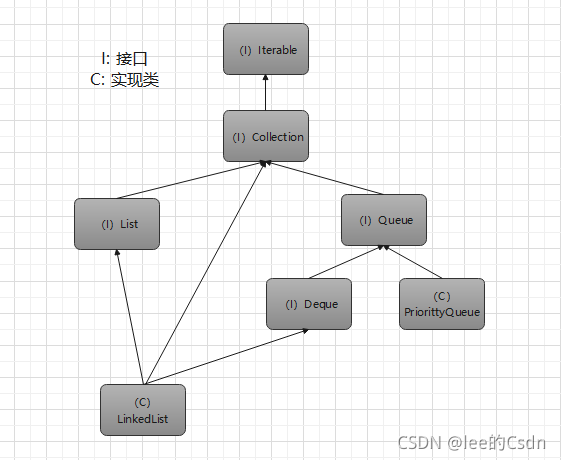
PriorityQueue概述
Java PriorityQueue 实现了 Queue 接口,不允许放入 null 元素;其通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue 的底层实现,数组初始大小为11;也可以用一棵完全二叉树表示。
常用方法总结
public boolean add(E e); //在队尾插入元素,插入失败时抛出异常,并调整堆结构
public boolean offer(E e); //在队尾插入元素,插入失败时抛出false,并调整堆结构public E remove(); //获取队头元素并删除,并返回,失败时前者抛出异常,再调整堆结构
public E poll(); //获取队头元素并删除,并返回,失败时前者抛出null,再调整堆结构public E element(); //返回队头元素(不删除),失败时前者抛出异常
public E peek();//返回队头元素(不删除),失败时前者抛出nullpublic boolean isEmpty(); //判断队列是否为空
public int size(); //获取队列中元素个数
public void clear(); //清空队列
public boolean contains(Object o); //判断队列中是否包含指定元素(从队头到队尾遍历)
public Iterator iterator(); //迭代器
所以这道题的算法代码:
class Solution {
public int findKthLargest(int[] nums, int k) {
// 创建一个最小堆
PriorityQueue<Integer> minHeap = new PriorityQueue<>();
// 将数组中的前k个元素加入最小堆
for (int i = 0; i < k; i++) {
minHeap.offer(nums[i]);
}
// 遍历数组剩余元素,如果比堆顶元素大则替换堆顶元素,并重新调整堆
for (int i = k; i < nums.length; i++) {
if (nums[i] > minHeap.peek()) {
minHeap.poll();
minHeap.offer(nums[i]);
}
}
// 返回最小堆的堆顶元素,即第k个最大元素
return minHeap.peek();
}
}
2 堆排序原理
查找:找小用大,找大用小
排序:升序用小,降序用大。
前面介绍了如何用堆来进行特殊情况的查找,堆的另一个很重要的作用是可以进行排序,那怎么排的呢?
其实非常简单,我们知道在大顶堆中,根节点是整个结构最大的元素,我先将其拿走,剩下的重排,此时根节点就是第二大的元素,我再将其拿走,再排,依次类推。最后堆只剩一个元素的时候,是不是拿走的数据也就排好序了?具体来说,建堆结束之后,数组中的数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。我们把它跟最后一个元素交换,那最大元素就放到了下标为 n 的位置。
看一个例子,我们对上面第一章的序列 [12 23 54 2 65 45 92 47 204 31]进行排序,首先构建一个大顶堆,然后每次我们都让根元素出堆,剩下的继续调整为大顶堆:
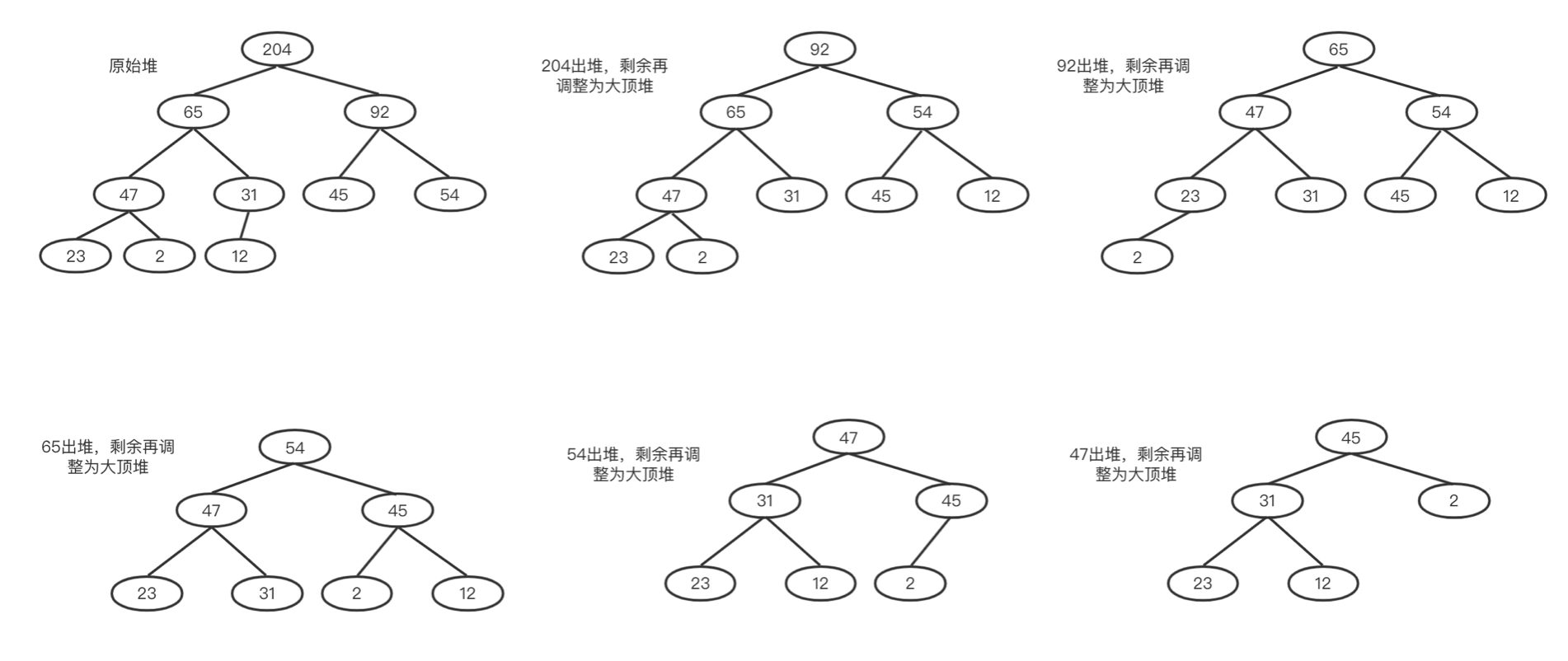
这时候会发现出堆的序列刚好是:204、92、65、54、47、45…。也就是刚好是从大到小的顺序排列的。
所以我们可以明白 ,如果是一个小顶堆,那自然是升序的。所以在排序的时候:
排序:升序用小,降序用大。
这个与前面的查找是相反的。
3 合并K个排序链表
这道题也是很经典的题目,主要的方法有三种:
- 顺序合并(两个链表合并,然后一路按照顺序合并)
- 分治合并(两个两个合并,那么第一遍合并之后剩下2/K个,再进行剩下4/K个,最后完成)
- 大小堆(优先队列合并)
因为每个队列都是从小到大排序的,我们每次都要找最小的元素,所以我们要用小根堆,构建方法和操作与大顶堆完全一样,不同的是每次比较谁更小。 使用堆合并的策略是不管几个链表,最终都是按照顺序来的。每次都将剩余节点的最小值加到输出链表尾部,然后进行堆调整,最后堆空的时候,合并也就完成了。
第一步:创建优先队列,将链表添加到队列中
PriorityQueue<ListNode> q = new PriorityQueue<>(Comparator.comparing(node -> node.val));
for(int i=0; i<lists.length; i++){
if(lists[i] != null){
q.add(lists[i]);
}
}
这里使用了Comparator.comparing()方法来创建一个比较器(Comparator),该比较器定义了如何比较两个节点的值。通过Lambda表达式,您指定了节点的值作为比较的依据。
这个优先队列将会根据链表节点的值来确定节点之间的顺序。当插入新节点时,优先队列会根据节点值的大小自动调整节点的位置。
第二步:创建返回的链表,用虚拟节点
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if(lists == null || lists.length == 0) return null;
PriorityQueue<ListNode> q = new PriorityQueue<>(Comparator.comparing(node -> node.val));
for(int i=0; i<lists.length; i++){
if(lists[i] != null){
q.add(lists[i]);
}
}
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
}
}
第三步:将链表从优先队列取出来,添加,每次添加最小的那个数
class Solution {
public ListNode mergeKLists(ListNode[] lists) {
if(lists == null || lists.length == 0) return null;
PriorityQueue<ListNode> q = new PriorityQueue<>(Comparator.comparing(node -> node.val));
for(int i=0; i<lists.length; i++){
if(lists[i] != null){
q.add(lists[i]);
}
}
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while(!q.isEmpty()){
tail.next = q.poll(); // 取出最小堆的顶,也就是最小的值,添加进去
tail = tail.next; // 移动指针
if(tail.next != null){ // 判断这个链表的节点是否全部添加完
q.add(tail.next); // 如果未添加完,把剩余的链表丢进优先队列,
// 优先队列会进行排序,使最小的值依然在最上面
}
}
return dummy.next;
}
}
over~~














 78
78











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









