






 文章介绍了如何在Fritzing中获取和管理元器件文件,包括从GitHub和官方论坛获取fzb/fzbz文件,单个或批量导入,特别是通过bin文件和拖放操作的批量加入技巧。此外,还提及了制作自定义器件的资源链接。
文章介绍了如何在Fritzing中获取和管理元器件文件,包括从GitHub和官方论坛获取fzb/fzbz文件,单个或批量导入,特别是通过bin文件和拖放操作的批量加入技巧。此外,还提及了制作自定义器件的资源链接。
文章出处: https://blog.csdn.net/haigear/article/details/129315452
1、获取元器件文件
你可以选择从下面两个地方来获取比较便利。
https://github.com/fritzing/fritzing-parts/
https://forum.fritzing.org/c/parts-submit/23/l/latest
Fritzing的文件后缀为fzb或者fzbz,请注意别把fzz文件也当做元件了,导入会失败的。
我们看看,官方论坛上的大家分享出来的元件,是不是琳琅满目啊,是不是你也有一种冲动要分享点啥呢?
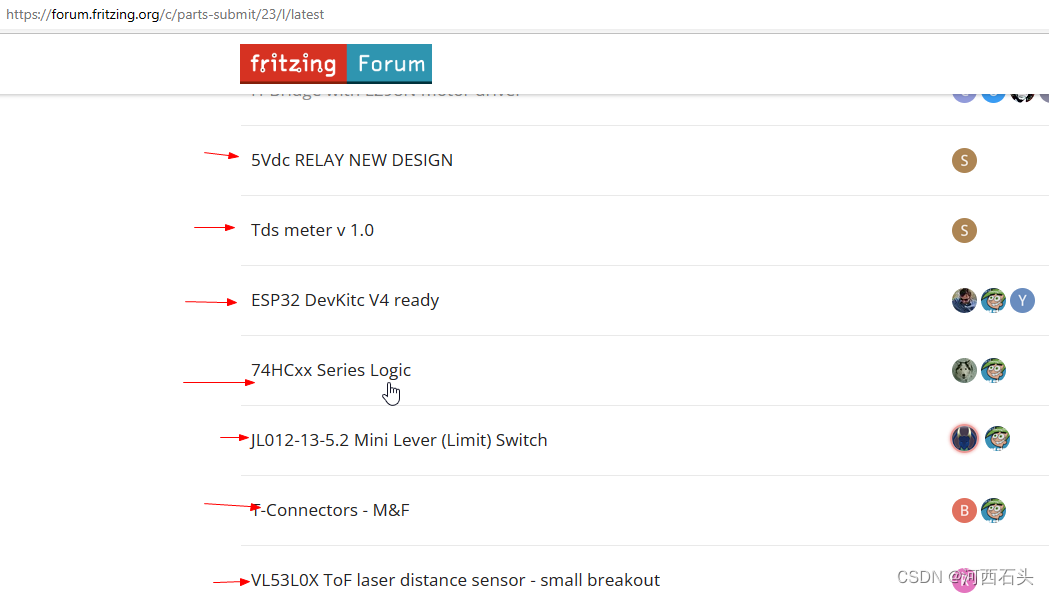
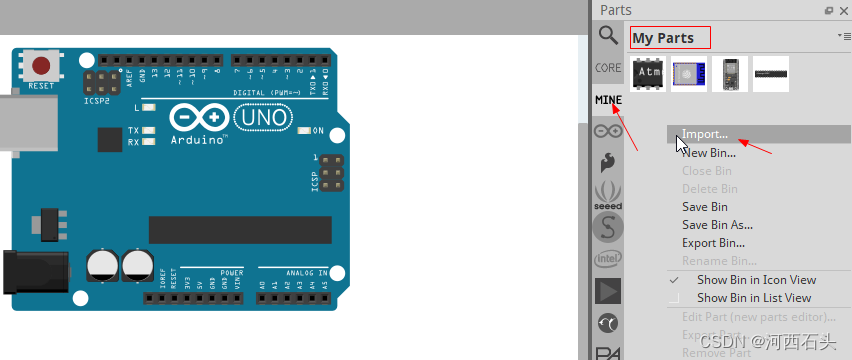
2、单个添加元器件
1、在元件库里右击点击导入
2、找到要添加的文件,直接双击导入,就可以在MINE里面找到它了
注意,通过这种方式添加的元器件,在关闭软件的时候,系统会提示是否保存在My parts里面,一定记得点保存save,否则下一次进来你又要进行重复的劳动(虽然劳动光荣,但不建议这么干)。
3、批量加入
一个个加入,对于一两个还是可以的,如果是很多元器件,那就哭笑不得了。但Fritzing根本没有提供这个功能,肿么办呢?
经过我反复测试,只有两种方法:
(1)、通过别人发布的bin文件加载
这个方式其实主动权不在你的手里,而在那个分享bin文件的人的手里,所以呢,这种方式要靠你精心搜集到别人整理好了的bin文件。所以,所以,所以,这个考验人品。
(2)、终极大招(拖)
看到上面的一个拖字,我想你应该明白了,如果还是不明白说明你没有把握“晕倒死”windows的操作精髓,通过拖放操作有很多时候可以完成你意想不到的快捷与方便。我们来看看操作效果:
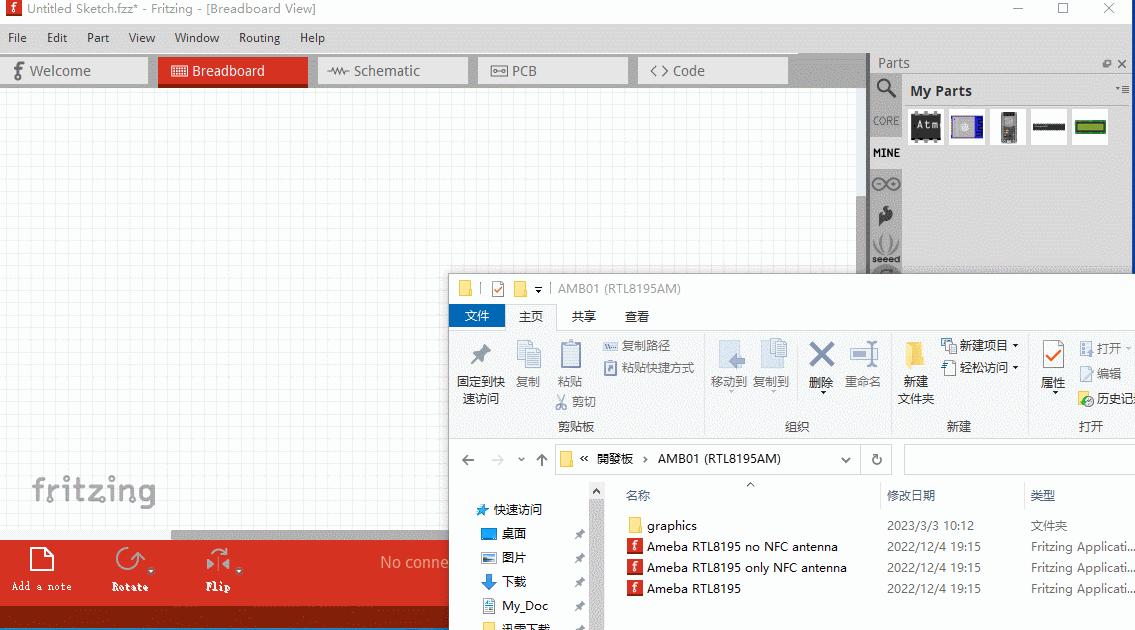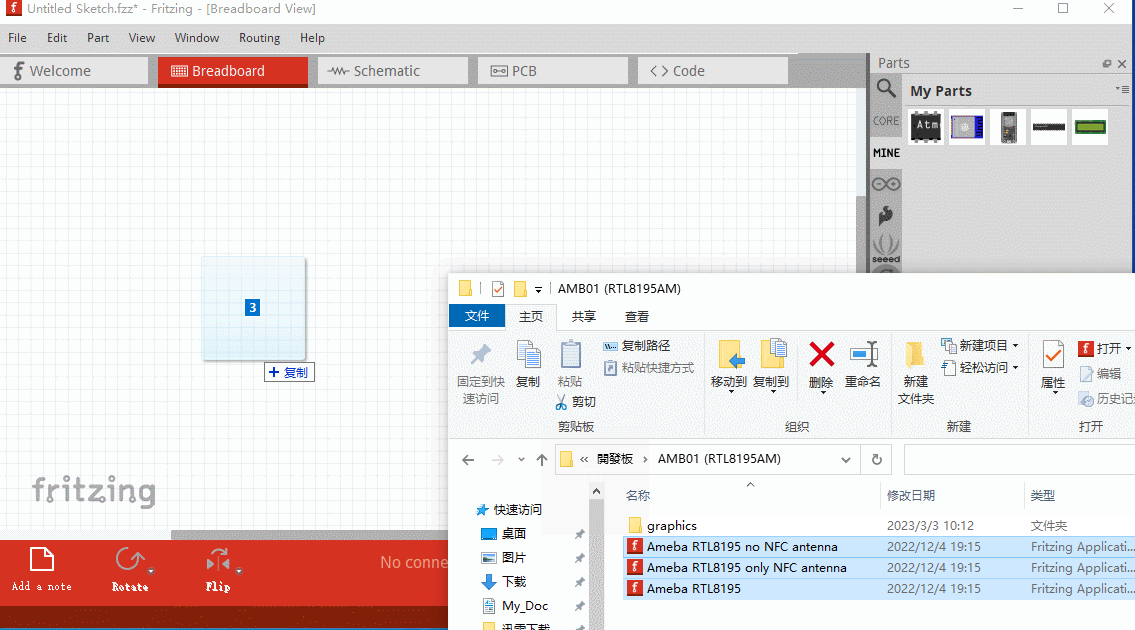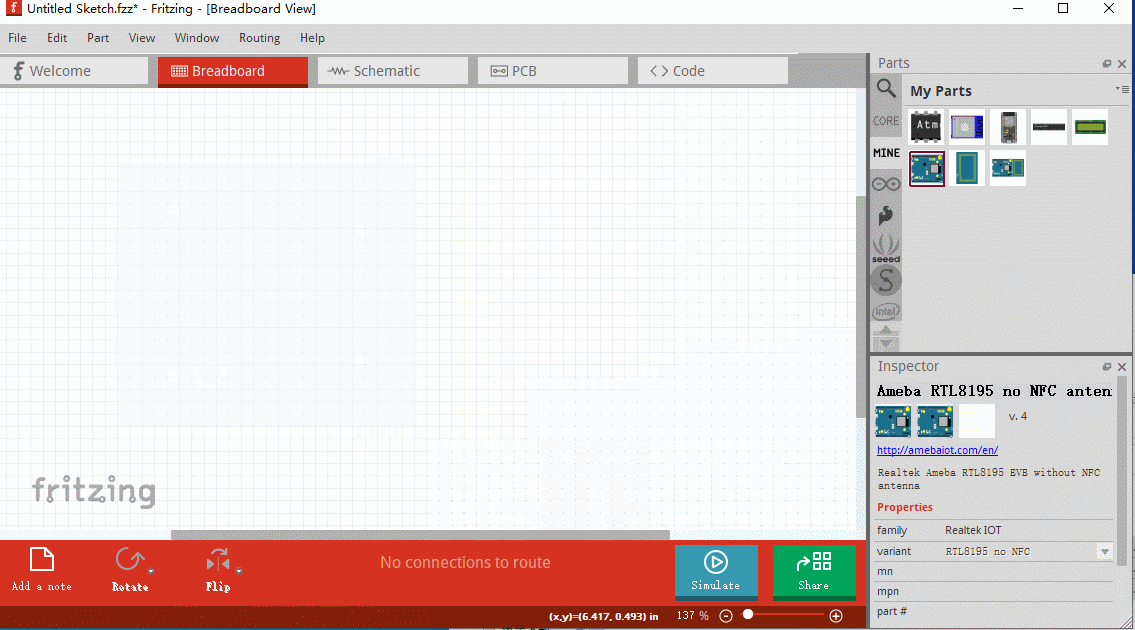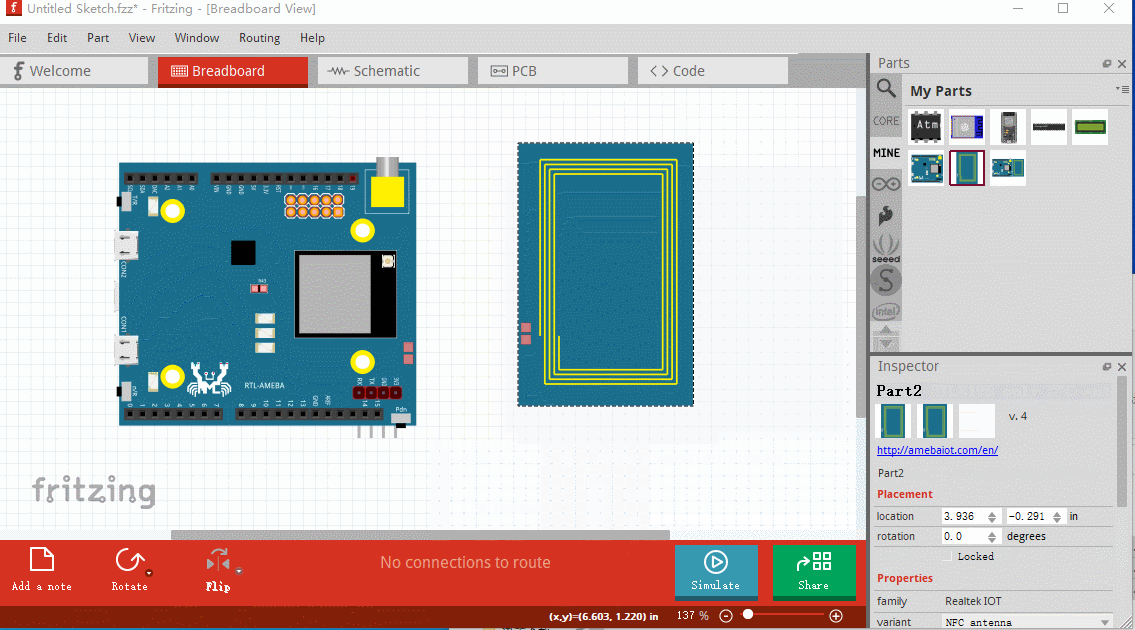
上面的演示,我通过拖放给我的元件库My Parts添加了三个元件,是不是非常的容易,非常的nice!这个终极大招对于在元器件上面有搜集欲(实际是一种贪欲,搜集这么多元器件你用得上吗?这让我记起当年很多人在网上下很多的英语学习资料,结果,结果就没有了结果了一样)
除了我说的两种方法没有别的方法了,不要详细说拷贝到某个目录就可以获得批量导入的效果,这个在fritzing0.9.10不行了。我的方法是全网唯一的可行的快捷的方法。
4、制作自己器件
大家可以参看这里,到时候我们专门写一篇博客详细介绍,这里我就不继续这个话题了。提供两个教程地址。
https://fritzing.org/learning/tutorials/creating-custom-parts/
https://learn.sparkfun.com/tutorials/make-your-own-fritzing-parts/all
https://www.arduino.cn/thread-95434-1-1.html
码字不易,转载一定注明出处:https://blog.csdn.net/haigear/article/details/129315452



















 4242
4242

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











