






马尔可夫过程(Markov Process)是一种重要的随机过程,其核心特性是无记忆性,即未来的状态仅依赖于当前状态,而与过去的状态无关。这一特性使得马尔可夫过程在许多领域中具有广泛的应用,尤其是在人工智能(AI)领域。近年来,随着 AI 大模型的兴起,马尔可夫过程在这些模型中的应用也日益增多
1 马尔可夫过程在 AI 大模型中有着广泛的应用,从自然语言处理到强化学习,再到计算机视觉和金融领域。其无记忆性和动态特性使其在建模和计算上具有显著优势,但也面临着状态空间爆炸、数据需求大和模型假设限制等挑战。随着 AI 技术的不断发展,马尔可夫过程将继续在 AI 大模型中发挥重要作用,同时也需要与其他技术相结合,以克服其自身的局限性
2、马尔可夫过程的数学原理
2.1 定义
马尔可夫过程是一种随机过程,其状态转移仅依赖于当前状态,而与过去的状态无关。数学上,这可以表示为:
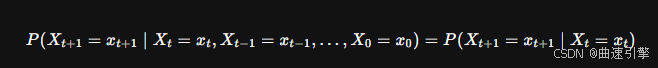
其中,表示在时间 t 的状态,P 表示概率。
2.2 马尔可夫链
马尔可夫链是马尔可夫过程的一种特例,其状态空间是离散的。马尔可夫链的状态转移可以通过转移矩阵 P 来描述,其中表示从状态 i 转移到状态 j 的概率。
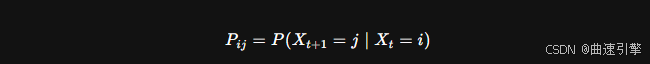
2.3 马尔可夫过程的性质
-
无记忆性:未来的状态仅依赖于当前状态,而与过去的状态无关。
-
平稳性:如果转移概率不随时间变化,则称马尔可夫过程是平稳的。
-
遍历性:在某些条件下,马尔可夫过程会收敛到一个稳态分布,即无论初始状态如何,经过足够长的时间后,系统的状态分布会趋于稳定。
3、马尔可夫过程在 AI 大模型中的应用
3.1 自然语言处理(NLP)
-
语言模型
马尔可夫过程在语言模型中有着广泛的应用。传统的 n-gram 模型就是一种基于马尔可夫假设的语言模型,它假设一个词的出现仅依赖于前面的 n−1 个词。例如,二元组(bigram)模型假设一个词的出现仅依赖于前一个词:
这种模型可以用于文本生成、自动补全和机器翻译等任务。
-
隐马尔可夫模型(HMM)
隐马尔可夫模型是一种扩展的马尔可夫模型,它假设观测序列是由一个隐藏的马尔可夫过程生成的。HMM 在语音识别、自然语言处理和生物信息学中有着广泛的应用。例如,在语音识别中,HMM 可以用于建模语音信号的时序特性,从而实现语音的识别和理解。
3.2 强化学习(Reinforcement Learning)
-
马尔可夫决策过程(MDP)
马尔可夫决策过程是强化学习中的一个核心概念,它描述了一个智能体在环境中采取行动并获得奖励的过程。MDP 包括状态空间、动作空间、转移概率和奖励函数。智能体的目标是通过选择合适的动作来最大化累积奖励。例如,AlphaGo 就是通过 MDP 框架来学习最优的棋局策略。 -
部分可观测马尔可夫决策过程(POMDP)
在实际应用中,智能体往往无法完全观测到环境的状态,这时可以使用部分可观测马尔可夫决策过程(POMDP)。POMDP 在机器人导航、智能交通和游戏 AI 中有着广泛的应用。例如,在机器人导航中,POMDP 可以用于建模机器人在未知环境中的探索和决策过程。
3.3 计算机视觉(Computer Vision)
-
图像分割
马尔可夫过程可以用于图像分割任务,通过建模像素之间的邻域关系来实现图像的分割。例如,条件随机场(CRF)是一种基于马尔可夫过程的图像分割模型,它可以通过优化像素之间的能量函数来实现图像的分割和标注。 -
视频分析
在视频分析中,马尔可夫过程可以用于建模视频序列中的时序特性。例如,隐马尔可夫模型可以用于视频目标跟踪和行为识别。通过建模目标在视频中的运动轨迹,可以实现对目标的实时跟踪和行为分析。
3.4 金融领域
-
风险评估
马尔可夫过程可以用于金融风险评估,通过建模金融市场的时序特性来预测市场风险。例如,马尔可夫链可以用于建模股票价格的波动,从而实现对市场风险的评估和管理。 -
投资组合优化
在投资组合优化中,马尔可夫过程可以用于建模资产之间的相关性和时序特性。通过优化投资组合的权重,可以实现对投资组合风险和收益的平衡。
4、马尔可夫过程在 AI 大模型中的具体实现
4.1 语言模型中的实现
-
n-gram 模型
n-gram 模型是一种简单的马尔可夫语言模型,它假设一个词的出现仅依赖于前面的 n−1 个词。例如,二元组(bigram)模型可以通过统计词对的频率来计算条件概率:Python复制
from collections import defaultdict import numpy as np def train_bigram_model(text): model = defaultdict(lambda: defaultdict(int)) words = text.split() for i in range(len(words) - 1): model[words[i]][words[i + 1]] += 1 for word in model: total = float(sum(model[word].values())) for next_word in model[word]: model[word][next_word] /= total return model def generate_text(model, length=100): import random words = list(model.keys()) word = random.choice(words) result = [word] for _ in range(length - 1): next_words = list(model[word].keys()) probabilities = list(model[word].values()) word = np.random.choice(next_words, p=probabilities) result.append(word) return ' '.join(result) text = "your training text here" model = train_bigram_model(text) print(generate_text(model)) -
隐马尔可夫模型(HMM)
HMM 可以用于建模隐藏状态和观测序列之间的关系。例如,在语音识别中,HMM 可以用于建模语音信号的时序特性:Python复制
from hmmlearn import hmm import numpy as np # 定义 HMM 模型 model = hmm.GaussianHMM(n_components=3, covariance_type="diag", n_iter=100) model.startprob_ = np.array([0.6, 0.3, 0.1]) model.transmat_ = np.array([[0.7, 0.2, 0.1], [0.3, 0.5, 0.2], [0.3, 0.3, 0.4]]) model.means_ = np.array([[0.0, 0.0], [3.0, -1.0], [5.0, 1.0]]) model.covars_ = np.tile(np.identity(2), (3, 1, 1)) # 生成数据 X, Z = model.sample(100) # 训练模型 model.fit(X) # 预测状态 logprob, seq = model.decode(X, algorithm="viterbi") print("Predicted sequence:", seq)
4.2 强化学习中的实现
-
马尔可夫决策过程(MDP)
MDP 可以通过动态规划算法(如值迭代和策略迭代)来求解。例如,值迭代算法可以通过迭代更新状态值来找到最优策略:Python复制
import numpy as np def value_iteration(transitions, rewards, gamma=0.9, theta=0.001): num_states = len(transitions) V = np.zeros(num_states) while True: delta = 0 for s in range(num_states): v = V[s] V[s] = max([sum([transitions[s][a][s_next] * (rewards[s][a][s_next] + gamma * V[s_next]) for s_next in range(num_states)]) for a in range(len(transitions[s]))]) delta = max(delta, abs(v - V[s])) if delta < theta: break return V def extract_policy(transitions, rewards, V, gamma=0.9): num_states = len(transitions) policy = np.zeros(num_states) for s in range(num_states): policy[s] = np.argmax([sum([transitions[s][a][s_next] * (rewards[s][a][s_next] + gamma * V[s_next]) for s_next in range(num_states)]) for a in range(len(transitions[s]))]) return policy # 定义状态转移和奖励 transitions = [[[0.7, 0.3], [0.5, 0.5]], [[0.4, 0.6], [0.3, 0.7]]] rewards = [[[10, 0], [0, 10]], [[0, 10], [10, 0]]] V = value_iteration(transitions, rewards) policy = extract_policy(transitions, rewards, V) print("Optimal policy:", policy) -
部分可观测马尔可夫决策过程(POMDP)
POMDP 可以通过贝叶斯滤波和动态规划算法来求解。例如,贝叶斯滤波可以通过更新信念状态来预测系统的状态:Python复制
import numpy as np def bayesian_filter(transitions, observations, initial_belief, evidence): num_states = len(transitions) belief = initial_belief for t in range(len(evidence)): belief = np.dot(transitions, belief) belief = belief * observations[:, evidence[t]] belief = belief / np.sum(belief) return belief # 定义状态转移和观测模型 transitions = np.array([[0.7, 0.3], [0.4, 0.6]]) observations = np.array([[0.9, 0.1], [0.2, 0.8]]) initial_belief = np.array([0.5, 0.5]) evidence = [0, 1, 0] belief = bayesian_filter(transitions, observations, initial_belief, evidence) print("Final belief:", belief)
4.3 计算机视觉中的实现
-
条件随机场(CRF)
CRF 可以用于图像分割任务,通过优化像素之间的能量函数来实现图像的分割。例如,CRF 可以通过动态规划算法来求解最优分割:Python复制
import numpy as np from skimage import segmentation def crf_segmentation(image, unary_potentials, pairwise_potentials): num_labels = unary_potentials.shape[1] num_pixels = unary_potentials.shape[0] labels = np.zeros(num_pixels) for i in range(num_pixels): labels[i] = np.argmax(unary_potentials[i]) return labels # 定义 unary 和 pairwise 潜在函数 image = np.random.rand(100, 100, 3) unary_potentials = np.random.rand(10000, 2) pairwise_potentials = np.array([[0.9, 0.1], [0.2, 0.8]]) labels = crf_segmentation(image, unary_potentials, pairwise_potentials) print("Segmentation labels:", labels)
5、马尔可夫过程在 AI 大模型中的优势与挑战
5.1 优势
-
简单高效
马尔可夫过程的无记忆性使得其在建模和计算上相对简单高效。例如,n-gram 模型可以通过简单的统计方法来计算条件概率,适合大规模数据的处理。 -
适应性强
马尔可夫过程可以适应多种类型的数据和任务。例如,在自然语言处理中,n-gram 模型可以用于文本生成和语言建模;在强化学习中,MDP 可以用于建模智能体的决策过程。 -
理论基础坚实
马尔可夫过程具有坚实的数学理论基础,其性质和算法已经得到了广泛的研究和应用。例如,动态规划算法可以有效地求解 MDP 和 POMDP 问题。
5.2 挑战
-
状态空间爆炸
马尔可夫过程的状态空间可能非常庞大,导致计算复杂度急剧增加。例如,在 POMDP 中,状态空间的大小可能呈指数增长,使得求解变得非常困难。 -
数据需求大
马尔可夫过程的建模需要大量的数据来估计转移概率和奖励函数。例如,在语言模型中,需要大量的文本数据来训练 n-gram 模型和 HMM。 -
模型假设限制
马尔可夫过程的无记忆性假设可能过于简化,无法捕捉到数据中的长期依赖关系。例如,在自然语言处理中,n-gram 模型可能无法捕捉到长距离的语法和语义关系。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









