






今天分享的是AI专题系列深度研究报告:《AI专题:英伟达数据中心 GPU 升级路线:存算连持续升级,向系统级解决方案扩展》。
(报告出品方:广发证券)
核心观点
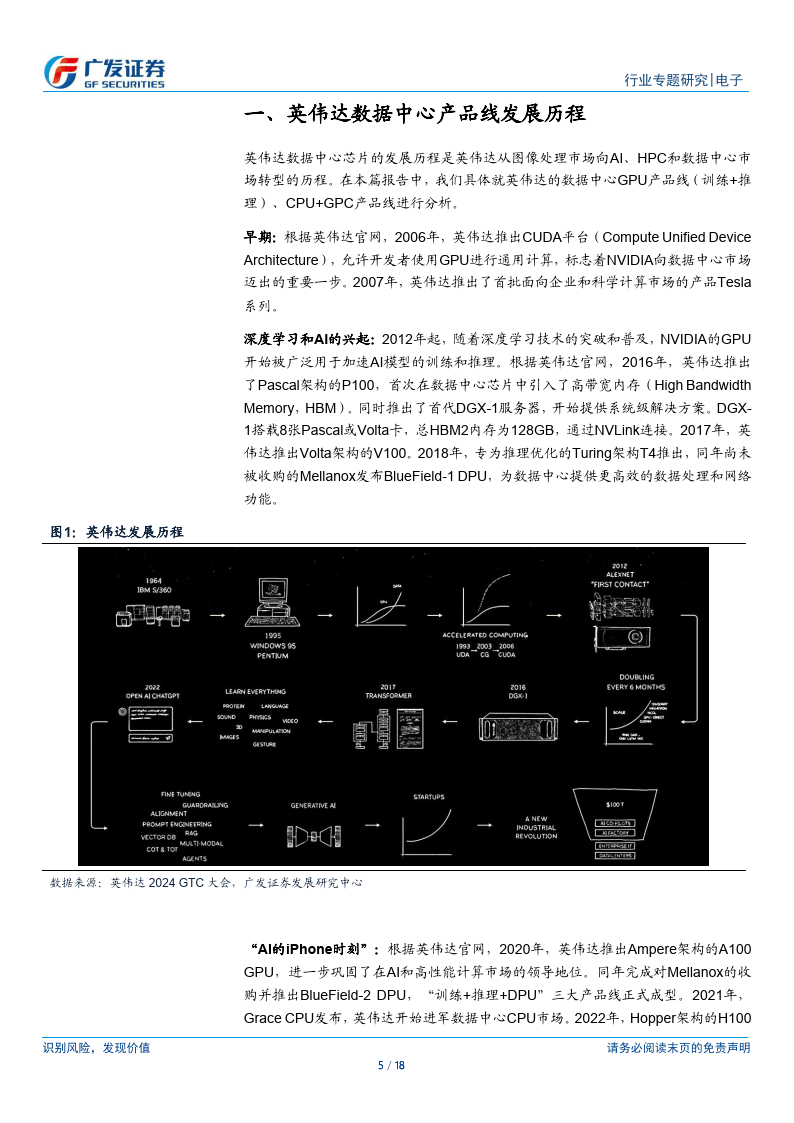
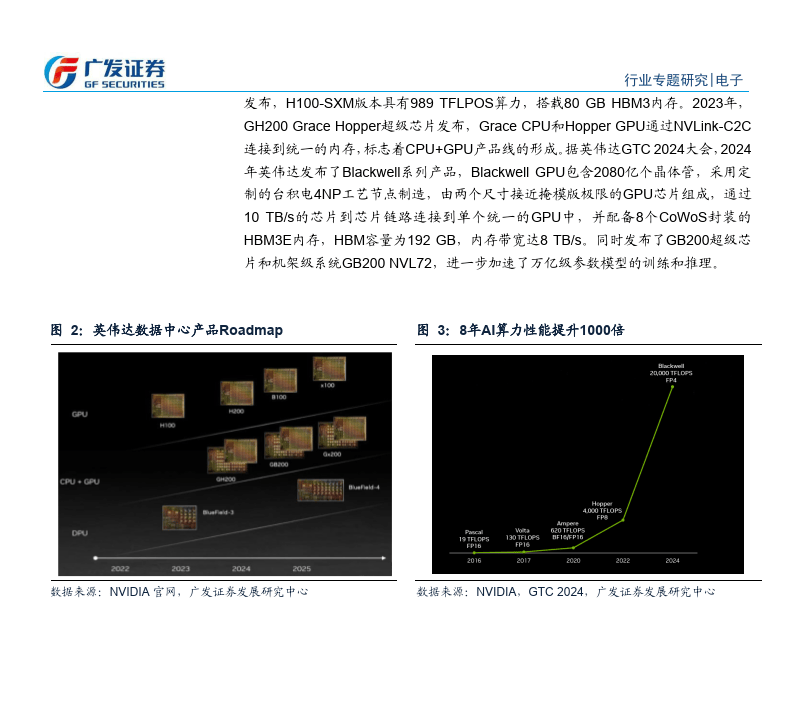
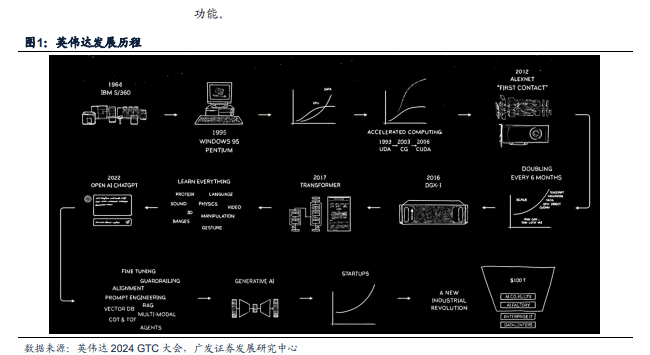
英伟达数据中心芯片的发展历程是美伟达从图像处理市场向 A1、HPC 和数据中心市场转型的历程。据英伟达官网,从2016年Pascal架构的P100起,英伟达数据中心 GPU 经历了 Pascal、Volta、Ampere、Hopper几代架构迭代。据英伟达 GTC 2024 大会,2024 年英伟达发布了 Blackwel 系列产品,包括 Blackwell GPU、GB200 超级芯片和机架级系统 GB200 NVL72,进一步加速了万亿级参数模型的训练和推理。训练产品线:算、存、连全方位升级,架构不断速代。据英伟达 GTC2024 大会,BlackwellGPU 包含2080 亿个晶体管,由两个尺寸接近掩模版极限的 GPU 芯片组成,通过 10 TB/s 的芯片到芯片链路连接到单个统一的GPU 中,并配备8个CoWoS 封装的HBM3E内存,HBM容量为192GB,内存带宽达8TB/s.Blackwell GPU引入了新的计算精度 FP6 和 FP4,位宽比 FP8 进一步降低。在 FP4 精度下,B100 和 B200峰值算力分别达14PFlops和18 PFlops;在FP16精度下,B100和B200 的峰值算力也分别为 H100的1.8x和2.3x,算力大幅捉升,
推理产品线:兼具图形性能,针对具体场景优化。目前,NVIDIA的推理产品线主要包括L40、L4、L40S等产品,均基于 AdaLovelace 架构,L40S 将强大的 AI计算与一流的图形和媒体加速相结合,旨在为下一代数据中心工作负载提供支持,从生成式A|和大型语言模型推理和训练到3D图形、渲染和视频,L40S搭载了Transfomer
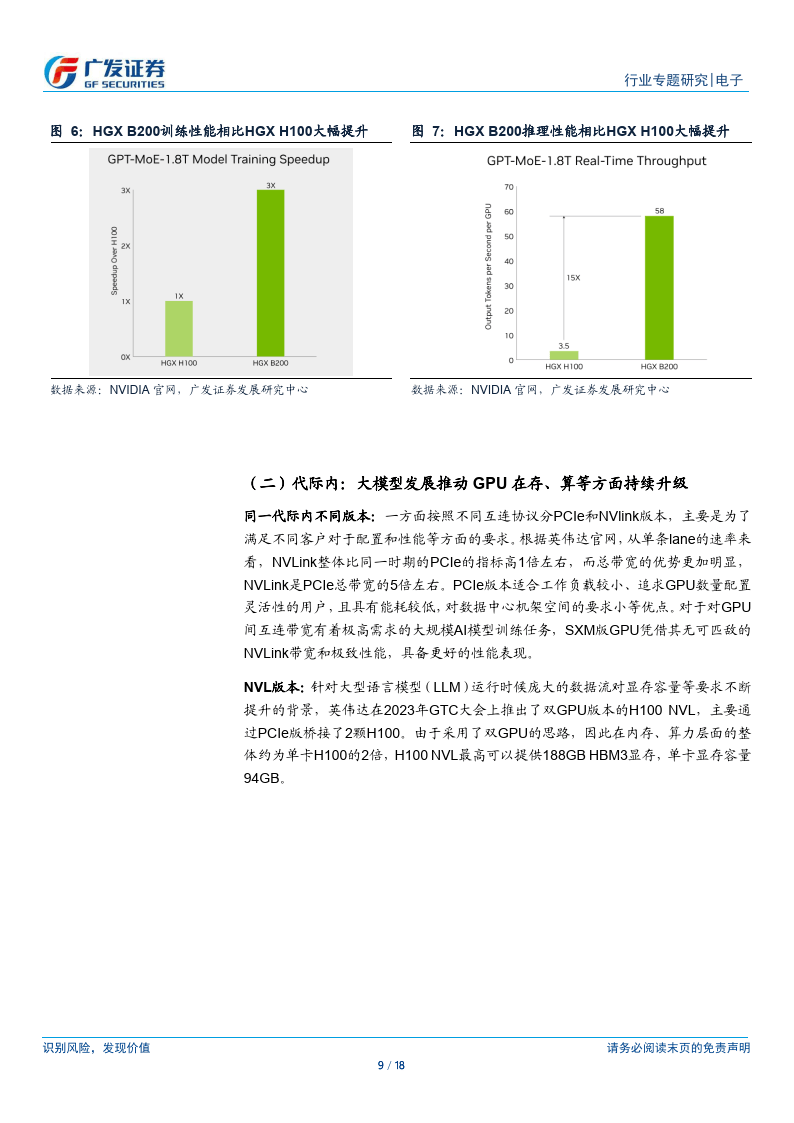
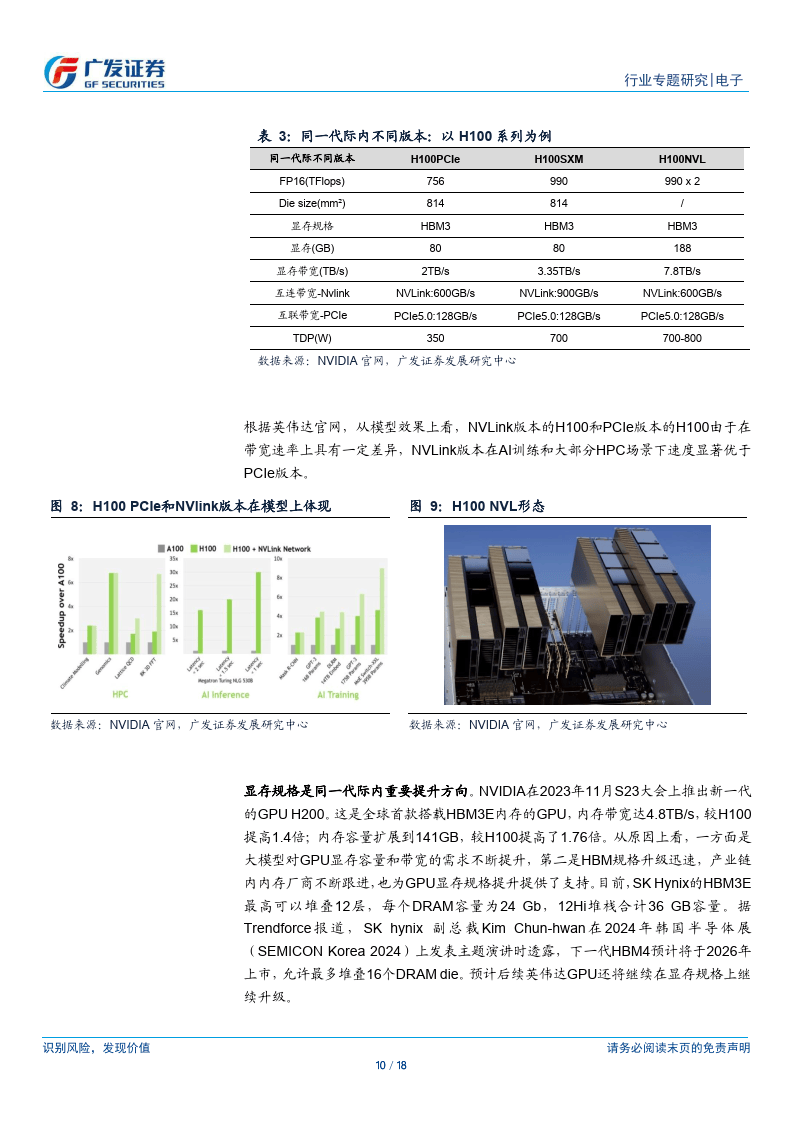
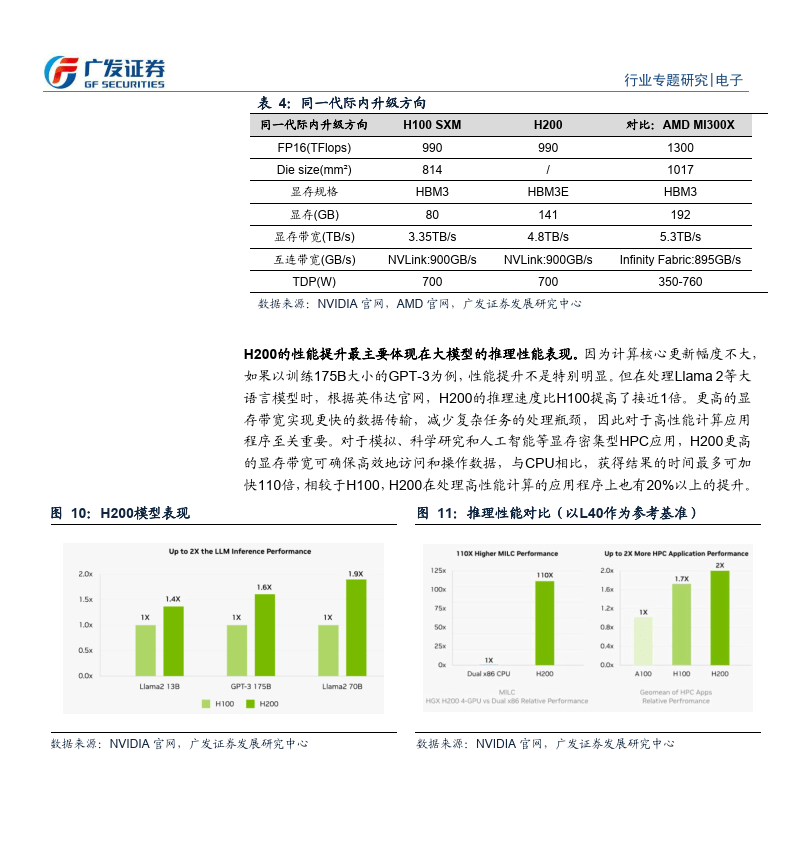
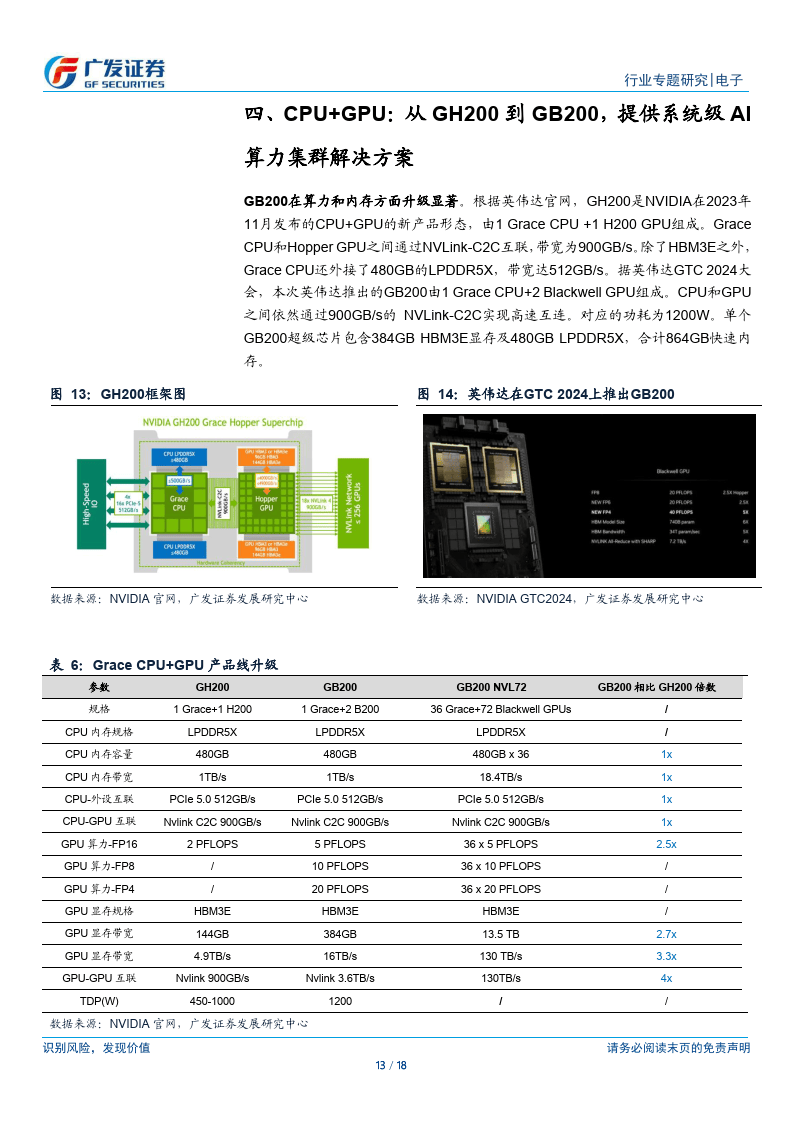
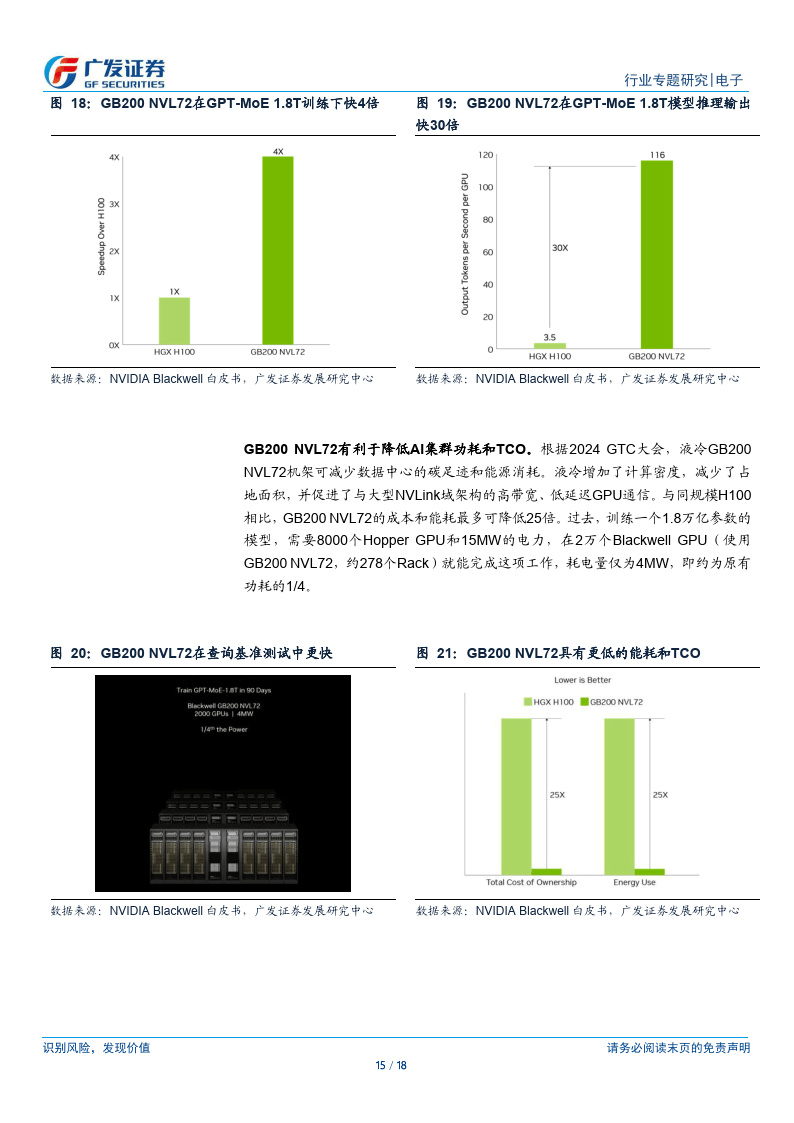
引擎,算力相比 L40 大幅提升。CPU+GPU:从 GH200 到 GB200,提供系统級 AI 算力集群解决方案。据英伟达 GTC 2024大会,2024 年英伟达在推出的GB200由1Grace CPU+2Blackwel GPU组成,CPU和GPU之间依然通过900GB/s 的 NVLinkC2C 实现高速互联。对应的功耗为 1200W,单个 GB200 超级芯片包含 384 GB HBM3E 内存及 480GBLPDDR5X,合计 864GB 快速内存。液冷 GB200NVL72 机架级系统可减少数据中心的碳足迹和能源消耗。与同规模 H100 相比,GB200 NVL72 的成本和能耗最多可降低 25 倍,过去,训练一个 1.8万亿参数的模型,需要8000个HopperGPU和15MW的电力,在2万个Blackwell GPU(使用 GB200 NVL72,约 278个Rack)就能完成这项工作,耗电量仅为 4MW,即约为原有功耗的 114。
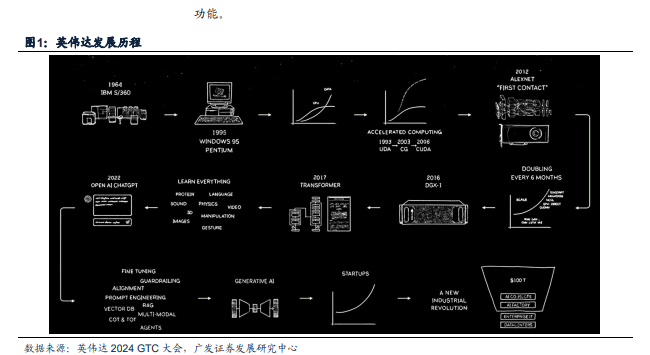
英伟达数据中心产品线发展历程
英伟达数据中心芯片的发展历程是英伟达从图像处理市场向A1、HPC和数据中心市场转型的历程。在本篇报告中,我们具体就英伟达的数据中心GPU产品线(训练+推理)、CPU+GPC产品线进行分析。
早期:根据英伟达官网,2006年,英伟达推出CUDA平台(ComputeUnifedDeviceArchitecture),允许开发者使用GPU进行通用计算,标志着NVIDIA向数据中心市场迈出的重要一步,2007年,英伟达推出了首批面向企业和科学计算市场的产品Tesla系列,
深度学习和Al的兴起:2012年起,随着深度学习技术的突破和善及,NVIDIA的GPU开始被广泛用于加速A1模型的训练和推理。根据英伟达官网,2016年,英伟达推出了Pascal架构的P100,首次在数据中心芯片中引入了高带宽内存(HighBandwidthMemory,HBM)。同时推出了首代DGX-1服务器,开始提供系统级解决方案。DGX1搭截8张Pascal或Volta卡,总HBM2内存为128GB,通过NVLink连接。2017年,英伟达推出Volla架构的V100。2018年,专为推理优化的Turing架构T4推出,同年尚未被收购的Mellanox发布BlueField-1DPU,为数据中心提供更高效的数据处理和网络功能。
训练产品线:算、存、连全方位升级,架构不断迭代
(一)代际间:A/H/Blackwell,算、存、连全方位升级
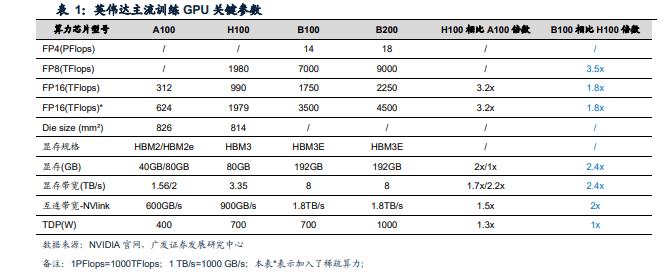
H100相对于A100的升级:根据英伟达官网,(1)H100新增FP8数据精度:H100SM基于NVIDIAA100Tensor Core GPUSM架构而构建。由于引入了FP8,与A100相比,H100SM将每SM浮点计算能力峰值提升了4倍,并且对于之前所有的TensorCore和FP32 /FP64数据类型,将各个时钟频率下的原始SM计算能力增加了一倍:(2)存储能力升級:H100最初在NVIDIA GTC 2022上发布,刚发布时候采用HBM380GB,容量一致,但由于从HBM212e升级到了HBM3,显存带宽升级到了3.35TB/S;(3)互联带宽升额,Nvlink从3.0升级到4.0,支持双向带宽900GB/S,PCle协议也从4.0升级至5.0达到128GB/S.
B100/B200相对于H100的升:根据英伟达2024GTC大会,BlackwellGPU包含2080亿个晶体管,采用定制的台积电4NP工艺节点制造,由两个尺寸接近掩模版极限的GPU芯片组成,通过10TB/s的芯片到芯片链路连接到单个统一的GPU中,配备8个HBM3E内存,HBM容量为192 GB,内存带宽达8TB/s。Blackwell GPU引入了新的计算精度FP6和FP4,位宽比FP8进一步降低。B100和B200均基于Blackwell架构。在FP4精度下,B100和B200峰值算力分别达14PFlops达18PFlops;在FP16精度下,B100和B200的峰值算力也分别为H100的1.8x和2.3x,算力大幅提升。




报告来源/公众号:【海选智库】
本文仅供参考,不代表我们的任何建议。海选智库整理分享的资料仅推荐阅读,如需使用请参阅报告原文。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









