






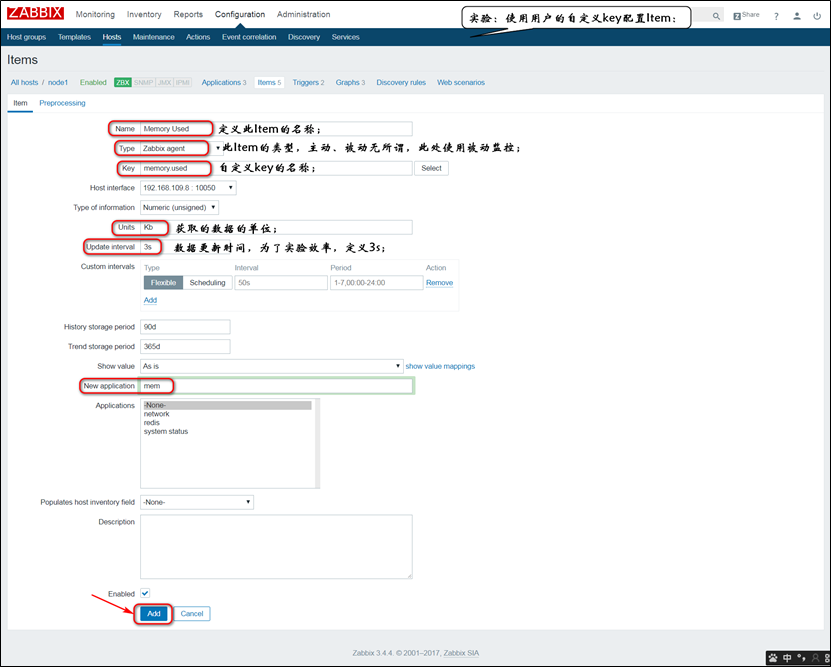
(15)自定义key(User parameters):
自定义的key需要在zabbix_agentd.conf文件中来定义,格式如下:
UserParameter=<key[*]>,<command>
UserParameter=mysql.ping,mysqladmin -uroot ping|grep -c alive
注意:自定义key需要再Agent端来定义的;<key>不要和已有的key冲突,建议,做到见名知意;<command>需要用户自己编写;
注意:如果返回值是1,说明mysql处于工作状态,如果返回值是0,说明mysql处于非工作状态;由于zabbix在处理文本的时候,效率比较低,所以,建议转换成数值;
注意:由于"/etc/zabbix/zabbix_agentd.conf"配置文件中有很多的配置,所以不建议直接修改该文件,建议在"/etc/zabbix/zabbix_agentd.d"目录下创建一个*.conf文件,专门用来定义自定义key;
注意:自定义key定义结束后,需要重启zabbix-agent.service服务;
注意:定义过key之后,可以在zabbix-server端,使用zabbix_get命令来获取用户自定义的key值;
vim /etc/zabbix/zabbix_agentd.d/userparameter_key.conf
UserParameter=memory.used,free -m | awk '/^Mem/{print $3}'
systemctl restart zabbix-agent.service
zabbix_get -s 192.168.109.8 -p 10050 -k "memory.used"
tail /var/log/zabbix/zabbix_server.log#查看是否有报错!
tail /var/log/zabbix/zabbix_agentd.log#查看是否有报错!

注意:此时,memory.used只能在node1节点使用,所以,当在web-GUI中配置item时,只能在node1节点使用,配置到其他的Hosts上没用。如果其他节点也想要配置此Item,需要将"UserParameter=memory.used,free -m | awk '/^Mem/{print $3}'"也在其他节点的主机上都有;
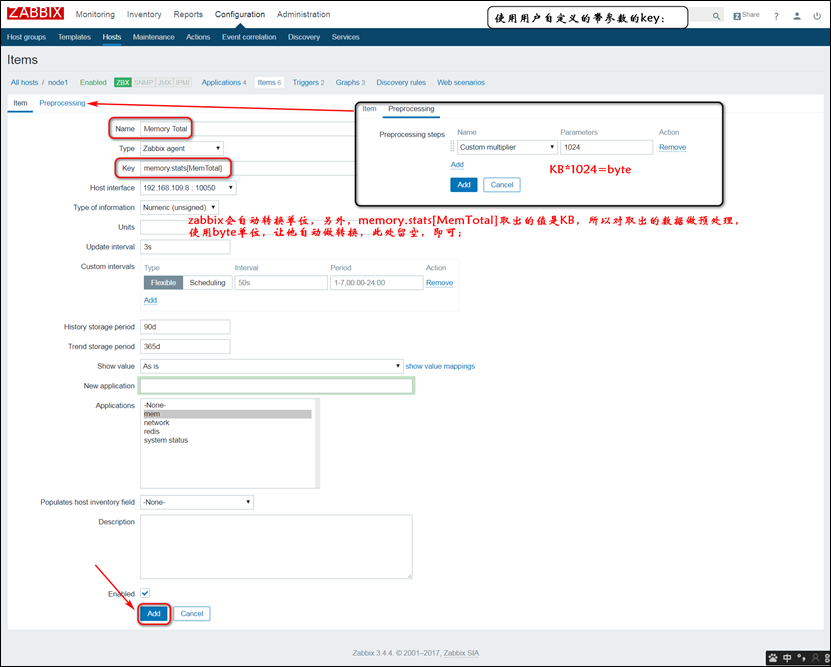
示例:使用带参数的自定义的key:
vim /etc/zabbix/zabbix_agentd.d/userparameter_key.conf
UserParameter=memory.stats[*],cat /proc/meminfo | awk '/^$1/{print $$2}'
systemctl restart zabbix-agent.service
zabbix_get -s 192.168.109.8 -p 10050 -k "memory.stats[CommitLimit]"
zabbix_get -s 192.168.109.8 -p 10050 -k "memory.stats[MemFree]"
注意:$1是用户在memory.stats[]中传递的参数,$$2表示的是awk中的位置变量!如果$$2只有一个$2的话,会被认为是memory.stats[]中传递的第二个参数;
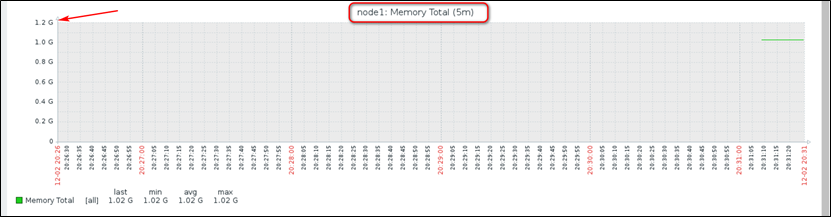
注意:实际生产中,一般使用自定义的key,需要通过状态页面,来检测服务的运行状态;大致的操作就是,在node1节点上,开启服务器的状态页面,然后通过curl命令将状态页面抓取下来,然后对需要的数据做一下处理,然后传递给Item;不过需要注意的是,状态页面的权限,尽可能的设置的小一点,即需要设置访问控制,另外不要记录key的访问日志,尽可能的减轻服务器的压力!
(16)监控发现:
不同的主机,扮演着不同的角色,有的是Tomcat、Varnish、Nginx等等,监控项很显然是不同的,除了基础的系统级的监控项之外,如何判定其监控项呢?
可以获取到的服务(例如FTP、SSH、WEB、POP3、IMAP、TCP等等);
网络发现功能可以减轻工作人员的工作量,过于频繁的话,不但会消耗掉zabbix server很大的资源,还会损耗很大的网络资源;如果减少扫描的频率,就会有滞后性;
实验:让node2节点,基于网络发现功能,自动添加到监控策略中,具体操作如下:
wget http://repo.zabbix.com/zabbix/3.4/rhel/7/x86_64/zabbix-release-3.4-2.el7.noarch.rpm
rpm -ivh zabbix-release-3.4-2.el7.noarch.rpm
yum install zabbix-agent zabbix-sender
node1节点上(由于node1、2安装的都是agent,所以将node1上的配置放到node2上,然后修改一下关键信息即可):
scp -r /etc/zabbix/* 192.168.109.6:/etc/zabbix/
systemctl restart zabbix-agent.service
zabbix_get -s 192.168.109.6 -p 10050 -k "system.uname"
Linux node2 3.10.0-514.el7.x86_64 #1 SMP Tue Nov 22 16:42:41 UTC 2016 x86_64
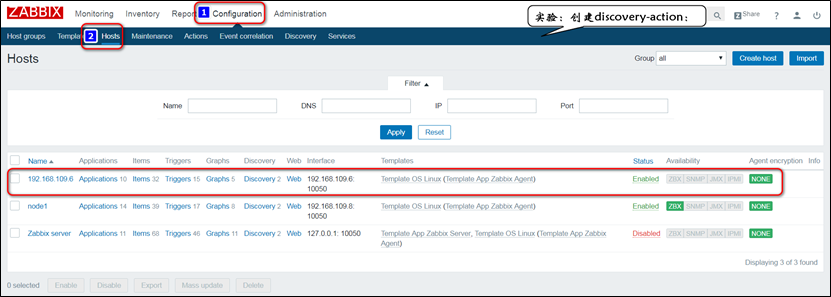
注意:此时node2节点,便属于一个可被监控的主机了。如果想要使用zabbix server的自动发现功能,需要在web-GUI上配置discovery的相关配置:
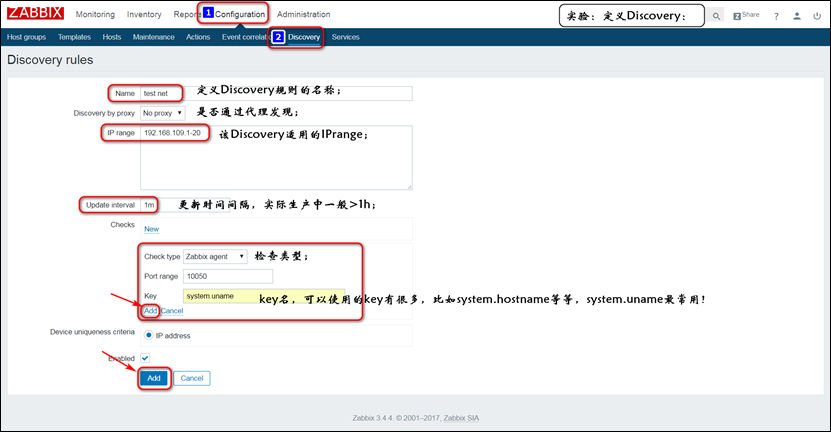
注意:此时node2便可以被zabbix server发现,但是除了发现了node2节点的主机外,并不会采取额外的操作,因为还没有定义发现后,需要采取的action;

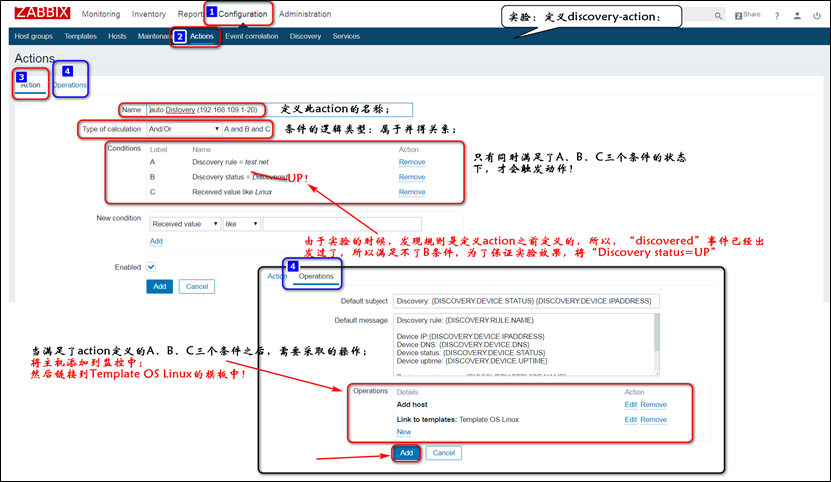
注意:由于discovery功能非常的消耗资源,所以,在没有新添加的主机的情况下,可以将该功能"disable",禁用掉!
注意:discovery功能不仅可以自动添加主机,如果主机出现故障,还可以自动的移除主机。具体的操作此处不做演示!
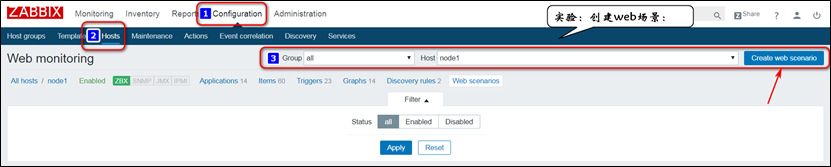
(17)web监控:监控指定的站点的资源下载速度,及页面响应时间,还有响应代码;
web Scenario:web场景,可以理解为web站点,一个web站点,内部有多个web页面,每一个页面,可以称为监控的步骤,每一个步骤需要测试三个状态,即资源下载速度、页面响应时间、响应码;
web.test.in[Scenario,Step,bps]:传输速率;
web.test.time[Scenario,Step]:响应时长;
web.test.rspcode[Scenario,Step]:响应码;
实验:web监控:
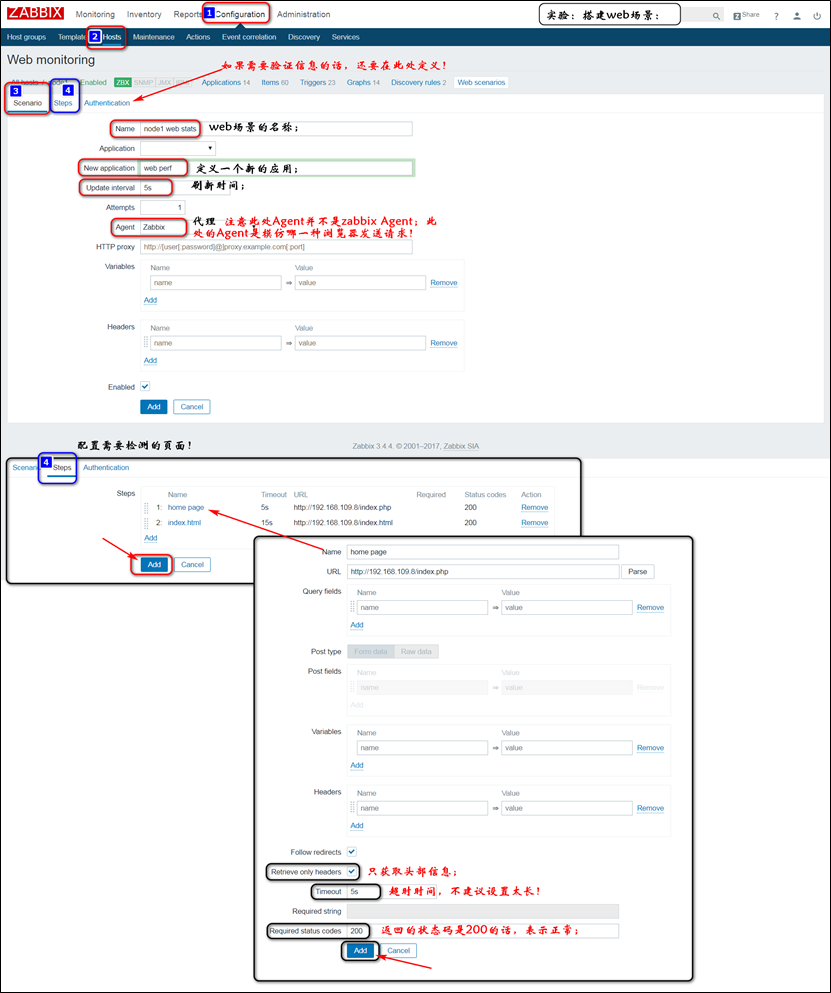
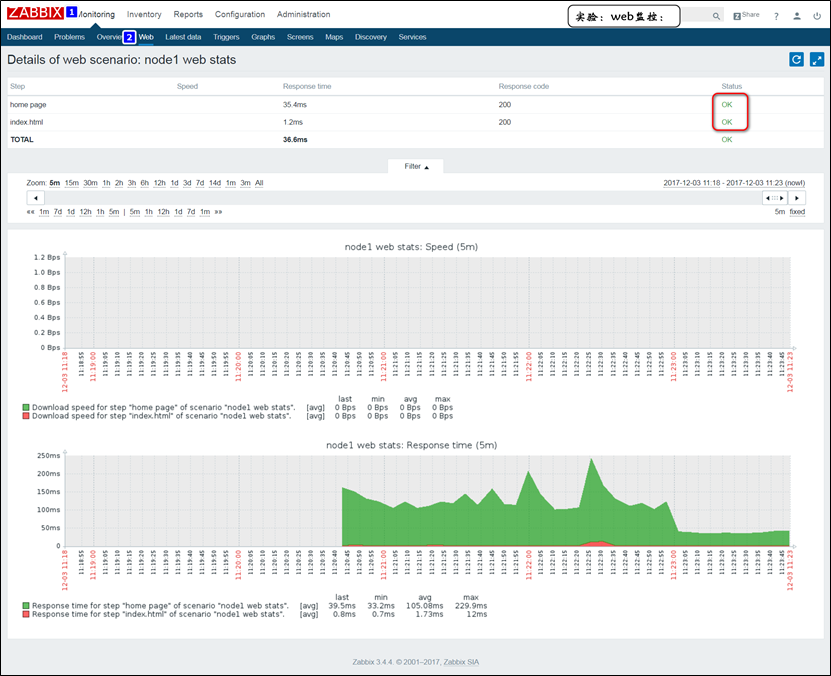
注意:试验中定义了两个页面,每一个页面有三个监控项;















 4392
4392

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









