







一、基本数据结构
创建向量和矩阵
函数c()、length()、mode()、rbind()、cbind()
mode(X) 查看这个是什么类型的;length() 查看这个向量的长度;rbind(x1,x2) 两个向量合成一个矩阵cbind(x1,x2) 两个向量竖着合成一个矩阵
常用统计函数;mean()、sum()、min()、max()、var()、sd()、prod()
mean(x) 平均值sum() 求和min() 求最小值max() 最大值var() 求方差 (反应数据离散的情况)sd() 标准差prod() 连乘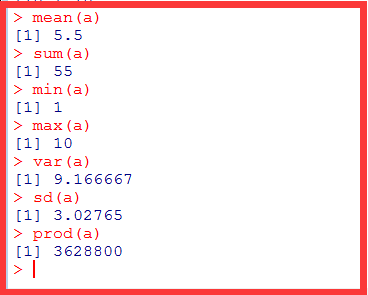
注意:<- 就是等号(最好使用这个等于号!)
对象的类型:数值型 Numeric 例如:100、200字符型 Character 例如:"china"逻辑型 Logical 例如:true、false因子型 Factor 表示不同类别复数型 Complex 例如2+3i
在赋值的时候后面加L 就是变成整数类型class() 查看数据类型
c1 & c2 是它们的交集运算 (“与”),c1 | c2 是并集运算 (“或”),!c1 是 c1 的非运算
向量写法: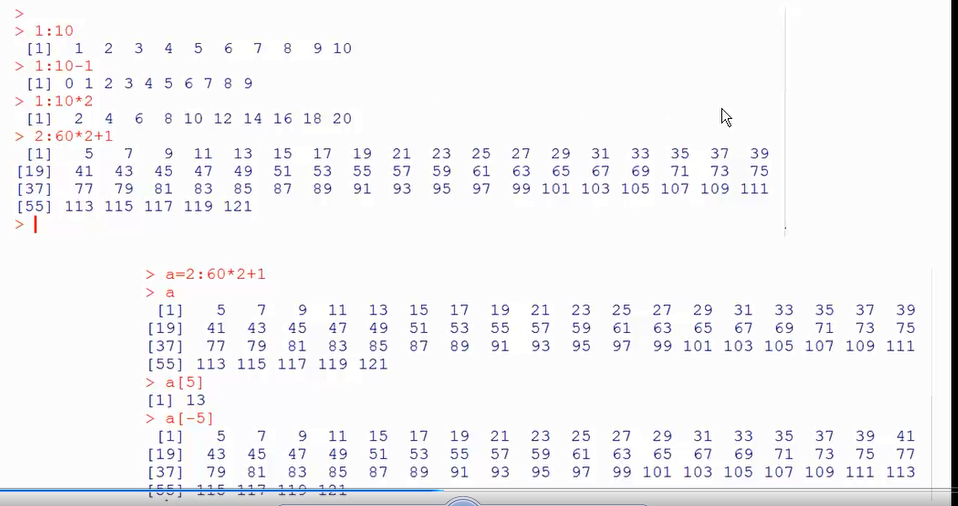

等差数列赋值函数:seq()函数 seq(from=,to=,by=,length.out=)参数“by”表示等差,参数“length.out”表示等差数列元素的个数

重复函数reprep(x,times=,each=,length.out=)times参数表示X的重复次数,参数“each”表示每个元素重复的次数,length.out表示截取前多少个元素
1.判断是否为数值型向量
is.numeric(x)
其他向量转换为数值型向量: as.numeric()
同样判断是否为字符、逻辑的函数: is.character()、is.logical()
转化为字符、逻辑的函数: as.character()、as.logical()
2.增加一个元素为6.
x[6] <- 6如果直接写“ x[8] <- 6 ”那么x的第六和第七个元素自动赋值为“NA”,表示缺失值。
3.接上,删除向量中的缺失值。
x[is.na(x)=F] b <- a[-which(is.na(a))] #去掉缺失值
函数 is.na() 判断是否为缺失值。 “x[is.na(x)=F]”表示索引出x中不是缺失值的元素。“length(x[is.na(x)])”返回x中缺失值的个数。
4.删除最后一个元素
x <- x[1:(length(x)-1)]
很简单,不解释了,应该可以看懂的
5.更改某个元素,如第三个元素改为8
x[3] <- 8
字符串向量:paste()
letters常数
which()函数 输出位置

rev()函数、sort()函数 倒叙;正序
matrix()函数 向量变换为矩阵
t()“矩阵转置”、矩阵加减
矩阵相乘、函数diag() 求对角线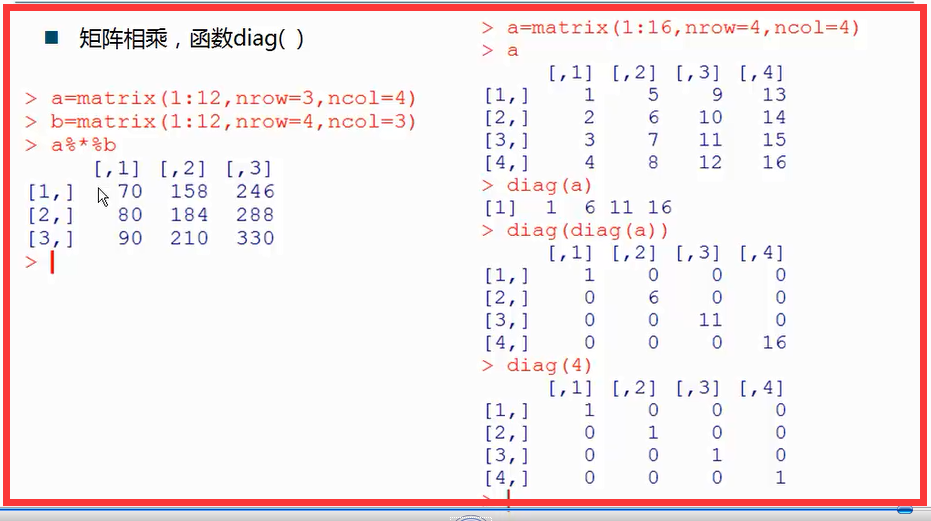
矩阵求逆、函数rnorm() "正态分布随机数"、 solve() “求逆矩阵”

求矩阵的特征值与特征向量函数eigen()
数组:dim(x)<-c(2,3)矩阵是数组的一个特殊情况
数据框:data.frame(x1,x2) x1与x2长度必须相等
plot(x) 画图
外表R文件读取 :
> (x=read.table("abc.txt"))>read.csv() 可以读取csv的文件
也可以直接将文本或exceld的数据通过剪切板读取header=F代表不读取头
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









