







 针对单表性能瓶颈和业务量激增,采用Sharding-Sphere进行分库分表改造,解决高并发、大规模数据处理难题。
针对单表性能瓶颈和业务量激增,采用Sharding-Sphere进行分库分表改造,解决高并发、大规模数据处理难题。
前言
抽空对前段时间的分库分表项目进行了简单的总结。
因为多方面原因,其实这个项目只是涉及到了分表,并没有涉及分库。当然,分库与分表的思路是可以相互借鉴的。
因为分库分表面对的场景多种多样,不能一概议论,所以本文只作为一种特定场景下的参考。
因为本人水平有限,不足与待改进之处,请大家多多指教。
场景概述
- 缘由:1.基本已经达到单表的性能瓶颈;2.最近业务量会成倍增加。
- 平均QPS:改造之后至少能够承受改造之前的
10倍压力的QPS。 - 平均延时:改造之后的不能多出改造之前的
50%的延时。 - 量级:当前量级:
8千万,5年后预估量级:5亿。 - 项目:
- 项目类型:大致涉及
20个系统,其中4个系统涉及增删改操作,其余系统只涉及读操作。 - 容器框架:时间跨度较大,
servlet、spring、springBoot兼而有之。 - 持久框架:都是mybatis,但用法多种多样:1.通过
MBG生成的SQL;2.通过map方式进行传参与返回值;3.通过POJO形式进行传参与返回值;4.混合方式。 - 数据库源:有些是单源数据源,有些是多源数据源,有些是动态数据源。
- 项目类型:大致涉及
- MySql集群:1主多从
- 主键ID:之前未实施分布式主键,而是使用的MySql的自增主键。
- 前端处理长整型丢失精度:目前前端未对超长长整形进行统一处理,可能面对部分展示数据丢失精度的问题。
- 数据结构(为了避嫌,以下表名及字段名使用化名):
- 数据表名为:
message(消息表) - 主键:
id,目前为MySql自增主键 - SQL涉及的字段分布:
uid:用户id,占比45%mid:消息编号,占比35%oid1,oid2,oid3…:其他字段,共计占比20%。
- 数据表名为:
- SQL语句:因为项目众多以及其他众多原因,有很多SQL不适合分库分表:
union、sub-select、(())、replace-into、case-when - 数据迁移:不停服
- 工期:90人天
- 版本:本文中的
sharding-sphere限定为3.0.0。
问题解决方案
下面依次分析解决各个场景中存在的问题。
选取分库分表中间件
经过多方面考虑,最终选取sharding-sphere 3.0.0作为分库分表中间件。
计算分表数量
根据量级以及多方面原因,最终确定了分表数量为32个,原因如下:
- 如果5年后数据量级为5亿,则单表数量级为:5亿/32 =1562.5万,可以保证单表性能要求。
- 如果以后进行扩容,可以考虑成倍扩容,比如扩容成
64个表。因为分表规则是取模,所以当分表数量成倍增加时,数据迁移工作量会小很多。 - 其他方面的考虑。
选取分表字段
分表最关键的是确认分表字段。
结合之前的数据结构,最终选取了uid(用户id)作为分表字段,考虑如下:
- 在所有的SQL中,此字段出现的频率相对最高。
- 此字段的业务意义在分表上说得通:即把一个用户id相关的所有记录存放在一个分表中。
包含分表字段的SQL不需要进行额外处理或者说只需要极少量改动即可,因为可以通过uid的值取模直接获取数据所在分表,也就是直接路由方式。
处理非分表字段
分表最头痛的是处理非分表字段。
如果包含分表字段uid的SQL占比高达90%,那么SQL即代码改造量会很小。但是实际情况是,55%的SQL不包含分表字段。
面对以上问题,短时间内想不到太好的解决方案,所以当时采用如下的窄表映射间接路由方案解决:
- 在一种数据库(db可以,缓存也可以)中,创建一种窄表映射结构,存储非分表字段至分表字段的映射关系,例如:
mid->uid。 - 所有不包含
uid但却包含mid的SQL,都可以首先通过mid的值得到uid的值,然后通过uid取模得到所在分表,也就是间接路由方式。
如何实施窄表映射间接路由方案也是一件头疼的问题,每个SQL都进行如此改造明显不现实,经过多方波折,最终形成了窄表缓存间接路由方案:
- 在
codis/redis中存储窄表映射信息,如:mid->uid、oid1->uid等。缓存的存储分为三种渠道:- 全量初始化:编写全量迁移程序,在上线初期,将MySql中的窄表映射关系,全量加载至缓存中,形成窄表缓存信息。
- 增量同步:编写增量迁移程序,在项目日常运行中,通过canal监听分表中窄表映射的变动信息,实时更新窄表缓存信息。
- 增量新增:二次开发
sharding-sphere,当执行insert语句时,同时写入缓存,避免写完即用类型的操作产生错误。
- 二次开发
sharding-sphere,对窄表缓存间接路由逻辑进行统一处理:- 支持多种操作的窄表缓存间接路由逻辑:
insert/replace、delete、update和select。 - 支持多个字段的窄表缓存间接路由逻辑:
mid、oid1、oid2 ...等
- 支持多种操作的窄表缓存间接路由逻辑:
通过上述窄表缓存间接路由方案,能够统一处理非分表字段,节省大量工作量,但是他有其局限性:
- 毕竟是通过
canal监听binlog的方式进行缓存同步,在DB与缓存的数据同步可能产生延时,遇到实时性要求高的SQL可能会有问题。 - 毕竟是粗暴的统一改造,有些接口的查询延时可能会稍稍增加,遇到延时要求高的SQL可能会有问题。
分布式键生成算法
原始雪花算法产生的问题
如果采用了分库分表,则必然需要使用分布式键代替原来的MySql自增主键。
项目前期设计采用原始雪花算法进行分布式键的生成,但是,原始雪花算法生成的值大于Math.pow(2, 53),十进制即9007199254740992。
这种长度的长整型在前端JavaScript处理时会丢失精度。
解决上述问题的方案有多种,关于后端的处理方式,可参考之前的博文:JavaScript处理Long型丢失精度的几种后端(Java)解决方案。
后端虽然能够处理,但是也有其局限性:
- 全局处理:简单粗暴,但是会对所有的
long型字段进行字符串转换,随之产生的缺陷难以预估。 - 局部处理:不会牵涉其他字段,但是程序修改工作量太大,难以实施。
当然,这个问题也可以通过前端进行处理,但是由于多方面因素,当时无法进行前端处理。
临时短值分布式键生成算法
最后为了既能使用分布式键,又能避免程序大量修改,采取了临时短值分布式键生成算法的解决方案。
此方案其实是原雪花算法的阉割版本,并且参考了Leaf——美团点评分布式ID生成系统。
下面对此算法的位数进行说明:
10 bits无效位。因缩短生成的值而空出来的位。1 bits原符号位,暂时无用。41 bits时间戳位,从2018年01月01日00时00分00秒000毫秒开始,可用约69年。7 bits工作机器id,取值范围[0,127]。5 bits单机器单毫秒内可产生的id数,即单机器毫秒并发数32。- 总结:有效位数共计
41 + 7 + 5 = 53,最大值为9007199254740992,即(long) 1 << 53。
关于workerId的生成机制
上述算法的其他比特位都可以通过代码生成,唯独workerId,它是雪花类算法在多服务节点运行时避免生成键重复的关键。
因为以下原因,需要自己实现一种workerId的生成机制:
workerId取值范围是[0 ~ 127],长度较短,无法直接通过IP地址等进行截取。- 因为历史原因,目前的服务器没有统一的命名方式,无法通过服务器名称进行截取。
最终通过ZooKeeper生成持久化节点的有序性这一特点,完成了workerId的生成机制,可参考下图:
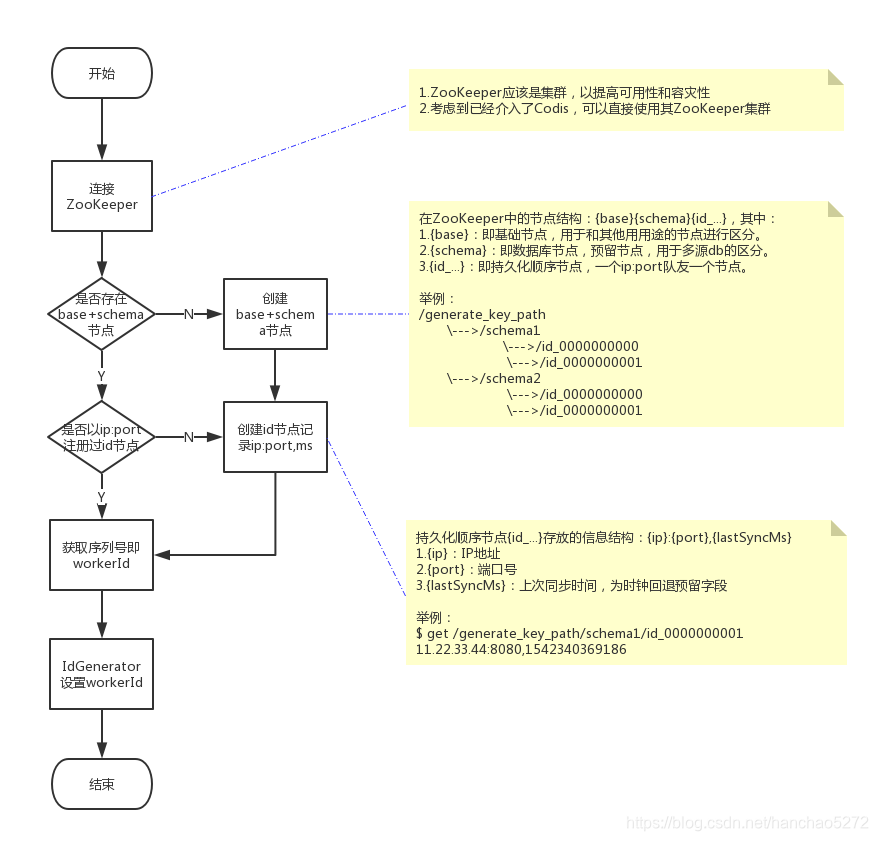
其实简单来说,就是以ip+port为关键信息,来唯一确定zk的一个持久化节点,那么ip和port的获取至关重要。
经过多次填坑,最终的ip和port的获取优先级如下:
ip: JVM变量中的IP >>>> 环境变量中的IP >>>> 容器中的IP >>>> 本机的IPport:环境变量中的PORT >>>> 配置文件中的PORT
项目改造
数据源改造
接入分库分表,会涉及部分持久层操作的代码改造,但不是全部。
为了不影响其他持久层的数据操作,需要采取多数据源策略,即:将分库分表的相关持久操作在单独的一个数据源中执行。
关于多数据源的配置,可以参考很久之前的文章:Spring Boot + Mybatis 配置多数据源。
SQL改造
sharding-sphere是不支持union、sub-select、(())、replace-into、case-when的,所以需要对涉及这些关键字的SQL进行改造。
具体的不支持SQL可详见官方文档:不支持的SQL。
主要的改造策略如下(只讨论我们的项目涉及的不支持的SQL类型):
union:可考虑拆分成多次单个查询然后进行合并。sub-select:通过拆分成多步查询。关于子查询的不支持规则详见不支持的SQL。(()):删除不必要的括号。replace-into:通过sharding-sphere二次开发支持replace-into语法。case-when:将case-when改造成if-else结构。
业务改造
上文已经提过,经过sharding-sphere的二次开发,通过窄表缓存间接路由策略可以节省大量涉及非分表字段的SQL的改造工作。
但是也会因为通用性处理的粗暴性,造成延时性、性能等方面的不足。对于此类接口,则不能再通过上述方案进行改造。
这种情况下, 需要综合考虑业务规则、代码逻辑和SQL语句,进行改造。一般的改造规则可以参考以下几点:
-
优先尝试通过在SQL中添加分表字段的方式解决。
-
如果1不可行,则尝试对代码逻辑和SQL语句进行整体性重构。
-
如果2不可行,则尝试通过其他数据库实现,比如通过
ElasticSearch实现聚集查询、分词查询等。 -
如果3不可行,则考虑本期不进行改造。因为线上会同时保留原始表和分表,这些业务也可正常运行。虽然效率不高,但是降低了本期改造风险,可以后期逐步修改。
sharding-sphere 3.0.0二次开发汇总
为了统一解决相似问题,节省开发工作量,对sharding-sphere 3.0.0版本进行了部分二次开发。这些二次开发主要包括:
- 由于历史原因,原有项目大量涉及
replace-into操作,故而通过二次开发,使之能够处理replace-into语句。 - 对
insert、replace、delete、update以及select语句,开发间接路由规则,使之能够进行窄表缓存间接路由。 - 开发
临时短值分布式键生成算法至sharding-sphere中,并通过ZooKeeper生成分布式键的workerId。 - 因
sharding-sphere会默认加载数据库中全部表的路由规则导致程序启动较慢,新增开关对是否全部加载进行管理。 - 在
insert和replace语句执行之后,立即完成对窄表缓存的更新。 - 修复
HintManager在单线程多Dao层调用场景中路由混乱的bug。 - 增加
Codis工具类,方便所有接入sharding-sphere的项目能够通过此类进行缓存操作。

















 1024
1024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









