







目标网站:电影票房网
目标网址:http://58921.com/daily/wangpiao
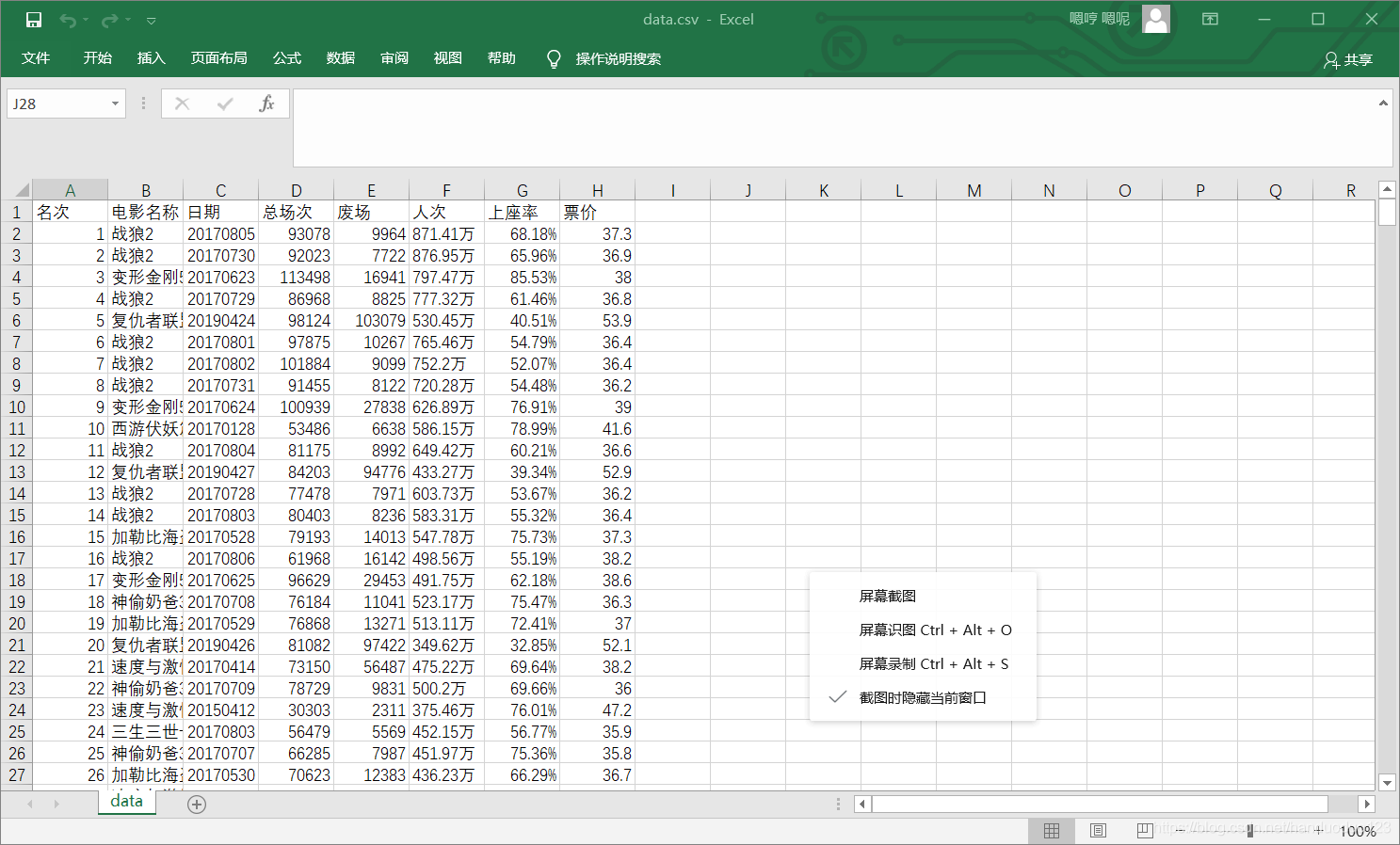
目标数据:(1)名次(2)电影名称 (3)日期(4)票房 (5)总场次(6)废场(7)人次(8)上座率(9)票价
任务要求
(1)使用urllib或requests库实现该网站网页源代码的获取,并将源代码进行保存;
(2)自主选择re、bs4、lxml中的一种解析方法对保存的的源代码读取并进行解析,成功找到目标数据所在的特定标签,进行网页结构的解析;
(3)定义函数,将获取的目标数据保存到csv文件中。
(4)使用框架式结构,通过参数传递实现整个特定数据的爬取。
下面展示一些 内联代码片。
import requests
from bs4 import BeautifulSoup
import bs4
import csv
def getHTMLText(url):
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36'
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except RequestException as e:
print('error', e)
def fillUnivList(ulist, url):
soup = BeautifulSoup(url, 'html.parser')
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
//票房一列为图片,tds[3]没有数据
ulist.append([tds[0].contents[0],tds[1].string,tds[2].string,tds[4].string,tds[5].string,tds[6].string,tds[7].string,tds[8].string])
def printHtml_csv(ulist):
with open('D:\data.csv','w',encoding='utf-8-sig',newline='') as csvfile:
fieldnames=['名次','电影名称','日期','总场次','废场','人次','上座率','票价']
writer=csv.DictWriter(csvfile,fieldnames=fieldnames)
writer.writeheader()
for i in ulist:
writer.writerow({'名次':i[0],'电影名称':i[1],'日期':i[2],'总场次':i[3],'废场':i[4],'人次':i[5],'上座率':i[6],'票价':i[7]})
def main():
uinfo=[]
for i in range(11):
urls={"http://58921.com/daily/wangpiao?page= "+ str(i)}
#print(urls)
for url in urls:
html=getHTMLText(url)
fillUnivList(uinfo,html)
printHtml_csv(uinfo)
main()
运行截图















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









