






#python爬虫 #python #Python链家二手房信息爬取 #网络爬虫
开发了一个简单的python程序爬取链家上南京小区的所有房源信息,数据内容包括 小区名称,单位面积均价,物业费,建成年代,户数(仅做研究学习之用)
效果如下
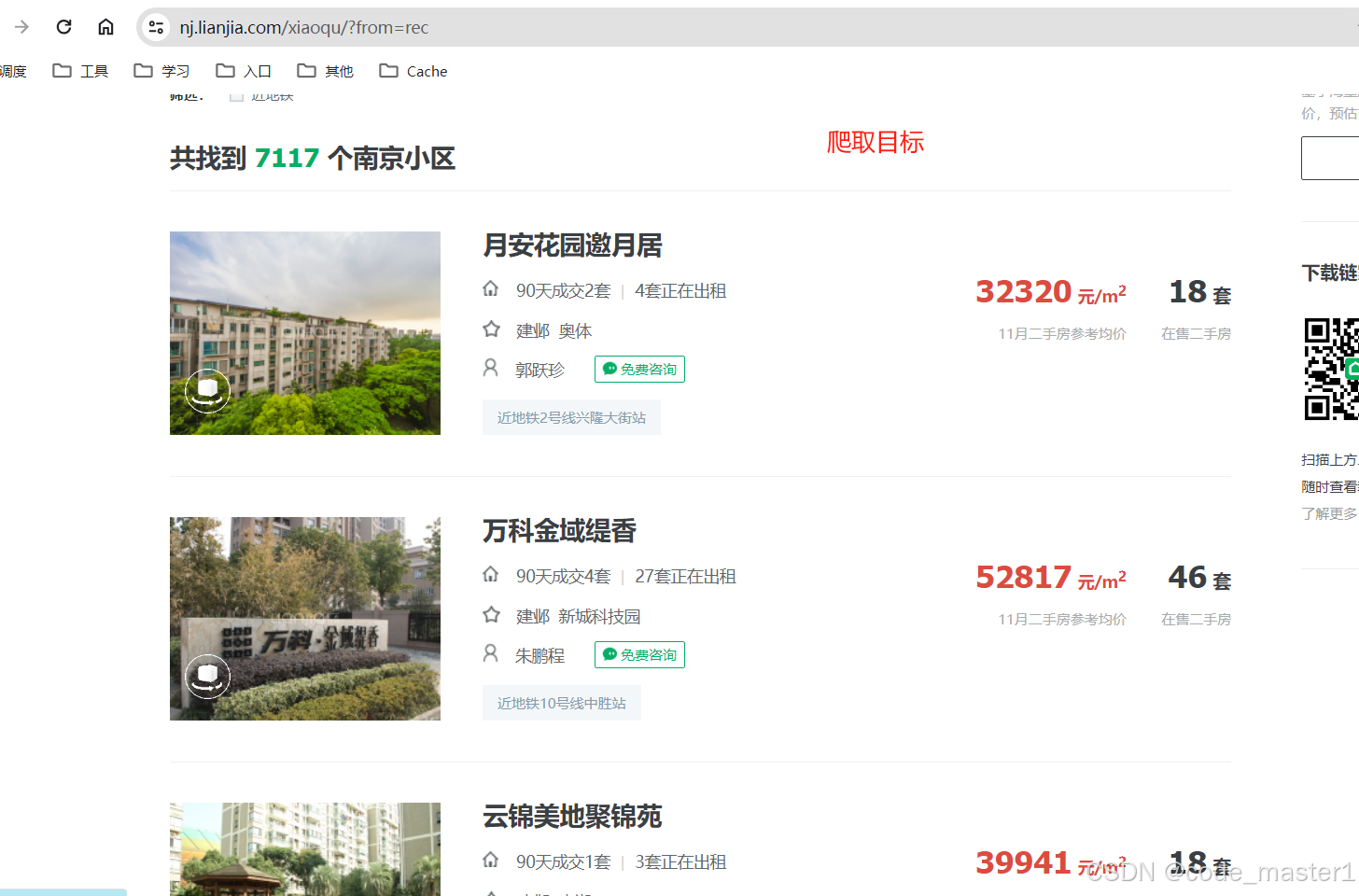
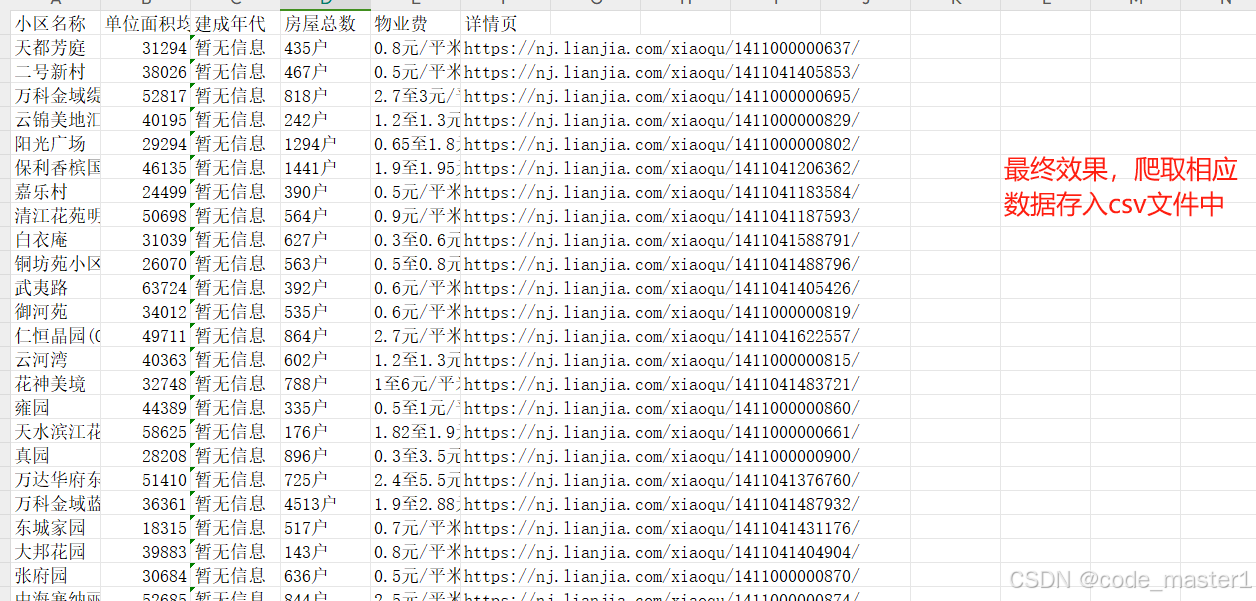
步骤如下
1.准备工作 python3.6以上版本 安装requests,bs4,random,time,csv包 浏览器,确保能正常访问链家网址 和 F12打开检查页
2.观察网页结构,基本思路为先获取首页信息拿到 小区名称 和 详情页地址,然后解析详情页信息,拿到户数,物业费等信息,最后翻页
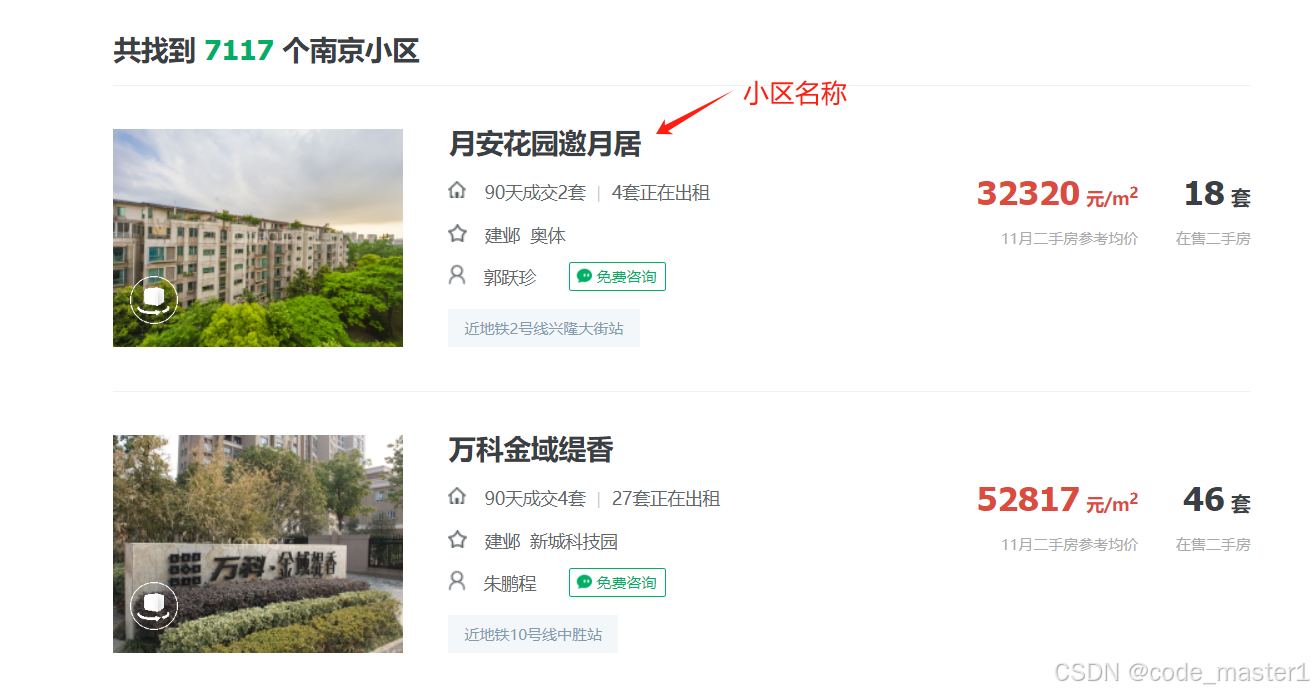
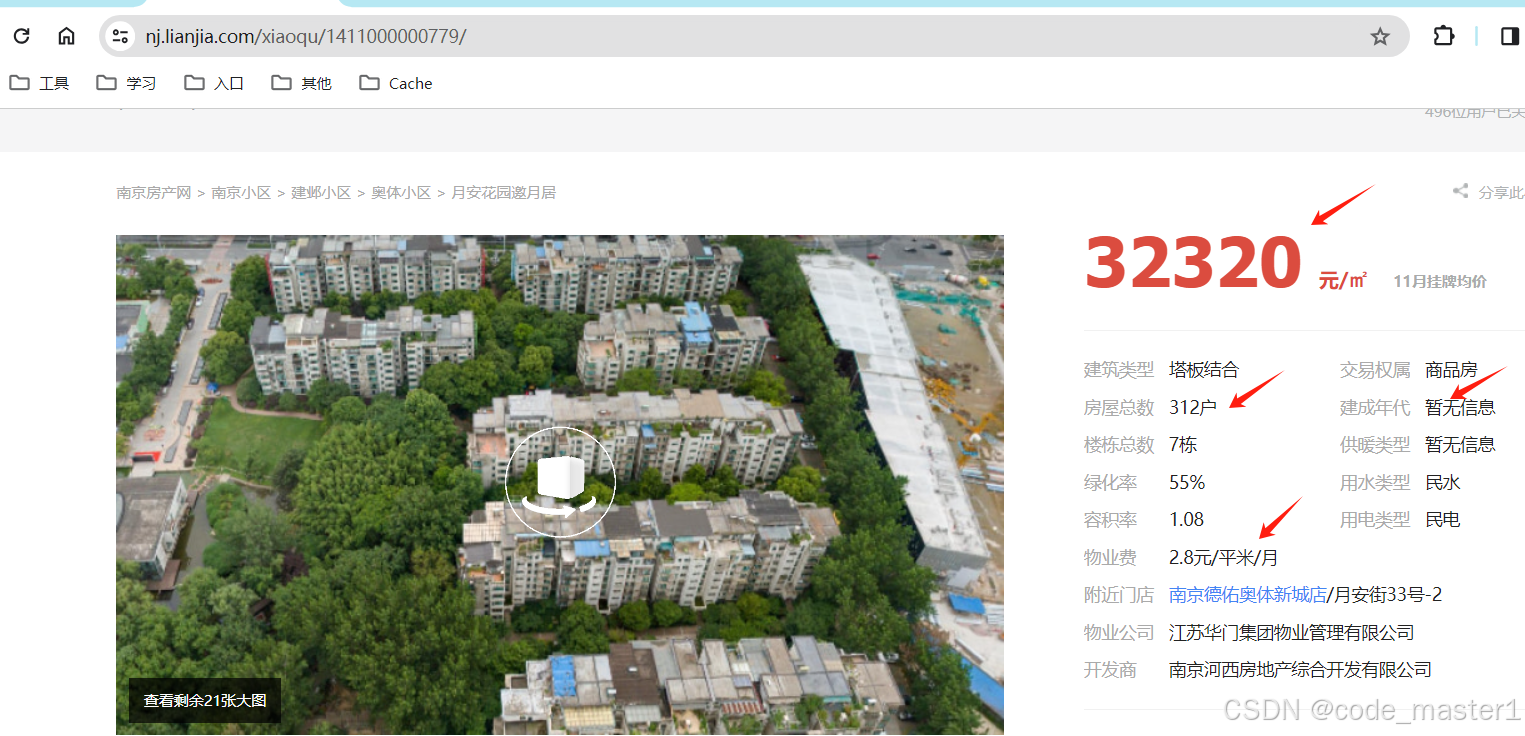
3.首页及详情页的获取,需要注意,大量数据爬取时需要在网页上登录并记录cookie等请求头信息,放在程序请求头中,防止反扒检测
4.解析首页,拿到小区名称及对应的详情页地址
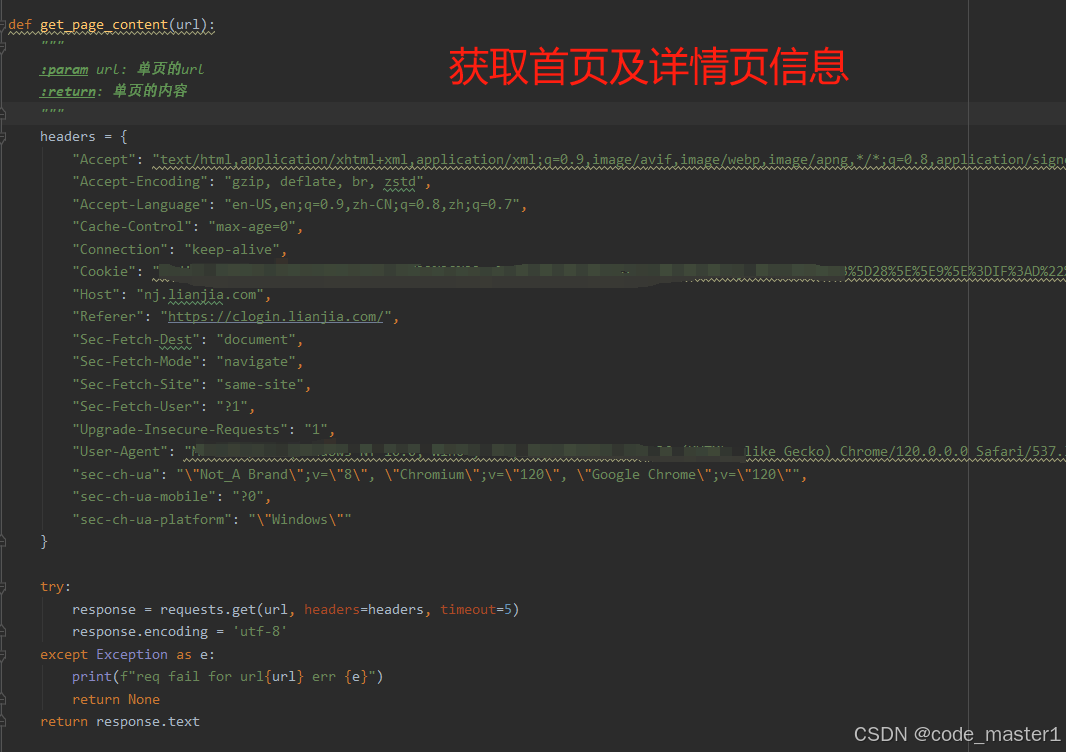
5.通过详情页地址再获取详情页信息
6.行翻页来获取所有的小区信息,主要思路为观察url特点来进行改写,加入pgX,即代表第X页
7.点击运行,即可以按页爬取相关信息并写入本地csv文件中
完整代码
#!usr/bin/python
"""
@Project :python_code
@File :lianjia.py
@Author :xx
@Date :xx
"""
import requests
from bs4 import BeautifulSoup
import random
import time
import csv
def get_page_content(url):
"""
:param url: 单页的url
:return: 单页的内容
"""
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "en-US,en;q=0.9,zh-CN;q=0.8,zh;q=0.7",
"Cache-Control": "max-age=0",
"Connection": "keep-alive",
"Cookie": "",
"Host": "nj.lianjia.com",
"Referer": "https://clogin.lianjia.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-site",
"Sec-Fetch-User": "?1",
"Upgrade-Insecure-Requests": "1",
"User-Agent": "",
"sec-ch-ua": "\"Not_A Brand\";v=\"8\", \"Chromium\";v=\"120\", \"Google Chrome\";v=\"120\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\""
}
try:
response = requests.get(url, headers=headers, timeout=5)
response.encoding = 'utf-8'
except Exception as e:
print(f"req fail for url{url} err {e}")
return None
return response.text
def parse_page_content(text, csv_writer, data_file):
"""
从首页的内容上解析出想要的信息写入文件,包括 小区名称、单位面积均价、建成年代、户数、物业费
:param text: 首页的内容
:param csv_writer: 文件写入工具
"""
info_keys = ['建成年代', '房屋总数', '物业费']
soup = BeautifulSoup(text, 'html.parser')
community_list = soup.find_all('div', class_='title')
# print(community_list)
succ_num = 0
fail_num = 0
for community in community_list:
print(community)
res_dict = dict(
{
'小区名称': "暂无信息",
'单位面积均价': "暂无信息",
'建成年代': "暂无信息",
'房屋总数': "暂无信息",
'物业费': "暂无信息",
}
)
time.sleep(random.randint(1, 3)) # 操作之间加入随机间隔时,避免程序操作太快被逮住
try:
tag = community.find('a')
name = tag.get_text()
res_dict['小区名称'] = name
href = tag.get('href')
res_dict['详情页'] = href
href_content = get_page_content(href)
soup = BeautifulSoup(href_content, 'html.parser')
info = soup.find('div', class_='xiaoquOverview')
unit_price = info.find('span', class_='xiaoquUnitPrice')
if unit_price is None:
res_dict['单位面积均价'] = "暂无数据"
else:
res_dict['单位面积均价'] = unit_price.text
item_infos = info.find_all('div', class_='xiaoquInfoItem')
ourter_item_infos1 = info.find_all('div', class_='xiaoquInfoItem ourterItem')
all_infos = item_infos + ourter_item_infos1
for part_info in all_infos:
if part_info is None:
continue
info_label = part_info.find('span', class_='xiaoquInfoLabel')
if info_label.text in info_keys:
info_content = part_info.find('span', class_='xiaoquInfoContent')
res_dict[info_label.text] = info_content.text
except Exception as e:
print(f"get community {community} info fail {e}, turn to next")
fail_num += 1
if len(res_dict) > 0:
print(res_dict)
if '详情页' in res_dict.keys() and res_dict['详情页'] is not None:
csv_writer.writerow(res_dict)
data_file.flush()
succ_num += 1
return succ_num, fail_num
if __name__ == '__main__':
with open('house_data2.csv', mode='a', encoding='utf-8', newline='') as data_file:
csv_writer = csv.DictWriter(data_file, fieldnames=[
'小区名称',
'单位面积均价',
'建成年代',
'房屋总数',
'物业费',
'详情页'
])
csv_writer.writeheader()
for i in range(200, 256):
url = f"https://nj.lianjia.com/xiaoqu/pg{i}/?from=rec"
if i == 1:
url = "https://nj.lianjia.com/xiaoqu/?from=rec"
print(f"----start get page {i} info-----")
res = get_page_content(url)
#print(res)
succ, fail = parse_page_content(res, csv_writer, data_file)
print(f"----end get page {i} info succ {succ} fail {fail}-----")


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









