







目录
1、底层构成
HashMap底层是基于数组+链表+红黑树。
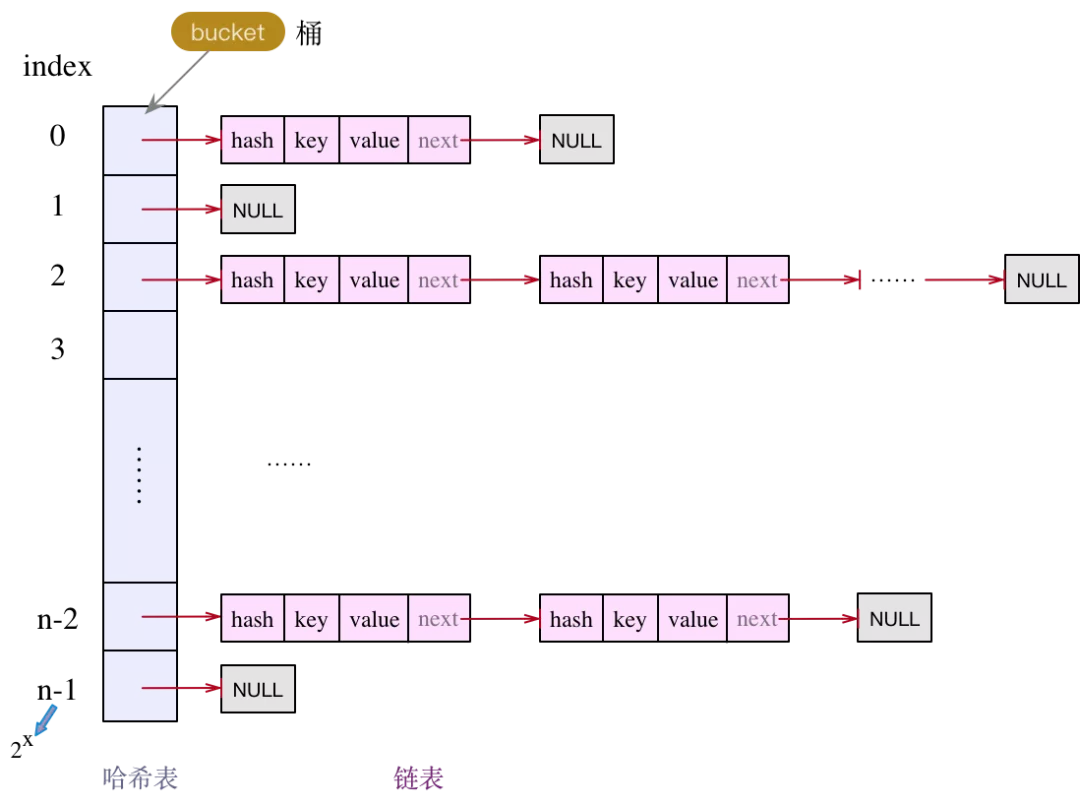


默认初始容量为(数组长度为**16),默认负载系数为0.75(这个表示的意思是扩容机制当容量达到75%的时候自动进行扩容(扩大一倍,扩容也是采用位运算【因为用乘法会影响CPU的性能,计算机不支持乘法运算,最终都会转化为加法运算[01的方式]。】),当扩容的时候,会创建新的数组,以前存放在数组中的数据将会重新通过hashCode进行排序,类似于hashCode/16取模【其实使用的是位运算,位运算效率更高】得到下标存放在对应的数组中,扩容后hashCode/32.)。
2、底层原理:
1.先通过hash算法计算出当前键值的hashCode值,然后对数组长度进行取余【其实是位运算】,从而获得余数(即为下标)存储到对应的数组中【存储的是当前hash值(key计算的hash值),key,value和next】(所以HashMap存取数据元素是无序的)。[底层是位运算,性能更好,且可以更好的避免哈希碰撞]
2.通过下标存储键值时,如果当前下标没有存放其他键值时会直接存入,如果该下标处,已经存在其他键值时,则会发生哈希碰撞。
3.发生哈希碰撞后,会继续比较下标处所有key的equals(内容)是否为true(来判断是不是同一个元素。)
如果是true,表示是相同的key,执行覆盖操作。
如果是false,表示是不同的key,执行在最后一个键值对后面追加操作,从而形成单向链表(链表的产生)。
4.如果链表长度>=8个且当前Map集合中数组长度>=64个,则会形成红黑树;如果当前数组长度<64个,则会扩容键值对数组(16*2),而且会重新进行排序。(并且会重新将所有键值对对32进行取余重新排序进行存储从而导致效率低)
5.当调用remove方法的时候,会删除元素,当红黑树中剩余的键值对个数<=6个的时候,会重新还原成单向链表。(性能更好)
3、如何解决hash冲突? 解决哈希冲突(四种方法)_
1、拉链法,将产生hash碰撞的元素都链接到同一个链表中【形成链表结构】
2、再Hash法,将产生hash碰撞的元素再采用不同的哈希算法进行处理,直至没有哈希冲突。
3、建立公共溢出区,把哈希表分为基本表和溢出表,将产生哈希冲突的元素存储到公共溢出表
4、开放寻址法:将产生hash碰撞的元素,去寻找一个新的空闲的哈希地址
4、开放寻址又包含了
1、线性探测法:就是将在得到的hash值进行加1然后对数组长度取模,直到直到新的位置。
公式:h(x)=(Hash(x)+i)mod (Hashtable.length);(i会逐渐递增加1)
2、平方探测法(二次探测):就是将在得到的hash值进行依次为+(i^2)和-(i^2)然后对数组长度取模,直到直到新的位置。
公式:h(x)=(Hash(x) +i)mod (Hashtable.length);(i依次为+(i^2)和-(i^2))
5、HashMap在什么情况下扩容?
默认初始容量为(数组长度为16),默认负载系数为0.75(这个表示的意思是扩容机制当容量达到75%的时候自动进行扩容(扩大一倍),当扩容的时候,会创建新的数组(数组中村的entry对象,key是对象通过hash算法运算后取模后的值,value是真正的对象),以前存放在数组中的数据将会重新通过hashCode进行排序 ,类似于hashCode/16取余得到下标存放在对应的数组中,扩容后hashCode/32.)。
HashMap的扩容公式:initailCapacity * loadFactor 【负载因子】= HashMap
其中initailCapacity是初始容量:默认值为16(懒加载机制,只有当第一次put的时候才创建)
采用位运算的方式1*2的4次方
其中loadFactor是负载因子:默认值为0.75
默认扩大一倍。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









