







分享一下JS中很基础也很重要的概念:执行上下文(Execution Context);
将我们的代码进行分类:
1.代码分类(位置):
* 全局代码
* 函数(函数)代码.
2.全局执行上下文
(1) 在执行全局代码前将window确定为全局执行上下文
(2)对全局数据进行预处理
* var定义的全局变量===>undefined,添加为window的属性
* function声明的全局函数===>赋值(fun),添加为window的方法
* this===>赋值(window)
(3) 开始执行全局代码
3.函数执行上下文
(1) 在调用函数,准备执行函数体之前,创建对应的函数执行上下文对象
(2) 对局部数据进行预处理
* 形参变量==>赋值(实参),添加为执行上下文的属性
* arguments==>赋值(实参列表),添加为执行上下文的属性
* var定义的局部变量==>undefined,添加为执行上下文的属性
* function声明的函数==>赋值(fun),添加为执行上下文的属性
* this==>赋值(调用函数的对象)
(3) 开始执行函数体代码
// 全局执行上下文
console.log(a1) // undefined
console.log(a2) // 可以访问到
var a1 = 3
function a2(){}
// 函数执行上下文
function fn(b1){
console.log(b1) // 2
console.log(b2) // undefined
console.log(b3)
b3()
console.log(this) // window
console.log(arguments) //[2,3]伪数组
var b2 = 3
function b3(){
console.log('b3')
}
}
fn(2,3)JS中并没有严格意义上区分栈内存和堆内存,因此我们可以简单粗暴的理解为JavaScript的所有数据都保存在堆内存中。但是在某些场景,我们仍然需要基于堆栈数据结构的思维来实现一些功能,比如JavaScript的执行上下文.执行上下文的执行顺序借用了栈数据结构的存取方式。(也就是我们说的函数调用栈).
栈的存取方式是先进后出.
当代码的执行过程中,遇到全局代码和函数代码都会生成一个执行上下文放入栈中,而处于栈顶的上下文执行完毕之后,就会自动出栈。
执行上下文栈:
1.在全局代码执行前,JS就会创建一个栈来储存管理所有的执行上下文对象
2.在全局执行上下文(window)确定后,将其添加到栈中(压栈)
3.在函数执行上下文创建后,将其添加到栈中(压栈)
4.当当前函数执行完后,将栈顶的对象移除(出栈)
5.当所有的代码执行完后,栈中只剩window(全局上下文)
注意: 1.全局上下文在浏览器窗口关闭后出栈
2.函数执行中,遇到return直接终止可执行的代码,会直接将当前上下文弹出栈
function f1(){
var n=999;
function f2(){
console.log(n);
}
return f2;
}
var result=f1();
result(); // 999
console.log(result)我们分析一下这段代码中执行上下文的顺序:
第一步,首先是全局上下文入栈
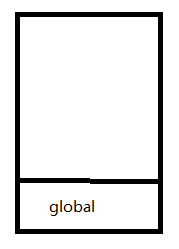
全局上下文入栈之后,其中的可执行代码开始执行,直到遇到了f1();这一句激活函数f1创建它自己的执行上下文,因此第二步就是f1的执行上下文入栈。
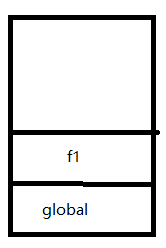
f1中的可执行代码并没有调用f2,所以没有创建新的上下文,直到return f2时才创建.这时候f1可执行代码完毕,出栈
遇到result(),创建result的执行上下文

执行result中的可执行代码,输出n,执行完毕后,result出栈
这个时候只剩下全局上下文,全局上下文在浏览器窗口关闭后出栈.
对执行上下文总结一下:
- 执行上下文是单线程的
- 是同步执行,只有栈顶的上下文处于执行中,其他上下文需要等待
- 全局上下文只有唯一的一个,它在浏览器关闭时出栈
- 函数的执行上下文的个数没有限制
- 每次某个函数被调用,就会有个新的执行上下文为其创建,即使是调用的自身函数,也是如此。














 562
562











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









