







Hbase
概念及其使用场景
Hbase是基于HDFS分布式存储的分布式数据库,它可以用于存储海量数据,有效的对海量数据进行增删改查操作。
适用的场景主要包含两个条件:1.海量数据 2.多运用于增删改查操作。
存储结构
Hbase组织表的结构为<Key,Value>的形式,每一行的数据都会有一个row_key用作每一行的主键,这个row_key的大小限制为64KB,还会有一系列的列簇,列簇也是<Key,Value>的形式,也就是说,对每一个列簇都会有一个key值来指定该列簇,每一个列簇中可以包含很多列与其列值。其基本的形式为:
| Row_key | Cloumns_clus1 | Cloumns_clus2 | Cloumns_clus3 |
| ********* | Cloumn1_key:value Cloumn2_key:value |
| Cloumn3_key:value |
Hbase的存储是按照列存储的形式存储的,当遇见值为null的列的时候可以直接不存,这样极大的减少了存储空间,实现了压缩。Hbase的底层数据存储结构是HDFS,所以在存储的时候也是将数据存放在HDFS中,在其基础上建立表结构,其中,建立的表默认大小是256MB,也就是说,当大于256M的时候,表会被自动切分成两个,我们称每一个部分为一个region,每一个表也就是table中会有很多region,每一个region会被放在regionserver上。如图所示:
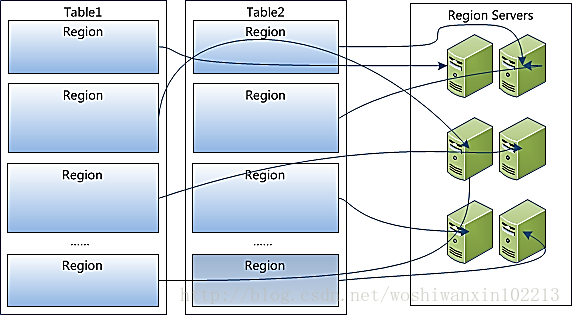
每一个region中会包含很多store,每一个store都会存储一个列簇,每个store又由一个memStore和零-多个StoreFile组成,StoreFile以HFile的格式保存在HDFS上。具体过程为:
主要的操作
Hbase主要的操作有get,put,scan,delete,update。由于他的存储所限制,他并不能像Mysql这样的数据库一样支持多表联合查询,它主要支持的操作为增删改查。
put:增加一条数据,直接通过指令向Hbase中传输
delete:删除一条数据,实际上数据并不是直接被删除了,而是对这条数据加上‘delete’标签,在等下一次数据更新的时候会一并处理
update:更新数据,实际上原来的旧的数据并不会直接被换成新的,这时候就需要用到时间戳这个属性,我们会将新的数据插入,打上最新的时间戳,那么在查找数据的时候,系统会默认查找时间戳最新的数据,当然我们也可以指定时间戳来查找以前的数据。
get:通过Hbase将所需的数据get下来,一般情况下,get数据操作是每次只能get一条数据的,也就是说,每次只能用一个row_key去查找该条数据,当然,我们也可以将一些row_key存放在一个list中,实现批量get
scan:他也是用来获取数据的,但是他的使用与get的最大的区别在于他可以根据一个row_key的范围来进行批量下载,这是因为row_key是有序的。
Hbase的索引格式
为了加快查询的速度,索引结构是必不可少的。那么怎么很快的定位到每一个region呢,Hbase所使用的索引结构是LSM-Tree,其基本结构和B+树结构很相似。其树形结构主要是三层的树形结构。其细节如下:
第一层:保存在zookeeper里面的文件,他保存着root region的位置。
第二层:root region保存的是.META表中每一个region的信息,通过root region,我么就可以访问到.META中的所有region数据的信息。
第三层:.META,它是一个特殊的表,他保存了Hbase中所有数据表的region的位置信息。
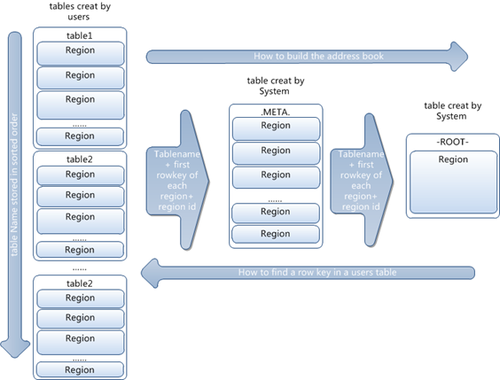
说明:1. root region永远不会被划分,保证了最多需要跳三次就可以定位到任意的region。
2. .META表每一行保存一个region的位置信息,row_key采用表名来存储
3. 为了加快访问.META表的全部region都保存在内存中。
假设, .META.表一行在内存中大约占用1KB。并且每个region限制为128MB。那么上面的三层结构可以保存的region数目为:
(128MB/1KB) * (128MB/1KB) = = 2(34)个region
但是对于LSM树的建立过程来说,新的数据进来时实现会放在内存中,内存中的数据会建立局部的树形结构,然后当内存中的数据满的时候,索引和数据一起更新,数据需要持久化到磁盘中,而索引会进行合并操作,磁盘上的树形结构也可以被拆分成独立的小单元。查找是先查找内存中的存储,然后再查找磁盘上的文件。















 363
363

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









