







参考视频: 【黑马程序员】2020最新数据结构与算法教程(求职面试必备)
参考leetcode学习资料: 图解算法数据结构
文章目录
- 冒泡,选择,插入排序最坏情况下的时间复杂度为O(N^2)
- 后面是高级排序
第二章 排序
2-1 Compareble接口
-
简单排序 :在java的开发工具包jdk中, 给我们提供了 很多数据结构和算法的实现, 比如List , Set ,Map , Math等等, 都是以API的方式提供,
- 借助jdk的方式,将算法封装到某个类中,在我们写java代码之前,就要进行API的设计,随后进行API的实现
-
设计一套API如下 :
类名 ArrayList 构造方法 Array List() : 创建ArrayList对象 成员方法 1. boolean add( E e) : 向集合中添加元素
2. E remove(int index) : 从集合中删除指定的元素 -
由于要讲排序,会在元素之间进行比较,而java提供一个接口Comparable就是用来定义排序规则的
- 需求 :
- 定义一个学生类Student, 具有年龄age 和姓名 username 两个属性, 并通过Compareble接口提供比较规则
- 定义测试类Test,在测试类中定义测试方法Comparable getMax(Comparable c1,Comparable c2)完成测试
- 需求 :
-
不只对数据进行排序,对所有实现了Comparable接口的对象进行排序
2-2 冒泡排序
让最大的元素冒到后面去
-
冒泡排序API设计 :
类名 Bubble 构造方法 Bubble() : 创建Bubble对象 成员方法 1. public static void sort(Comparable[] a) : 对数组内的元素进行排序
2. private static boolean greater(Comparable v,Comparable w) : 判断v是否大于w
3. private static exch (Comparable[] a,int i,int j) : 交换a数组,索引i和索引j处的值 -
冒泡排序的时间复杂度分析 :
-
使用了双层for循环,其中内层循环的循环体是真正完成排序后的代码,我们分析冒泡排序的时间复杂度,主要分析内层循环体的执行次数即可
-
最坏情况下,也就是假如要排序的元素为{6,5,4,3,2,1}逆序,那么 :
-
元素比较的次数为:
(N-1)+(N-2)+…+1 = ((N-1)+1)*(N-1)/2 = N^2/2-N/2;
-
元素交换的次数 :
(N-1)+…+1 = 同上
-
总执行次数 :
(N^2/2 - N/2)+(N^2/2-N/2)=N(N-1)
-
-
-

2-3 选择排序
选出最小的元素放在前面
-
每一次遍历的过程中,都假定第一个索引处的元素是min,和其他索引处的值依次比较,最后得到min所在的索引
-
选择排序API
类名 Selection 构造方法 Selection() : 创建Selection对象 成员方法 1. public static void sort(Comparable[] a) : 对数组内的元素进行排序
2. private static boolean greater(Comparable v, Comparable w): 判断v是否大于w
3. private static void exch(Comparable[] a,int i ,int j) :交换a数组中索引i和索引j处得值 -
选择排序的时间复杂度分析 ;
-
使用双层for循环,其中外层循环完成了数据交换,内层循环完成了数据比较,分别统计数据交换次数和数据比较次数
-
数据比较次数 :
(N-1)+(N-2)…+1=N(N-1)/2
-
数据交换次数 :
N-1
-
时间复杂度:N(N-1)/2+N-1
-
根据大O推导法则,保留最高阶项,去除常数因子,时间复杂度为O(N^2)
-
2-4 插入排序(Insertion sort)

-
插入排序的工作方式是一种简单直观且稳定的排序算法
-
- 把所有的元素分为两组,已经排序的和未排序的
- 找到未排序的组中的第一个元素,向已经排序组中进行插入
- 倒叙遍历已经排序的元素,依次和待插入的元素进行比较,直到找到一个元素小于等于待插入元素,那么就把待插入的元素放到这个位置,其他的元素向后移动一位
-
插入排序API设计 :
类名 Insertion Insertion():创建Insertion对象 1. public static void sort(Comparable[] a):对数组内的元素进行排序
2. privte static boolean greater(Comparable v,Comparable w): 判断v是否大于w
3. private static void exch(Comparable[] a,int i,int j): 交换a数组中索引i和索引j处的值 -
插入排序的时间复杂度分析:(最坏情况)
- 待排序的数组元素 {12,10,6,5,4,3,2,1}
- 比较的次数: (N-1)+(N-2)+…1
- 交换的次数: 同上
- 执行的总次数:N*2-N
----------------> 大O推导法: O(n*2)
2-5 希尔排序(Shell缩小增量排序)
-
希尔排序是插入排序的一种,又称为“缩小增量排序”,是插入排序算法的一种更高效的改进版本
-
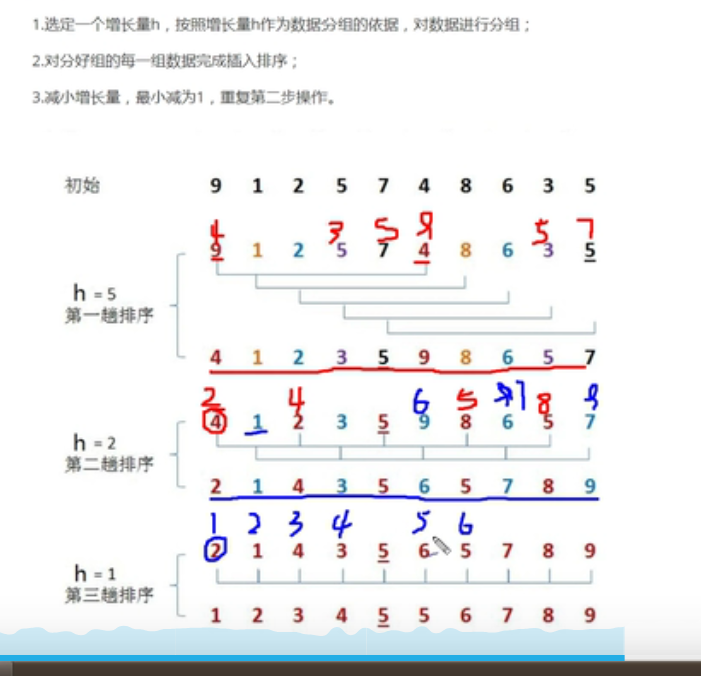
排序原理 :
- 选定一个增长量,按照增长量h作为数据分组的依据,对数组进行分组
- 对分好组的每一组数据完成插入排序
- 减小增长量,最小减为1,重复第二步操作
-
增长量h的确定 : 增长量h的值每一固定的规则,采取以下规则:
int h = 1; while(h < 数组的长度/2){ h = 2h+1; //3,7 } // 循环结束后我们就可以确定h的最大值 h的减小规则为 : h = h/2 // 7/2=3 ; 3/2=1
2-5-1 希尔排序的API设计
-
类名 Shell 构造方法 Shell():创建Shell对象 成员方法 1. public static void(Comprable[] a): 对数组的元素进行排序
2.private static boolean greater(Comparable v, Comprable w):判断v是否大于w
3.private static void exch(Commparable[] a, int i,int j): 交换a数组中,索引i和索引j处的值
2-5-2希尔排序的时间复杂度分析
- 事后分析法对希尔排序进行时间复杂度的分析
2-6 归并排序(这是第四五遍,我懂了!!!离打谱事件!)
2-6-1 归并排序–递归(StackFlowOver)
-
递归算法----定义方法时,在方法内部调用方法本身,称之为递归
public void show(){ sout("aaa"); show(); } -
作用:通常把一个大型复杂的问题,层层转换为一个与原问题相似的,规模较小的问题来求解。递归只需要少量的程序就可以描述出接替过程所需要的多次重复计算,大大减少了程序的代码量
-
注意事项 : 在递归中,不能无限制的调用自己,必须要有边界条件,能够让递归结束,因为每一次递归调用都会在栈内存开辟新的空间
- 重复执行方法,如果递归的层级太深,很容易造成栈内存溢出
-
定义一个方法,使用递归完成求N的阶乘 :
分析: 1!: 1 2!: 2*1=2*1! 3!: 3*2*1=3*2! ... n!: n*(n-1)*(n-2)*...*2*1 = n*(n-1)! // 所以,假设有一个方法factorial(n)用来求n的阶乘,那么n的阶乘还可以表示为n*factorial(n-1)-
package test.test_child; public class Testfactorial { public static void main(String[] args) { // 求N的阶乘 long result = factorial(5); System.out.println(result); } // 求n的阶乘 public static long factorial(int n){ if (n==1){ //结束条件 return 1; } return n*factorial(n-1); } }
-
2-6-2 归并排序【分治思想】
-
归并排序是在建立在操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;
- 即先使每个子序列有序,再使子序列段间有序。
- 若将两个有序表合并成一个有序表,称为二路归并。
-
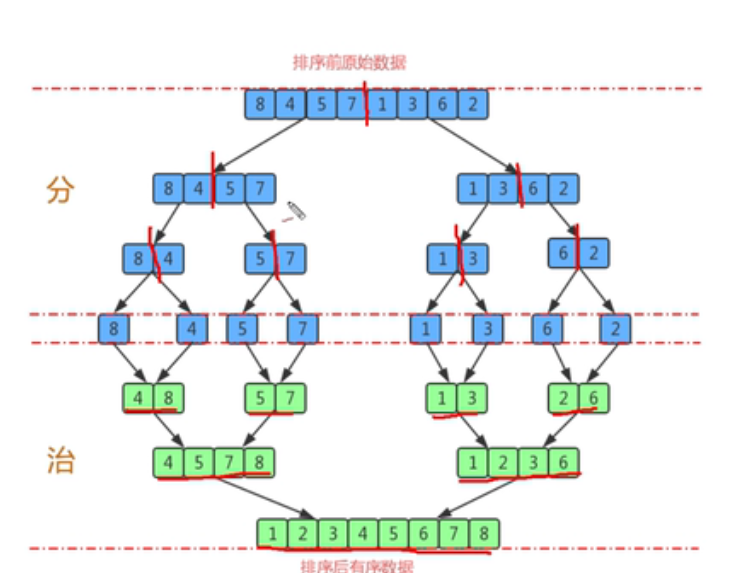
排序原理 :
- 尽可能的一组数据拆分成两个元素相等的子组并对每一个子组继续拆分,直到拆分后的每个子组的元素个数是1为止
- 将相邻的两个子组进行合并成一个有序的大组
- 不断的重复步骤2,直到最终只有一个组为止。
-
归并排序API设计
类名 Merge 构造方法 Merge():创建Merge对象 成员方法 1. public static void sort(Comparable[] a):对数组内的元素进行排序
2. private static void sort(Comparable[] a,int Io,int hi) : 对数组a中从索引lo到索引hi之间的元素进行排序
3. private static void merge(Comparable[] a,int lo, int mid, int hi): 从索引lo到索引mid为一个子组, 从索引mid+1到索引hi为另一个子组,把数组a中的这两个子组的数据合并成一个有序的大组(从索引lo到索引hi)
4. private static boolean less(Comparable w): 判断v是否小于w
5. private static void exch(Comparable[] a,int t,int j): 交换a数组中,索引i和索引j处的值成员变量 private static void Comparable[] assist : 完成归并操作需要的辅助数组
4.
2-6-3 归并排序的时间复杂度进行分析
-
思想:
- 分治思想,通过递归调用将他们进行单独排序,最后将有序的子数组归并为最终的排序结果。
- 该递归的出口在于如果一个数组不能在被分为两个子数组,那么就会执行merge归并,在归并的时候判断元素的大小进行排序
-
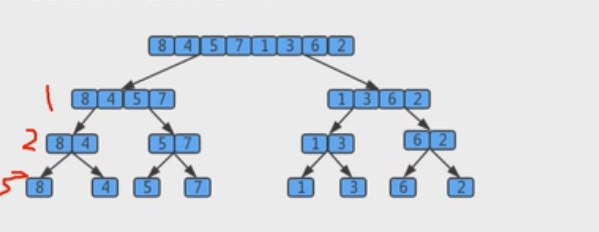
- 用树状图来描述归并,如果一个数组有8个元素,那么它将每次除以2找到最小的子数组,共拆log8次值为3;
- 所以树共有三层,那么自顶向下第k层有2k个子数组,每个数组的长度为2(3-k),归并最多需要2^(3-k)次比较
- 因此每层的比较次数为2k*2(3-k) = 2^3
- 那么3层总共为3*2^3
-
时间复杂度的算法:
- 假设元素的个数为n,呢么使用归并排序拆分的次数为log2(n),所以共log2(n)层,那么使用log2(n)替换上面3*2^3中的3这个层数,
- 最终得出的归并排序的时间复杂度为:log2(n)*2^(log2(n)) = log2(n)*n,根据大O推导法则,忽略底数,最终归并排序的时间复杂度为O(nlogn);
-
归并排序的缺点
- 需要申请额外的数组,导致空间复杂度提升,是典型的以空间换时间的操作
-
归并排序的与希尔排序的的性能是由于插入排序的
- 希尔排序和归并排序的性能测试 :
- 这里没有去写,我好累呀!!!开玩笑
- 希尔排序和归并排序的性能测试 :
2-7 快速排序
2-7-1 快速排序1
-
简介 :
- 快速排序是对冒泡排序的一种改进
- 基本思想: 通过一趟排序将要排序的数据分隔为独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小
- 再按照此方法对这两部分数据继续快速排序
- 整个排序过程可以递归进行,依次达到整个数据变成有序序列
-
排序原理 :
- 首先设定一个分界值,通过该分界值将数组分为左右两个部分
- 将大于或等于分界值得数据放到数组右边,小于分界值得数据放到数组的左边,此时左边部分中各元素都小于或等于分界值
- 然后,左边和右边的数据可以独立排序,对于左右两侧的数组数据可以取一个分界值,重复第二部操作
- 重复上述操作,这是一个递归定义。
2-7-2 快速排序API设计
-
类名 Quick 构造方法 Quick{}:创建Quick对象 成员方法 1. public static void sort(Comparable[] a) : 对数组内的元素进行排序
2. private static void sort(Comparable[] a,int lo,int hi) : 对数组a中从索引lo到索引hi之间的元素进行排序
3. public static boolean less(Comparable x,Comparable w): 判断v是否小于w
4. private static int partition(Comparable []a,int lo,int hi): 对数组a中,从索引lo到索引hi之间的元素进行分组,并返回分组界限对应的索引
5. private static void exch(Comparable[] a,int i,int j): 交换a数组中,索引i和索引j处的值 -
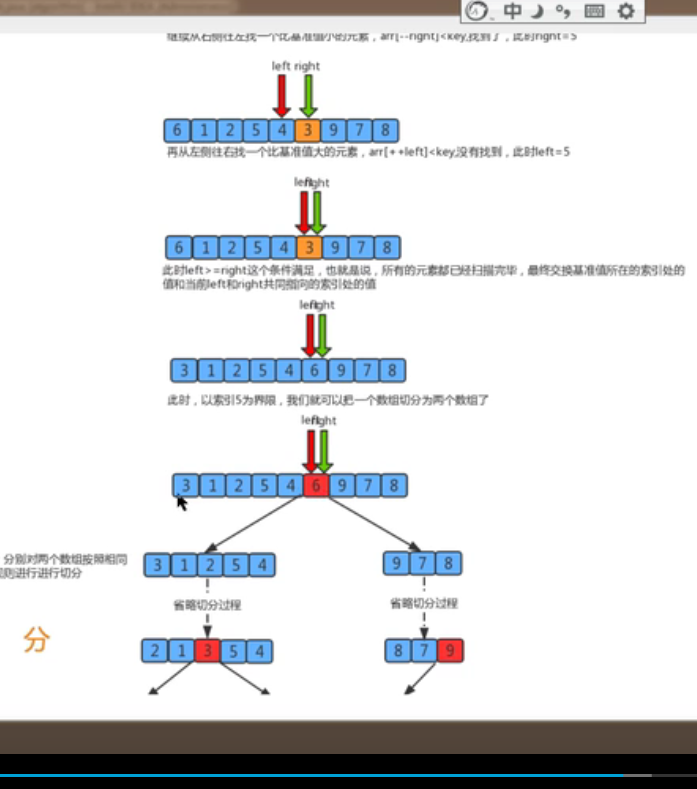
把一个数组切分成两个子数组的基本思想:
- 找一个基准值,用两个指针分别指向数组的头部和尾部
- 先从尾部向头部开始搜索一个基准值小的元素,搜索到即停止,并记录指针的位置
- 再从头部开始向尾部开始搜索一个比基准值大的元素,搜索到即通知,并记录指针的位置
- 交换当前左边指针位置和右边指针位置的元素
- 重复2,3,4步骤,直到左边指针的值大于右边指针的值停止
2-7-3 快速排序和归并排序的区别:
-
分治思想: 快+归
- 归并排序将数组分为两个子数组分别排序,并将有序的组数组归并从而将整个数组排序
- 快速排序是当两个数组都有序时,整个数组自然就有序了
-
快速排序时间复杂度分析:
-
快速排序的一次切分从两头开始交替搜索,直到left和right重合,因此,一次切分算法的时间复杂度为O(n),但整个快速排序的时间复杂度和切分的次数相关
-
最优情况 : 每一次切分选择的基准数字刚好将当前序列等分,O(nlogn);
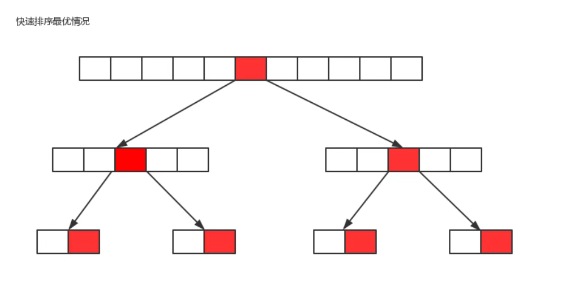
-
最坏情况: 每一次切分选择的基准数字是当前序列中最大数或者 最小数,这使得每次切分都会有一个子组,总共切分n次,最坏情况下,快速排序的时间复杂度为O(n^2)
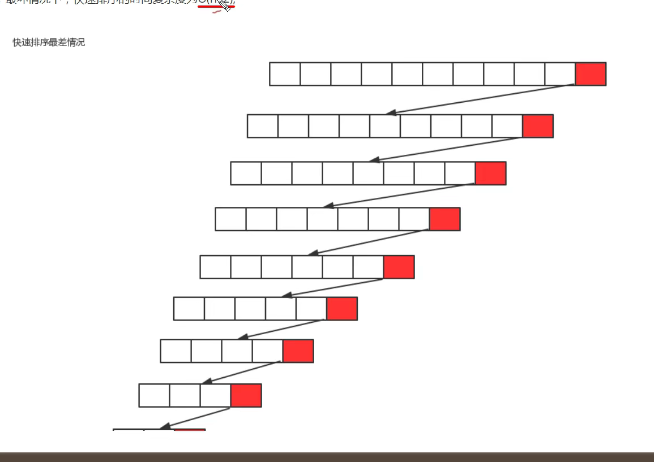
-
平均情况: 每一次切分选择的基准数字不是最大值也不是最小值,也不是中值,时间复杂度为O(nlogn)
-
2-8 排序的稳定性
- 数组arr中有若干元素,其中A元素和B元素相等,并且A元素在B元素前面,如果使用某种排序算法排序后,能够保证A元素依旧在B元素的前面,可以说这个该算法是稳定的
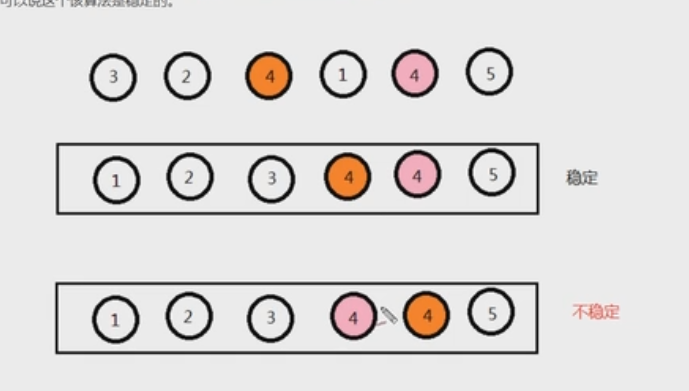
- 稳定性的意义: 如果一个数据只需要一次排序,则稳定性一般没有意义;如果一组数据需要多次排序,稳定性是有意义的
- 例如要排序的内容是一组商品对象,第一次排序按照价格有低到高排序;
- 第二次排序按照销量由高到低排序,如果第二次排序使用稳定性算法,就可以使得相同销量的对象依旧保持价格高低的顺序展现,
- 只有销量不同得对象才需要重新排序,这样就可以保持第一次排序得原有意义,而且可以减少系统开销
- 分析各个排序:
- 冒泡排序: 只有当arr[j]>arr[j+1]时,才会交换元素的位置。稳定
- 选择排序: 不稳定
- 希尔排序:不稳定
- 归并:稳定
- 快速:不稳定
每日小知识:为啥子我直接粘贴笔记,不会显示“图片外链无法获取”,因为我的typora搭有图床:
- 参考博客:Gitee搭建免费博客
- 老方便了,随后搭个博客平台或者把文件发给别人,都不用发愁自己的图片发不出去了
笔记在博主本人的博客上也有奥!全套!!!
- 翼遥bingo【持续完善中,biu~~】















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









