







 本文详细介绍了Java项目架构、Spring请求处理流程、Interceptor与Filter的区别,以及JVM的结构,包括类加载器、运行时数据区、执行引擎等关键概念。还探讨了堆栈区别、线程状态、设备数据读取、网络连接状态等问题,进一步涉及NIO、Sentinel、Redis主从复制、Spring AOP动态代理、MQ交换机作用等高级话题,深入讲解分布式锁、QPS计算和并发容器等技术细节。
本文详细介绍了Java项目架构、Spring请求处理流程、Interceptor与Filter的区别,以及JVM的结构,包括类加载器、运行时数据区、执行引擎等关键概念。还探讨了堆栈区别、线程状态、设备数据读取、网络连接状态等问题,进一步涉及NIO、Sentinel、Redis主从复制、Spring AOP动态代理、MQ交换机作用等高级话题,深入讲解分布式锁、QPS计算和并发容器等技术细节。
1. 项目架构总结,分析HA
2. spring请求处理流程
In Spring MVC all incoming requests go through a single servlet. This servlet - DispatcherServlet- is the front controller. Front controller is a typical design pattern in the web applications development. In this case, a single servlet receives all requests and transfers them to to all other components of the application.
The task of the DispatcherServlet is send request to the specific Spring MVC controller.
Usually we have a lot of controllers and DispatcherServlet refers to one of the following components to determine the target controller:
BeanNameUrlHandlerMapping;ControllerBeanNameHandlerMapping;ControllerClassNameHandlerMapping;DefaultAnnotationHandlerMapping;SimpleUrlHandlerMapping.
If do not configure the others, the DispatcherServlet uses BeanNameUrlHandlerMapping and DefaultAnnotationHandlerMapping.
When the target controller is defined, the DispatcherServlet sends request to it. The controller performs some work according to the request (or delegate it to the other objects), and returns back to the DispatcherServlet the Model and the name of the View.
The name of the View - it is only the logical name. This logical name then used to search for the actual View (to avoid coupling with the controller and specific View). Then DispatcherServletrefers to the ViewResolver and maps the logical name of the View to the specific implementation of the View.
Implementations of the ViewResolver:
BeanNameViewResolver;ContentNegotiatingViewResolver;FreeMarkerViewResolver;InternalResourceViewResolver;JasperReportsViewResolver;ResourceBundleViewResolver;TilesViewResolver;UrlBasedViewResolver;VelocityLayoutViewResolver;VelocityViewResolver;XmlViewResolver;XsltViewResolver.
When the DispatcherServlet determines the view that will display the results (model), this view will render to the response.
Finally, the DispatcherServlet returns the Response object back to the client.
3.interceptor和filter的区别
拦截器 :是在面向切面编程的就是在你的service或者一个方法,前调用一个方法,或者在方法后调用一个方法比如动态代理就是拦截器的简单实现,在你调用方法前打印出字符串(或者做其它业务逻辑的操作),也可以在你调用方法后打印出字符串,甚至在你抛出异常的时候做业务逻辑的操作。
过滤器:是在javaweb中,你传入的request、response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者struts的action进行业务逻辑,比如过滤掉非法url(不是login.do的地址请求,如果用户没有登陆都过滤掉),或者在传入servlet或者 struts的action前统一设置字符集,或者去除掉一些非法字符.。
两者的本质区别:拦截器是基于java的反射机制的,而过滤器是基于函数回调。从灵活性上说拦截器功能更强大些,Filter能做的事情,他都能做,而且可以在请求前,请求后执行,比较灵活。Filter主要是针对URL地址做一个编码的事情、过滤掉没用的参数、安全校验(比较泛的,比如登录不登录之类),太细的话,还是建议用interceptor。不过还是根据不同情况选择合适的。| filter | Interceptor | |
| 多个的执行顺序 | 根据filter mapping配置的先后顺序 | 按照配置的顺序,但是可以通过order控制顺序 |
| 规范 | 在Servlet规范中定义的,是Servlet容器支持的 | Spring容器内的,是Spring框架支持的。 |
| 使用范围 | 只能用于Web程序中 | 既可以用于Web程序,也可以用于Application、Swing程序中。 |
| 深度 | Filter在只在Servlet前后起作用 | 拦截器能够深入到方法前后、异常抛出前后等 |
4. JVM 结构
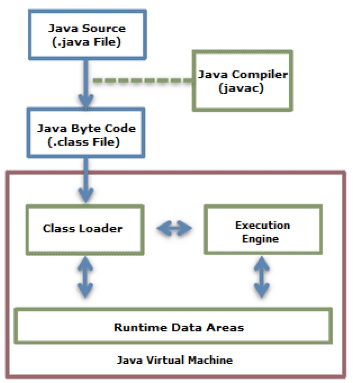
类加载器(Class Loader)
Java提供了动态的装载特性;它会在运行时的第一次引用到一个class的时候对它进行装载和链接,而不是在编译期进行。JVM的类装载器负责动态装载。Java类装载器有如下几个特点:
- 层级结构:Java里的类装载器被组织成了有父子关系的层级结构。Bootstrap类装载器是所有装载器的父亲。
- 代理模式:基于层级结构,类的装载可以在装载器之间进行代理。当装载器装载一个类时,首先会检查它是否在父装载器中进行装载了。如果上层的装载器已经装载了这个类,这个类会被直接使用。反之,类装载器会请求装载这个类。
- 可见性限制:一个子装载器可以查找父装载器中的类,但是一个父装载器不能查找子装载器里的类。
- 不允许卸载:类装载器可以装载一个类但是不可以卸载它,不过可以删除当前的类装载器,然后创建一个新的类装载器。
每个类装载器都有一个自己的命名空间用来保存已装载的类。当一个类装载器装载一个类时,它会通过保存在命名空间里的类全局限定名(Fully Qualified Class Name)进行搜索来检测这个类是否已经被加载了。如果两个类的全局限定名是一样的,但是如果命名空间不一样的话,那么它们还是不同的类。不同的命名空间表示class被不同的类装载器装载。
下图展示了类装载器的代理模型
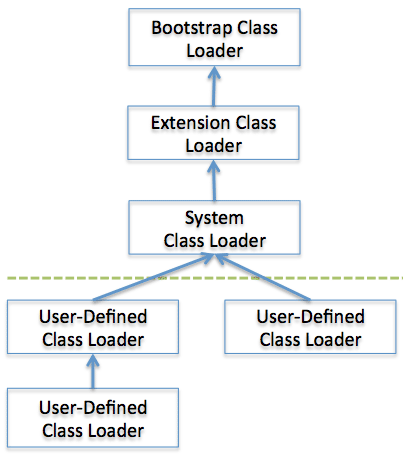
当一个类装载器(class loader)被请求装载类时,它首先按照顺序在上层装载器、父装载器以及自身的装载器的缓存里检查这个类是否已经存在。简单来说,就是在缓存里查看这个类是否已经被自己装载过了,如果没有的话,继续查找父类的缓存,直到在bootstrap类装载器里也没有找到的话,它就会自己在文件系统里去查找并且加载这个类。
- 启动类加载器(Bootstrap class loader):这个类装载器是在JVM启动的时候创建的。它负责装载Java API,包含Object对象。和其他的类装载器不同的地方在于这个装载器是通过native code来实现的,而不是用Java代码。
- 扩展类加载器(Extension class loader):它装载除了基本的Java API以外的扩展类。它也负责装载其他的安全扩展功能。
- 系统类加载器(System class loader):如果说bootstrap class loader和extension class loader负责加载的是JVM的组件,那么system class loader负责加载的是应用程序类。它负责加载用户在$CLASSPATH里指定的类。
- 用户自定义类加载器(User-defined class loader):这是应用程序开发者用直接用代码实现的类装载器。
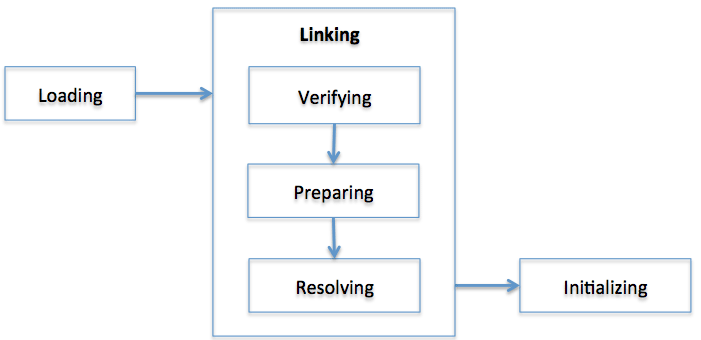
每个阶段的描述如下:
- Loading:类的信息从文件中获取并且载入到JVM的内存里。
- Verifying:检查读入的结构是否符合Java语言规范以及JVM规范的描述。这是类装载中最复杂的过程,并且花费的时间也是最长的。并且JVM TCK工具的大部分场景的用例也用来测试在装载错误的类的时候是否会出现错误。
- Preparing:分配一个结构用来存储类信息,这个结构中包含了类中定义的成员变量,方法和接口的信息。
- Resolving:把这个类的常量池中的所有的符号引用改变成直接引用。
- Initializing:把类中的变量初始化成合适的值。执行静态初始化程序,把静态变量初始化成指定的值。
JVM规范定义了上面的几个任务,不过它允许具体执行的时候能够有些灵活的变动。
运行时数据区(Runtime Data Areas)
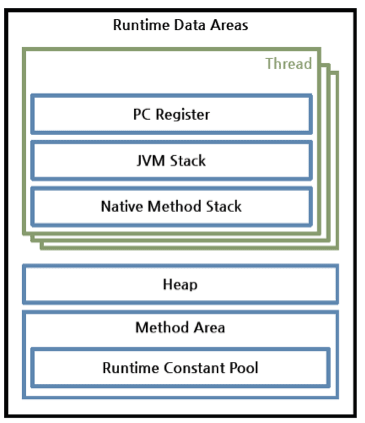
运行时数据区是在JVM运行的时候操作系统所分配的内存区。运行时内存区可以划分为6个区域。在这6个区域中,一个PC Register,JVM stack 以及Native Method Statck都是按照线程创建的,Heap,Method Area以及Runtime Constant Pool都是被所有线程公用的。
- PC寄存器(PC register):每个线程启动的时候,都会创建一个PC(Program Counter,程序计数器)寄存器。PC寄存器里保存有当前正在执行的JVM指令的地址。
- JVM 堆栈(JVM stack):每个线程启动的时候,都会创建一个JVM堆栈。它是用来保存栈帧的。JVM只会在JVM堆栈上对栈帧进行push和pop的操作。如果出现了异常,堆栈跟踪信息的每一行都代表一个栈帧立的信息,这些信息是通过类似于printStackTrace()这样的方法来展示的。
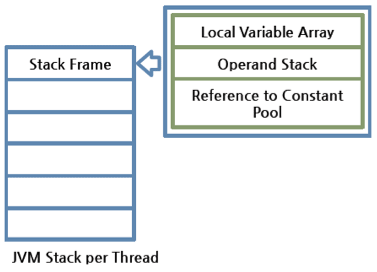
图 5: JVM堆栈
--- 栈帧(stack frame):每当一个方法在JVM上执行的时候,都会创建一个栈帧,并且会添加到当前线程的JVM堆栈上。当这个方法执行结束的时候,这个栈帧就会被移除。每个栈帧里都包含有当前正在执行的方法所属类的本地变量数组,操作数栈,以及运行时常量池的引用。本地变量数组的和操作数栈的大小都是在编译时确定的。因此,一个方法的栈帧的大小也是固定不变的。
--- 局部变量数组(Local variable array):这个数组的索引从0开始。索引为0的变量表示这个方法所属的类的实例。从1开始,首先存放的是传给该方法的参数,在参数后面保存的是方法的局部变量。
--- 操作数栈(Operand stack):方法实际运行的工作空间。每个方法都在操作数栈和局部变量数组之间交换数据,并且压入或者弹出其他方法返回的结果。操作数栈所需的最大空间是在编译期确定的。因此,操作数栈的大小也可以在编译期间确定。
- 本地方法栈(Native method stack):供用非Java语言实现的本地方法的堆栈。换句话说,它是用来调用通过JNI(Java Native Interface Java本地接口)调用的C/C++代码。根据具体的语言,一个C堆栈或者C++堆栈会被创建。
- 方法区(Method area):方法区是所有线程共享的,它是在JVM启动的时候创建的。它保存所有被JVM加载的类和接口的运行时常量池,成员变量以及方法的信息,静态变量以及方法的字节码。JVM的提供者可以通过不同的方式来实现方法区。在Oracle 的HotSpot JVM里,方法区被称为永久区或者永久代(PermGen)。是否对方法区进行垃圾回收对JVM的实现是可选的。
- 运行时常量池(Runtime constant pool):这个区域和class文件里的constant_pool是相对应的。这个区域是包含在方法区里的,不过,对于JVM的操作而言,它是一个核心的角色。因此在JVM规范里特别提到了它的重要性。除了包含每个类和接口的常量,它也包含了所有方法和变量的引用。简而言之,当一个方法或者变量被引用时,JVM通过运行时常量区来查找方法或者变量在内存里的实际地址。
- 堆(Heap):用来保存实例或者对象的空间,而且它是垃圾回收的主要目标。当讨论类似于JVM性能之类的问题时,它经常会被提及。JVM提供者可以决定怎么来配置堆空间,以及不对它进行垃圾回收。
执行引擎(Execution Engine)
通过类装载器装载的,被分配到JVM的运行时数据区的字节码会被执行引擎执行。执行引擎以指令为单位读取Java字节码。它就像一个CPU一样,一条一条地执行机器指令。每个字节码指令都由一个1字节的操作码和附加的操作数组成。执行引擎取得一个操作码,然后根据操作数来执行任务,完成后就继续执行下一条操作码。
不过Java字节码是用一种人类可以读懂的语言编写的,而不是用机器可以直接执行的语言。因此,执行引擎必须把字节码转换成可以直接被JVM执行的语言。字节码可以通过以下两种方式转换成合适的语言。
- 解释器:一条一条地读取,解释并且执行字节码指令。因为它一条一条地解释和执行指令,所以它可以很快地解释字节码,但是执行起来会比较慢。这是解释执行的语言的一个缺点。字节码这种“语言”基本来说是解释执行的。
- 即时(Just-In-Time)编译器:即时编译器被引入用来弥补解释器的缺点。执行引擎首先按照解释执行的方式来执行,然后在合适的时候,即时编译器把整段字节码编译成本地代码。然后,执行引擎就没有必要再去解释执行方法了,它可以直接通过本地代码去执行它。执行本地代码比一条一条进行解释执行的速度快很多。编译后的代码可以执行的很快,因为本地代码是保存在缓存里的。
不过,用JIT编译器来编译代码所花的时间要比用解释器去一条条解释执行花的时间要多。因此,如果代码只被执行一次的话,那么最好还是解释执行而不是编译后再执行。因此,内置了JIT编译器的JVM都会检查方法的执行频率,如果一个方法的执行频率超过一个特定的值的话,那么这个方法就会被编译成本地代码。
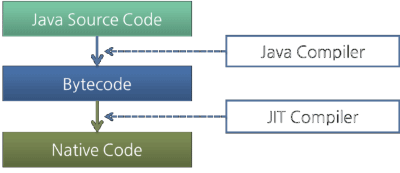
图 7:Java编译器和JIT编译器
JVM规范没有定义执行引擎该如何去执行。因此,JVM的提供者通过使用不同的技术以及不同类型的JIT编译器来提高执行引擎的效率。
大部分的JIT编译器都是按照下图的方式来执行的:
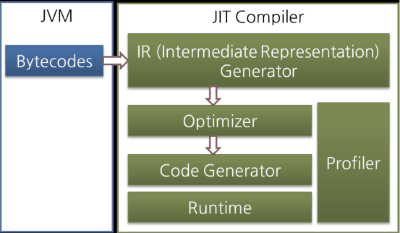
图 8: JIT编译器
JIT编译器把字节码转换成一个中间层表达式,一种中间层的表示方式,来进行优化,然后再把这种表示转换成本地代码。
Oracle Hotspot VM使用一种叫做热点编译器的JIT编译器。它之所以被称作”热点“是因为热点编译器通过分析找到最需要编译的“热点”代码,然后把热点代码编译成本地代码。如果已经被编译成本地代码的字节码不再被频繁调用了,换句话说,这个方法不再是热点了,那么Hotspot VM会把编译过的本地代码从cache里移除,并且重新按照解释的方式来执行它。Hotspot VM分为Server VM和Client VM两种,这两种VM使用不同的JIT编译器。
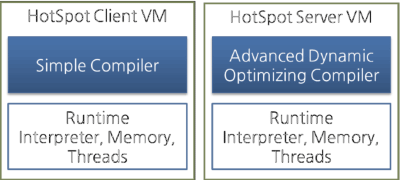
Figure 9: Hotspot Client VM and Server VM
Client VM 和Server VM使用完全相同的运行时,不过如上图所示,它们所使用的JIT编译器是不同的。Server VM用的是更高级的动态优化编译器,这个编译器使用了更加复杂并且更多种类的性能优化技术。
IBM 在IBM JDK 6里不仅引入了JIT编译器,它同时还引入了AOT(Ahead-Of-Time)编译器。它使得多个JVM可以通过共享缓存来共享编译过的本地代码。简而言之,通过AOT编译器编译过的代码可以直接被其他JVM使用。除此之外,IBM JVM通过使用AOT编译器来提前把代码编译器成JXE(Java EXecutable)文件格式来提供一种更加快速的执行方式。
大部分Java程序的性能都是通过提升执行引擎的性能来达到的。正如JIT编译器一样,很多优化的技术都被引入进来使得JVM的性能一直能够得到提升。最原始的JVM和最新的JVM最大的差别之处就是在于执行引擎。
Hotspot编译器在1.3版本的时候就被引入到Oracle Hotspot VM里了,JIT编译技术在Anroid 2.2版本的时候被引入到Dalvik VM里。
注意:
引入一种中间语言,例如字节码,虚拟机执行字节码,并且通过JIT编译器来提升JVM的性能的这种技术以及广泛应用在使用中间语言的编程语言上。例如微软的.Net,CLR(Common Language Runtime 公共语言运行时),也是一种VM,它执行一种被称作CIL(Common Intermediate Language)的字节码。CLR提供了AOT编译器和JIT编译器。因此,用C#或者VB.NET编写的源代码被编译后,编译器会生成CIL并且CIL会执行在有JIT编译器的CLR上。CLR和JVM相似,它也有垃圾回收机制,并且也是基于堆栈运行。
5. 堆和栈的区别
当在一段代码块定义一个变量时,Java就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java会自动释放掉为该变量所分配的内存空间,该内存空间可以立即被另作他用。
堆内存用来存放由new创建的对象和数组。
在堆中分配的内存,由Java虚拟机的自动垃圾回收器来管理。
在堆中产生了一个数组或对象后,还可以在栈中定义一个特殊的变量,让栈中这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量。
引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
java中变量在内存中的分配
1、类变量(static修饰的变量):在程序加载时系统就为它在堆中开辟了内存,堆中的内存地址存放于栈以便于高速访问。静态变量的生命周期--一直持续到整个"系统"关闭
2、实例变量:当你使用java关键字new的时候,系统在堆中开辟并不一定是连续的空间分配给变量(比如说类实例),然后根据零散的堆内存地址,通过哈希算法换算为一长串数字以表征这个变量在堆中的"物理位置"。 实例变量的生命周期--当实例变量的引用丢失后,将被GC(垃圾回收器)列入可回收“名单”中,但并不是马上就释放堆中内存
3、局部变量:局部变量,由声明在某方法,或某代码段里(比如for循环),执行到它的时候在栈中开辟内存,当局部变量一但脱离作用域,内存立即释放
附:java的内存机制
Java 把内存划分成两种:一种是栈内存,另一种是堆内存。
在函数中定义的一些基本类型的变量和对象的引用变量都是在函数的栈内存中分配,当在一段代码块定义一个变量时,Java 就在栈中为这个变量分配内存空间,当超过变量的作用域后,Java 会自动释放掉为该变量分配的内存空间,该内存空间可以立即被另作它用。
堆内存用来存放由 new 创建的对象和数组,在堆中分配的内存,由 Java 虚拟机的自动垃圾回收器来管理。在堆中产生了一个数组或者对象之后,还可以在栈中定义一个特殊的变量,让栈中的这个变量的取值等于数组或对象在堆内存中的首地址,栈中的这个变量就成了数组或对象的引用变量,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或者对象,引用变量就相当于是为数组或者对象起的一个名称。引用变量是普通的变量,定义时在栈中分配,引用变量在程序运行到其作用域之外后被释放。而数组和对象本身在堆中分配,即使程序运行到使用 new 产生数组或者对象的语句所在的代码块之外,数组和对象本身占据的内存不会被释放,数组和对象在没有引用变量指向它的时候,才变为垃圾,不能在被使用,但仍然占据内存空间不放,在随后的一个不确定的时间被垃圾回收器收走(释放掉)。
这也是 Java 比较占内存的原因,实际上,栈中的变量指向堆内存中的变量,这就是 Java 中的指针!
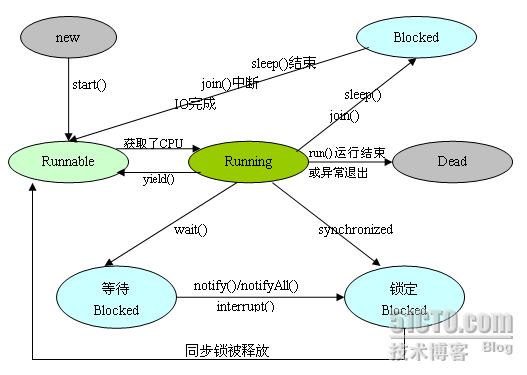
6. 线程状态
2. 就绪状态(Runnable):线程对象创建后,其他线程调用了该对象的start()方法。该状态的线程位于可运行线程池中,变得可运行,等待获取CPU的使用权。
3. 运行状态(Running):就绪状态的线程获取了CPU,执行程序代码。
4. 阻塞状态(Blocked):阻塞状态是线程因为某种原因放弃CPU使用权,暂时停止运行。直到线程进入就绪状态,才有机会转到运行状态。阻塞的情况分三种:
(一)、等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。
(二)、同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
(三)、其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
5. 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
7. 如何读取设备数据
8. close wait 是什么问题
利用nginx来学习
[plcm@rpumdev233 deployment]$ netstat -n | awk '/^tcp/ {++S[$1]} END {for(a in S) print a,S[a]} '
tcp 132
[plcm@rpumdev233 deployment]$ netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a,S[a]} '
CLOSE_WAIT 4
ESTABLISHED 128
/^tcp/
滤出tcp开头的记录,屏蔽udp, socket等无关记录。
state[]
相当于定义了一个名叫state的数组
NF
表示记录的字段数,如上所示的记录,NF等于6
$NF
表示某个字段的值,如上所示的记录,$NF也就是$6,表示第6个字段的值,也就是TIME_WAIT
state[$NF]
表示数组元素的值,如上所示的记录,就是state[TIME_WAIT]状态的连接数
++state[$NF]
表示把某个数加一,如上所示的记录,就是把state[TIME_WAIT]状态的连接数加一
END
表示在最后阶段要执行的命令
for(key in state)
遍历数组
print key,”\t”,state[key]
打印数组的键和值,中间用\t制表符分割,美化一下。

各个状态的意义如下:
LISTEN - 侦听来自远方TCP端口的连接请求;
SYN-SENT -在发送连接请求后等待匹配的连接请求;
SYN-RECEIVED - 在收到和发送一个连接请求后等待对连接请求的确认;
ESTABLISHED- 代表一个打开的连接,数据可以传送给用户;
FIN-WAIT-1 - 等待远程TCP的连接中断请求,或先前的连接中断请求的确认;
FIN-WAIT-2 - 从远程TCP等待连接中断请求;
CLOSE-WAIT - 等待从本地用户发来的连接中断请求;
CLOSING -等待远程TCP对连接中断的确认;
LAST-ACK - 等待原来发向远程TCP的连接中断请求的确认;
TIME-WAIT -等待足够的时间以确保远程TCP接收到连接中断请求的确认;
CLOSED - 没有任何连接状态;

http://j2eedebug.blogspot.com/2008/12/difference-between-closewait-and.html
http://oliver258.blog.51cto.com/750330/1306861
CLOSE_WAIT产生的原因是客户端主动关闭,收到FIN包,应用层却没有做出关闭操作引起的。
CLOSE_WAIT在Nginx上面的产生原因还是因为Nagle's算法加Nginx本身EPOLL的ET触发模式导致。
ET出发模式在数据就绪的时候会触发一次回调操作,Nagle's算法会累积TCP包,如果最后的数据包和
FIN包被Nagle's算法合并,会导致EPOLL的ET模式只出发一次,然而在应用层的SOCKET是读取返回
0才代表链接关闭,而读取这次合并的数据包时是不返回0的,然后SOCKET以后都不会触发事件,所以
导致应用层没有关闭SOCKET,从而产生大量的CLOSE_WAIT状态链接。
关闭TCP_NODELAY,在Nginx配置中加上
tcp_nodelay on;
利用nginx -V 查看nginx基本信息
[plcm@rpumdev233 deployment]$ nginx -V
nginx version: nginx/1.9.9 (nginx-plus-r8-p3)
built by gcc 4.4.7 20120313 (Red Hat 4.4.7-16) (GCC)
built with OpenSSL 1.0.1e-fips 11 Feb 2013
TLS SNI support enabled
configure arguments: --build=nginx-plus-r8-p3 --prefix=/etc/nginx/ --sbin-path=/usr/sbin/nginx --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_addition_module --with-http_sub_module --with-http_dav_module --with-http_flv_module --with-http_mp4_module --with-http_gzip_static_module --with-http_gunzip_module --with-http_random_index_module --with-http_secure_link_module --with-http_stub_status_module --with-http_auth_request_module --with-http_slice_module --with-mail --with-mail_ssl_module --with-threads --with-file-aio --with-ipv6 --with-stream --with-stream_ssl_module --with-http_f4f_module --with-http_session_log_module --with-http_hls_module --with-cc-opt='-O2 -g -pipe -Wall -Wp,-D_FORTIFY_SOURCE=2 -fexceptions -fstack-protector --param=ssp-buffer-size=4 -m64 -mtune=generi大量time_wait的解决方法
就会进入 TIME_WAIT 状态 停留2MSL(max segment lifetime)时间
这个是TCP/IP必不可少的,也就是“解决”不了的。
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
TIME_WAIT 8535 CLOSE_WAIT 5 FIN_WAIT2 20 ESTABLISHED 248 LAST_ACK 14
解决办法 修改内核参数
vi /etc/sysctl.conf net.ipv4.tcp_syncookies = 1 net.ipv4.tcp_tw_reuse=1 #让TIME_WAIT状态可以重用,这样即使TIME_WAIT占满了所有端口,也不会拒绝新的请求造成障碍 默认是0 net.ipv4.tcp_tw_recycle=1 #让TIME_WAIT尽快回收 默认0 net.ipv4.tcp_fin_timeout=30 /sbin/sysctl -p 让修改生效
在查看,已经恢复正常
TIME_WAIT 69 CLOSE_WAIT 4 FIN_WAIT2 15 ESTABLISHED 236 LAST_ACK 1然后执行 /sbin/sysctl -p 让参数生效
close_wait解决方法
基本的思想就是要检测出对方已经关闭的socket,然后关闭它。
1.代码需要判断socket,一旦read返回0,断开连接,read返回负,检查一下errno,如果不是AGAIN,也断开连接。(注:在UNP 7.5节的图7.6中,可以看到使用select能够检测出对方发送了FIN,再根据这条规则就可以处理CLOSE_WAIT的连接)
2.给每一个socket设置一个时间戳last_update,每接收或者是发送成功数据,就用当前时间更新这个时间戳。定期检查所有的时间戳,如果时间戳与当前时间差值超过一定的阈值,就关闭这个socket。
3.使用一个Heart-Beat线程,定期向socket发送指定格式的心跳数据包,如果接收到对方的RST报文,说明对方已经关闭了socket,那么我们也关闭这个socket。
4.设置SO_KEEPALIVE选项,并修改内核参数
前提是启用socket的KEEPALIVE机制:
//启用socket连接的KEEPALIVE
int iKeepAlive = 1;
setsockopt(s, SOL_SOCKET, SO_KEEPALIVE, (void *)&iKeepAlive, sizeof(iKeepAlive));
tcp_keepalive_intvl (integer; default: 75; since Linux 2.4)
The number of seconds between TCP keep-alive probes.
tcp_keepalive_probes (integer; default: 9; since Linux 2.2)
The maximum number of TCP keep-alive probes to send before giving up and killing the connection if no response is obtained from the other end.
tcp_keepalive_time (integer; default: 7200; since Linux 2.2)
The number of seconds a connection needs to be idle before TCP begins sending out keep-alive probes. Keep-alives are only sent when the SO_KEEPALIVE socket option is enabled. The default value is 7200 seconds (2 hours). An idle connec‐tion is terminated after approximately an additional 11 minutes (9 probes an interval of 75 seconds apart) when keep-alive is enabled.
echo 120 > /proc/sys/net/ipv4/tcp_keepalive_time
echo 2 > /proc/sys/net/ipv4/tcp_keepalive_intvl
echo 1 > /proc/sys/net/ipv4/tcp_keepalive_probes
除了修改内核参数外,可以使用setsockopt修改socket参数,参考man 7 socket。
int KeepAliveProbes=1;
int KeepAliveIntvl=2;
int KeepAliveTime=120;
setsockopt(s, IPPROTO_TCP, TCP_KEEPCNT, (void *)&KeepAliveProbes, sizeof(KeepAliveProbes));
setsockopt(s, IPPROTO_TCP, TCP_KEEPIDLE, (void *)&KeepAliveTime, sizeof(KeepAliveTime));
setsockopt(s, IPPROTO_TCP, TCP_KEEPINTVL, (void *)&KeepAliveIntvl, sizeof(KeepAliveIntvl));















 587
587

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









