






ArcPy 学习 创建栅格金字塔
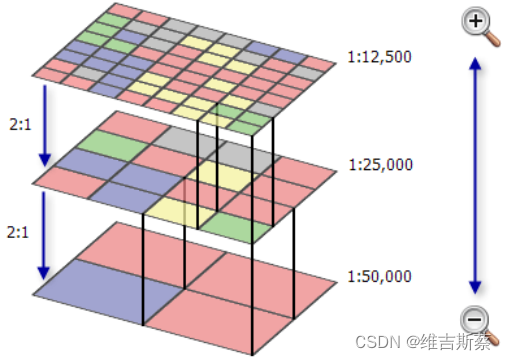
在加载数据量比较大的栅格影像时,通常构建栅格金字塔可以实现快速加载;下面就是ArcPy中构建金字塔的核心代码
arcpy.management.BuildPyramidsandStatistics(in_workspace, {include_subdirectories}, {build_pyramids}, {calculate_statistics}, {BUILD_ON_SOURCE}, {block_field}, {estimate_statistics}, {x_skip_factor}, {y_skip_factor}, {ignore_values}, {pyramid_level}, {SKIP_FIRST}, {resample_technique}, {compression_type}, {compression_quality}, {skip_existing}, {where_clause})
- in_workspace:输入的工作空间,包含所有要处理的栅格数据集或镶嵌数据集。这是一个必需的参数,您需要指定您的数据所在的文件夹或数据库。
- include_subdirectories:是否包含子目录。如果您的数据分布在多个子目录中,您可以选择 INCLUDE_SUBDIRECTORIES,这样工具会遍历所有的子目录中的栅格数据集和镶嵌数据集。如果您的数据都在同一个目录中,您可以选择 NONE,这样工具只会处理当前目录中的栅格数据集和镶嵌数据集。
- build_pyramids:是否构建金字塔。如果您想要提高栅格数据集的显示性能和显示质量,您可以选择 BUILD_PYRAMIDS,这样工具会为每个栅格数据集构建金字塔。如果您不需要构建金字塔,您可以选择 NONE,这样工具只会计算统计数据。
- calculate_statistics:是否计算统计数据。如果您想要让 ArcGIS 应用程序正确地拉伸和符号化栅格数据进行显示,您可以选择 CALCULATE_STATISTICS,这样工具会为每个栅格数据集计算统计数据。如果您不需要计算统计数据,您可以选择 NONE,这样工具只会构建金字塔。
- skip_existing:(可选)是否跳过已经存在的金字塔。OVERWRITE 表示覆盖已有的金字塔,这是默认值。SKIP_EXISTING 表示跳过已有的金字塔。Boolean
示例
遍历文件夹中的所有栅格文件构建金字塔
# 导入 arcpy 模块
import arcpy
# 设置工作空间
arcpy.env.workspace = r"G:\Tiff"
# 遍历工作空间中的所有栅格数据集和镶嵌数据集
rasters = arcpy.ListRasters("*", "ALL")
for raster in rasters:
print(raster)
# 为每个栅格数据集构建金字塔和统计数据
arcpy.BuildPyramidsandStatistics_management(raster, "NONE", "BUILD_PYRAMIDS", "CALCULATE_STATISTICS")
# 打印文件名
print('finish')
指定路径构建金字塔
rasterList = [r"E:\H1-H17\2\map2\result.tif",
r"E:\H1-H17\3\map3\result.tif",
r"E:\H1-H17\4\map4\result.tif",
]
import arcpy
for in_raster in rasterList:
print(in_raster)
arcpy.BuildPyramidsandStatistics_management(in_raster, "NONE", "BUILD_PYRAMIDS", "CALCULATE_STATISTICS")
print('finish')
参考
ArcGIS Desktop构建金字塔和统计数据
ArcGIS Pro 3.2 Build Pyramids (Data Management)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











