







kmp算法是用于解析字符串匹配的问题。给定两个字符串:第一个是文本串str,第二个是匹配串p。问str中最早有那个位置能完全和匹配串p匹配呢?
1. 暴力匹配
假设文本串的长度为n,匹配串的长度为m. 那么显然有一种暴力解法是:
int match(string str, string p){
int i = 0;
int j = 0;
while (i < str.size() && j < p.size())
{
if (str[i] == p[j]){
i++;
j++;
}
else{
i = i - (j - 1);
j = 0;
}
}
if (j == p.size()){
return i - j;
}
else{
return -1;
}
}显然它的复杂度是O(m*n)。因为对于失配的情况,j每次都要退回到0位置,i也要退回到之前匹配成功的下一个字符。然后重新进行匹配。显然在进行每个字符的匹配的时候,str和p的每个字符的信息是经过记录的,而这个信息在暴力匹配的时候是没有用到的。那么有没有一种办法能用到这个信息,让str只进行one loop一次循环呢?答案就是kmp算法。
2. kmp概述
我们举个例子来解析一下kmp算法的优势:
比如str = AABBAACAABBAAC 而匹配字符串是p=AABBAAB. 当我们分别对两个字符串的头进行匹配,一直进行下去知道str[6] == 'C' p[6] == 'B'. 这个时候发现失配了。从传统的暴力法来说,那么应该让p的头字符A重新和str的第二个字符A进行匹配。但是,我们发现匹配串AABBAAB上面是有规律的。最后一个B前面的AABBAA是一个“对称串”,对于这个B之前的字符串,它的前两个字符AA和后两个字符AA是一样的。而这个时候str和p之前已经匹配的部分(AABBAA)对于AA已经是匹配好的,所以p不需要直接移动到位置0重新匹配,对于串p, 直接左移两位,让str 的AABBAAC 和p的AABBAAB匹配,再进行下面的步骤就行。
也就是说,重点回到了寻找匹配串p中前缀后缀最长公共长度。假设p有一个对应的这个长度数组next[], p[j]字符对应的长度是next[j],表示j位置之前的前缀后缀最长公共长度是next[j]. 有了这个长度,当发生失配的时候,p匹配串只需要右移动j-next[j]就可以,而不是简单的j回到0(也就是右移j).
3. next数组
比如说字符串p= abab 那么它对应的最长前缀后缀公共串长度就是[0, 0, 1, 2](这是包含了本字符)。求next数组的时候,因为是不包含的,所以需要各个位置在之前的基础上左移一位,然后0位置赋值为-1.所以next数组是[-1, 0, 0 1]
那么怎么根绝next数组进行匹配呢?
当匹配失配的时候,令j = next [j],模式串向右移动的位数为:j - next[j]。换言之,当模式串的后缀pj-k pj-k+1, ..., pj-1 跟文本串si-k si-k+1, ..., si-1匹配成功,但pj 跟si匹配失败时,因为next[j] = k,相当于在不包含pj的模式串中有最大长度为k 的相同前缀后缀,即p0 p1 ...pk-1 = pj-k pj-k+1...pj-1,故令j = next[j],从而让模式串右移j - next[j] 位,使得模式串的前缀p0 p1, ..., pk-1对应着文本串 si-k si-k+1, ..., si-1,而后让pk 跟si 继续匹配。
如下图:
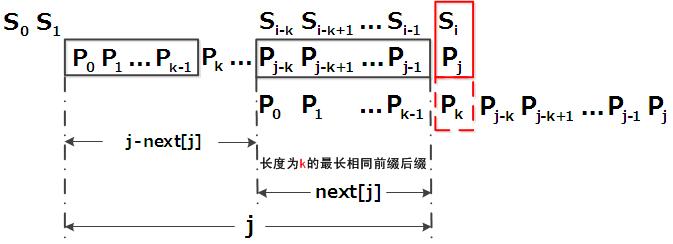
那么问题就来了,如何求next呢?求next数组需要递推,也就是说对于值k,已有p0 p1, ..., pk-1 = pj-k pj-k+1, ..., pj-1,相当于next[j] = k,那么怎么求next[j+1]呢?
4. next数组求法
算法如下:
1. 如果当 p[k] == p[j]时候,则next[j + 1 ] = next [j] + 1 = k + 1
2. 如果 p[k ] != p[j],如果此时p[ next[k] ] == p[j ],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。
上面的1很好理解。
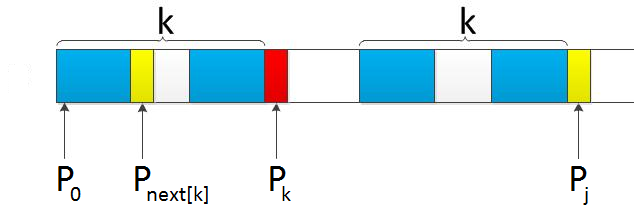
当p[j] == p[k]的时候,因为p[j]前面的k个字符是前缀后缀都相同的(上图大括号下面的两个k长度的部分),那么如果p[j]==p[k]则在原来的基础上左右分别添上了一个pk和pj。对于p[j+1]向左看去,相当于左边有k+1和前缀后缀相等的部分。
最难理解的是p[j] != p[k]的时候。因为当p[j] != p[k]的时候,p0~pk和pj-k ~pk组成的两个字符串是不同的。那么我们需要找一个尽可能长的m,使得p0~pm ==pj-m~pj。我们看上图的左半部分:当pk~=pj的时候,对于这个k,它的next[k]表示第k个字符左边前缀后缀相等的部分(左半部分黄色左边的蓝色)。而这一部分,因为之前说了两个大括号下面的k个都是对称的,那么在右半部分的右边的蓝色一定也是存在一个和P0~Pnext[k]相同的部分。如果再加上pnext[k]和p[j]匹配,那么就说明又找到最长的;否则k=next[k]接着递归寻找。
所以求next数组的步骤如下:
void getNext(string str, vector<int> &next){
next.push_back(-1);
int k = -1;
for (int j = 1; j < str.size(); j++){
while (k != -1 && str[j - 1] != str[k])
{
k = next[k];
}
k++;
next.push_back(k);
}
}5. 根据next数组写出kmp算法
已知了next数组,kmp算法如下:
如果文本串str匹配到 i 位置,模式串p匹配到 j 位置
当j = -1,或者当前字符匹配成功(str[i] == p[j]),那么i++,j++,也就是可以匹配下一个字符;
当j != -1,且当前字符匹配失败(str[i] != p[j]),那么i 不变,j = next[j]。也就是当失配时,匹配串p相对于文本串str向右移动了j - next [j] 位。
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数为:j - next[j],且此值大于等于1。
代码如下:
int kmp(string str, string p, vector<int> &next){
//str1是待匹配文本串,p是匹配字符串,next是匹配串p对应的next数组
//i j分别表示匹配到str1和p的i,j位
int i = 0;
int j = 0;
while (i < str.size() && j < (int)p.size())
{
if (j == -1 || str[i] == p[j]){
i++;
j++;
}
else{
j = next[j];
}
}
if (j == p.size()) return i - j;
else return -1;//-1表示无匹配
}6. kmp算法复杂度分析:
首先我们先看计算next数组的复杂度:O(m)
再看kmp算法:我们发现如果某个字符匹配成功,模式串首字符的位置保持不动,仅仅是i++、j++;如果匹配失配,i 不变(即 i 不回溯),模式串会跳过匹配过的next [j]个字符。整个算法最坏的情况是,当模式串首字符位于i - j的位置时才匹配成功,算法结束。
所以,如果文本串的长度为n,模式串的长度为m,那么匹配过程的时间复杂度为O(n),算上计算next的O(m)时间,KMP的整体时间复杂度为O(m + n)。















 7580
7580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









