







开发环境:
CDP 7.1.4
Hive 3.1.3
1. 执行流程
Hive未经优化的分组聚合,只通过一个MapReduce Job实现的。Map端负责读取数据,并按照分组字段分区,通过Shuffle,将具有相同分组字段值的数据发送到同一个Reduce端,各组数据在Reduce端完成最终的聚合运算。
2. 优化思路
分组聚合的优化思路主要围绕减少Shuffle数据量进行,具体做法采用Map-Side聚合。
Map-Side聚合是在Map端维护一个哈希表(也叫散列表,英文:Hash Table,是根据关键码值(key-value)而直接进行访问的数据结构),利用哈希表完成部分的聚合,然后将部分聚合的结果,按照分组字段分区,通过Shuffle,将具有相同分组字段值的数据发送到同一个Reduce端,各组数据在Reduce端完成最终的聚合运算。
Map-Side聚合的相关参数如下:
-- 启动Map-Side聚合
set hive.map.aggr = true;
-- 检测源表数据是否适合启动Map-Side聚合
-- 检测方法:先对若干条数据进行Map-Side聚合,若聚合后的数据条数与聚合之前的数据条数比值小于该值,则认为该表适合进行Map-Side聚合;否则,认为该表不适合进行Map-Side聚合,后续也就不再进行Map-Side聚合
set hive.map.aggr.hash.min.reduction = 0.5;
-- 用于检测源表是否适合进行Map-Side聚合的数据条数
set hive.groupby.mapaggr.checkinterval = 100000;
-- Map-Side聚合所用的Hash Table占用Map Task堆内存的最大比例,若超出该值,则会对Hash Table进行一次Flush
set hive.map.aggr.hash.force.flush.memory.threshold = 0.9;
3. 优化案例
3.1. 未经优化的执行
set hive.map.aggr = false;
EXPLAIN
SELECT app,
count(1)
FROM tmp.op_user_device_day
WHERE dt = '20230131'
GROUP BY app;
执行计划如下:

3.2. 优化后的执行
set hive.map.aggr = true;
EXPLAIN
SELECT app,
count(1)
FROM tmp.op_user_device_day
WHERE dt = '20230131'
GROUP BY app;
执行计划如下:
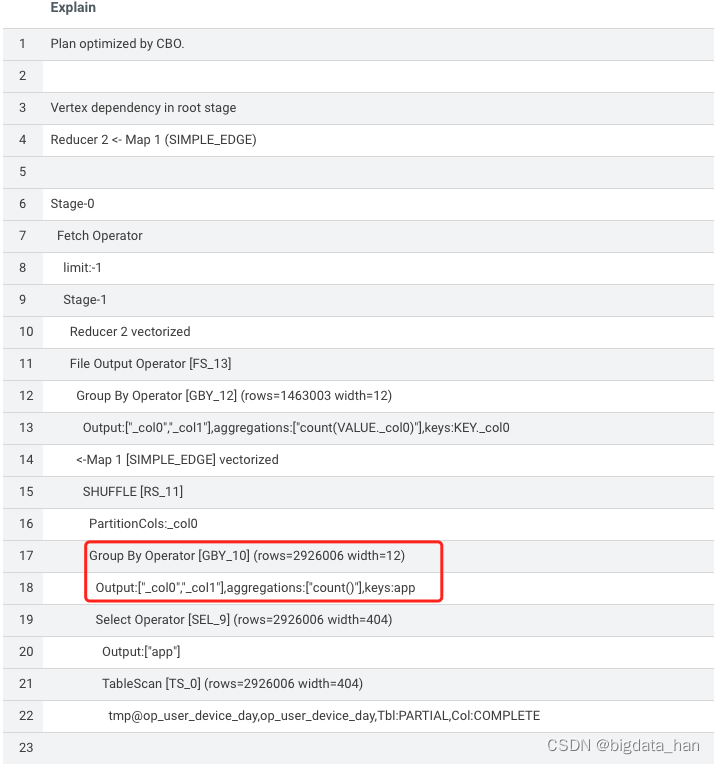
优化后的执行计划比优化前的执行计划多了一个Map端Group By Operator操作,也就是Map端部分聚合操作。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











