







“瑞数” 是逆向路上的一座大山,是许多JS逆向者绕不开的一堵围墙,也是跳槽简历上的一个亮点,我们必须得在下次跳槽前攻克它!! 好在现在网上有很多讲解瑞数相关的文章,贴心的一步一步教我们去分析瑞数流程,分析如何去扣瑞数逻辑,企图以此教会我们 (手动狗头)。却鲜有文章详细去讲解如何通过纯补环境的方式过瑞数。今天,它来了!
为了让大家彻底搞定瑞数这个老大哥,本文将从以下四个部分进行描述:
1-rs的流程逻辑
2-浅谈扣代码过rs
3-详解补环境过rs
4-扣代码与补环境对比
5-弯道超车环节
篇幅较长,坐稳发车咯!
注:本文内容均以一个新人友好型 rs4网站: 网上房地产,为例;
一:rs的流程逻辑
我们在做逆向的时候,首先得分析出哪些加密参数是需要逆向的,然后再是去逆向这些参数。当然瑞数也是一样。
所以我们第一步就是明确逆向的目标:
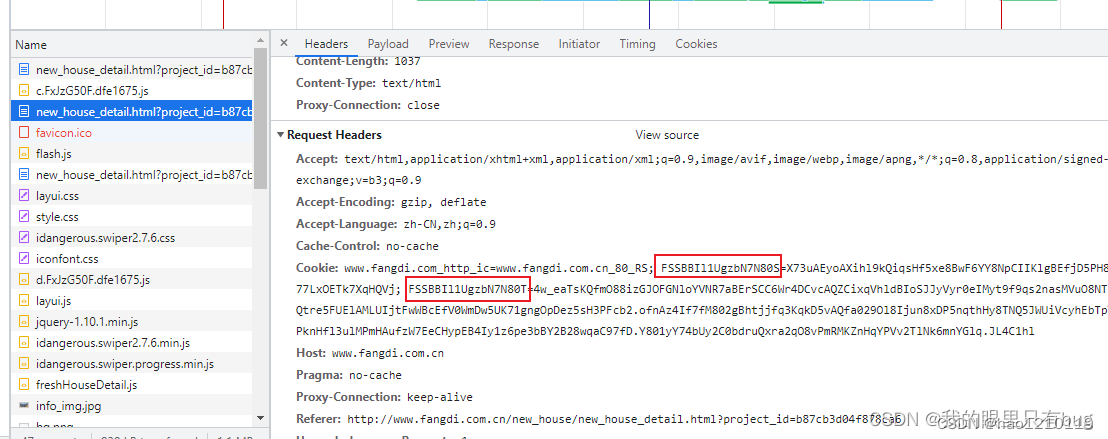
–现象:上了rs的网站会请求两次page_url,第二次请求page_url时才能得到正确的页面内容;
–分析:分析其请求体,发现第二次请求page_url时带上了cookie_s和cookie_t, 而cookies_s是来自第一次请求page_url时其响应头set的;
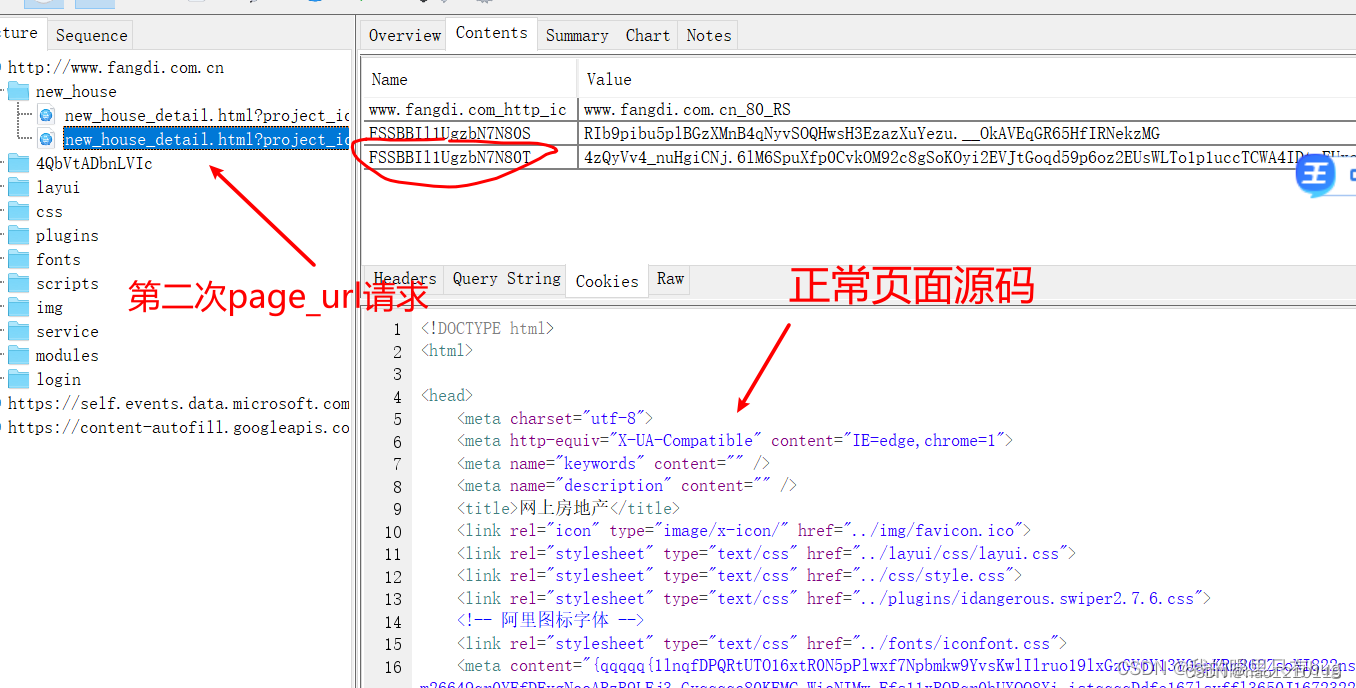
结论:那么我们的目标就确定了 – 破解cookie_t的生成逻辑;
现在,我们知道了需要逆向的加密参数是cookie_t,那么cookie_t是从何而来呢,我们先分析一下网站的请求
瑞数网站请求流程分析:
第一次请求:
请求page_url,响应状态码202,响应头中 set了 cookie_s;
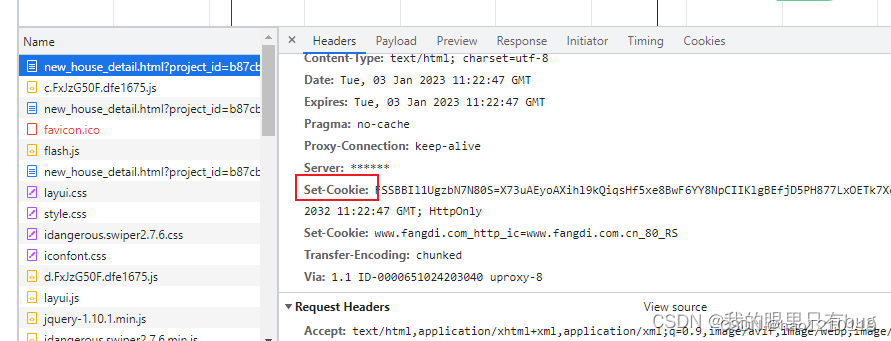
响应体是HTML源码,从上到下可以分为四部分:我先剧透一下它们的作用
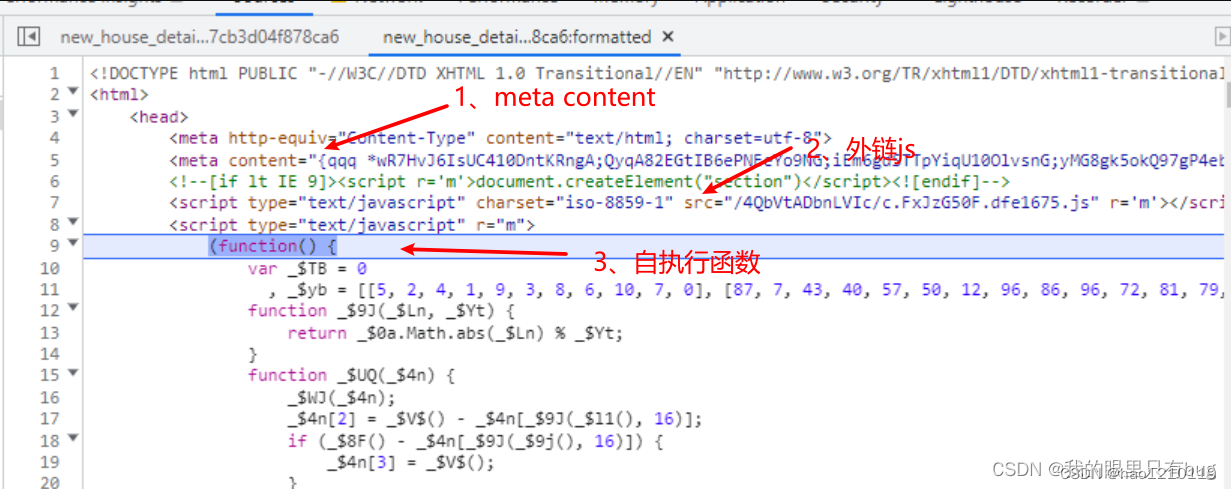
1.一个meta标签,其content内容很长且是动态的(每次请求会变化),会在eval执行第二层JS代码时使用到;
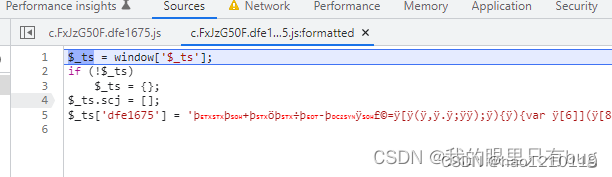
2.一个外链js文件,一般同一页面中其内容是固定的,下面的自执行函数会解密文件内容生成eval执行时需要的JS源码,也就是第二层vm代码;
3.一个大自执行函数(每次请求首页都会动态变化),主要是解密外链JS内容,给window添加一些属性如$_ts,会在vm中使用;
4.末尾的两个script标签中的函数调用,会更新cookie,使其变长。这里我们可以不用关注这个。
第二次请求: 请求外链js,一般内容是固定的;
第三次请求: 请求page_url,返回200,携带cookie_s,cookie_T即可正常请求;
那么当我们在浏览器中访问该网站时到底发生了什么?其中有什么值得我们关注的?
我们先人工模拟一下浏览器加载page_url源码会发生什么:
1.浏览器加载meta ;
2.浏览器请求外链js并执行js内容;
3.执行page_url源码自执行函数,它内部会将外链js解密成eval需要的万行js字符串,并给window.$_ts添加了很多属性,然后调用eval函数进入VM执行解密后的js,生成cookie,eval执行完毕,继续执行自执行函数;
4.执行末尾script标签中的代码,这些代码会更新cookie_t(可以不用管)
5.执行setTimeout、eventlistener回调函数(可以不用管)
瑞数执行流程图解如下
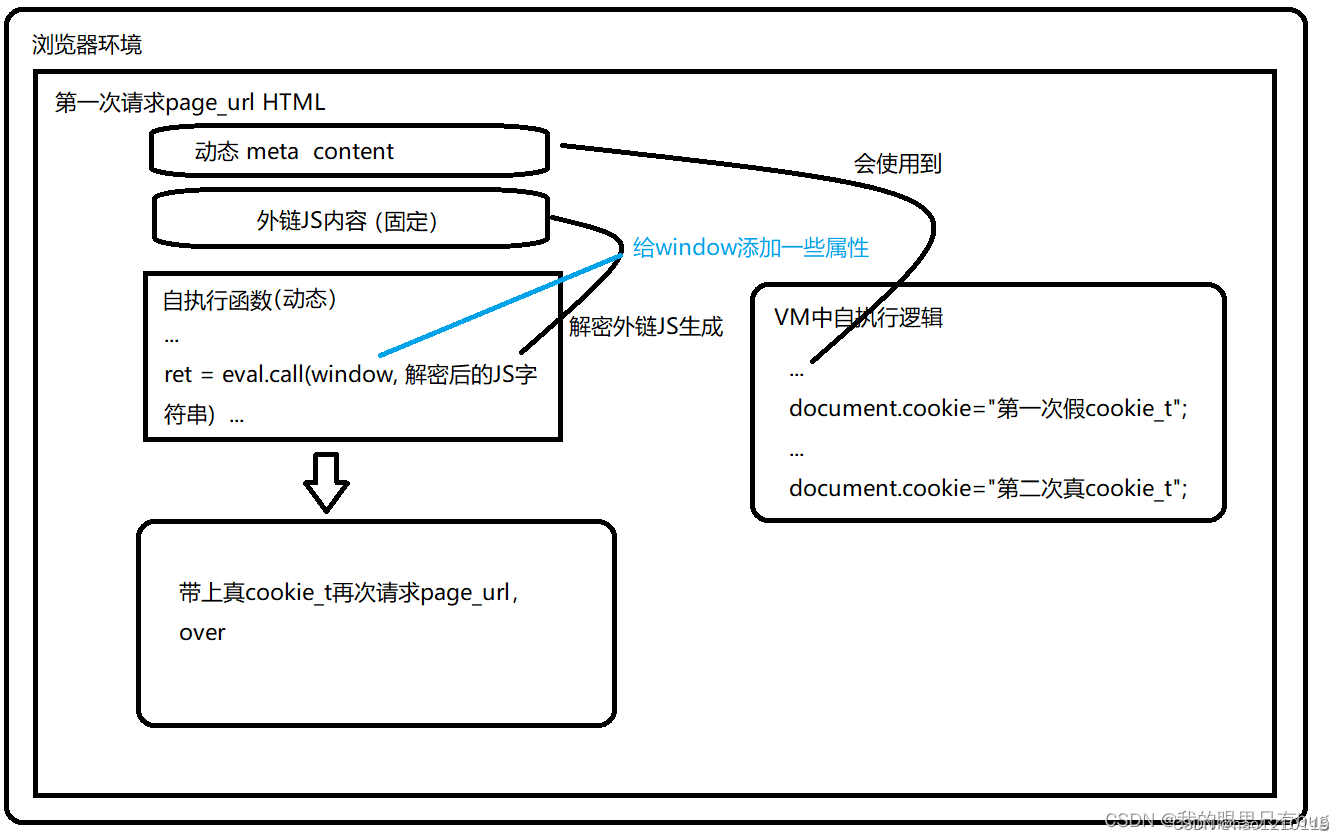
这里我们需要关注eval调用的位置(也就是VM的入口),cookie生成的位置。
我们直接hook eval或搜索.call就可以定位到调用eval的位置
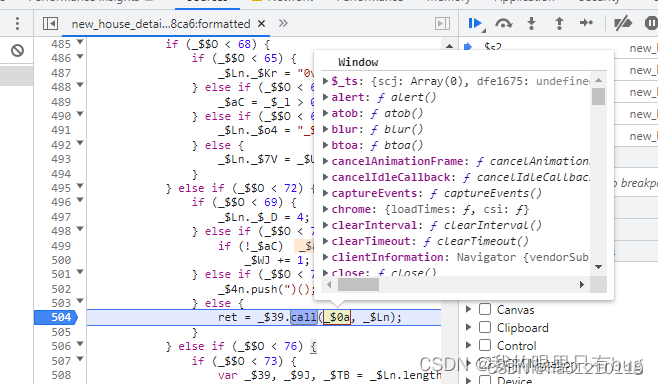
_$Ln就是解密后的js代码字符串;进入vm是一个自执行函数,其中有生成cookie的逻辑,定位cookie可以直接hook或在vm代码中搜索 (5)
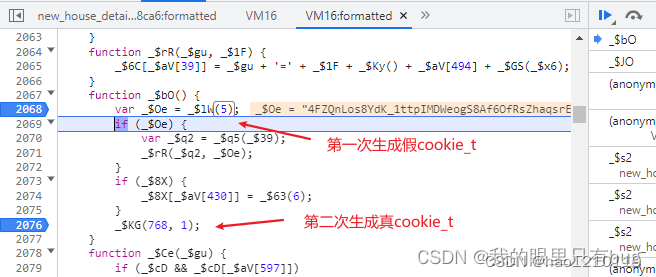
hook cookie代码:
// hook 指定cookie赋值
(function () {
'use strict';
Object.defineProperty(document, 'cookie', {
set: function (cookie) {
if(cookie.indexOf("FSSBBIl1UgzbN7N80T")!= -1){
debugger;
} 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









