







前言
今天在复习设计模式的时候再次遇到了原型模式,刚开始认为这个设计模式是比较简单的,大家就认为可以在
复习复习深复制和浅复制的知识,在开始的 时候大家都在概念层面对这两个概念的进行了讲解,大家都是比较熟悉
的,但是对于代码中的运用就比较陌生了,所以在讲解代码的时候遇到了问题,经过我们激烈的争论和断点调试程
序,最后终于在代码层面理解了深复制和浅复制的概念,,下面和大家分享一下:
一、概念层面
浅复制:对于值类型的变量不用区分浅复制和深复制,而对于引用类型的变量来说,浅复制就仅仅是将地址
复制过来,并没有将此地址对应的值赋值过来。这时候如果我们改变此地址对应的值,则原来的值也随之改变。
深复制:对于引用类型的变量来说,深复制就是不单单复制对应的地址,而是将对应的值也复制过来。
生活中的实例:
比如说有一个狗被一个狗链拴着,当我们对这个狗进行浅复制的时候,就仅仅的复制出了一条狗链, 而没有
重新出来一条狗,这时候浅复制的结果就是有两条狗链对应着这个狗,如果现在<span style="white-space:pre">甲
将狗腿 打断,这时候乙看到的也是一条断了腿的狗,这就是对这条狗的浅复制的结果。如果对这条狗进行深复制,
则会重新复制出一条狗,而不是仅仅复制一个狗链,这时候如果甲将他对应的狗的狗腿打断,对于乙的狗是没有影响
的,这就是深复制。
下面用代码结合内存给大家分析一下这两者的区别:
" class="csharp"> //工作经验类
class WorkExperience
{
private string workDate;
public string WorkDate //定义一个属性
{
get { return workDate; }
set { workDate = value; }
}
private string company;
public string Company
{
get { return company; }
set { company = value; }
}
}
//简历类
class Resume : ICloneable
{
private string name;
private string sex;
private string age;
private WorkExperience work; //引用工作经历对象
public Resume(string name) //构造函数 并且在类实例化是同时实例化工作经历
{
this.name = name;
work = new WorkExperience();
}
//设置个人信息
public void SetPersonalInfo(string sex, string age)
{
this.sex = sex;
this.age = age;
}
//设置工作经历
public void SetWorkExperience(string workDate, string company)
{
work.WorkDate = workDate;
work.Company = company;
}
//显示
public void Display()
{
Console.WriteLine("{0} {1} {2}", name, sex, age);
Console.WriteLine("{0} {1}", work.WorkDate, work.Company);
}
public object Clone()
{
return (object)this.MemberwiseClone();
}
}
公共客户端:
static void Main(string[] args)
{
//深复制和浅复制的客户端代码相同
Resume a = new Resume("大鸟");
a.SetPersonalInfo("男", "29");
a.SetWorkExperience("1998-2000", "xx公司");
Resume b = (Resume)a.Clone();
b.SetWorkExperience("1998-2006", "YY公司");
Resume c = (Resume)a.Clone();
c.SetPersonalInfo("男", "24");
c.SetWorkExperience("1998-2003", "zz企业");
a.Display();
b.Display();
c.Display();
Console.Read();
}
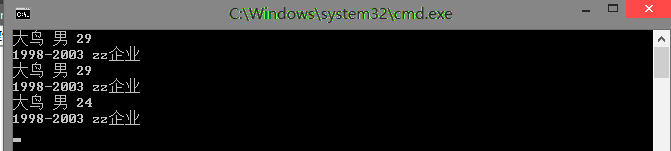
大家在查看的代码的时候应该能理解到这个地方,那就是Clone()这个方法在哪个类里面,当我们调用的时候
就会创建一个新的实例出来,有了这样的基本理解以后会对理解代码有很多的帮助。首先我们来观察一下浅复制的内
存是什么样的?
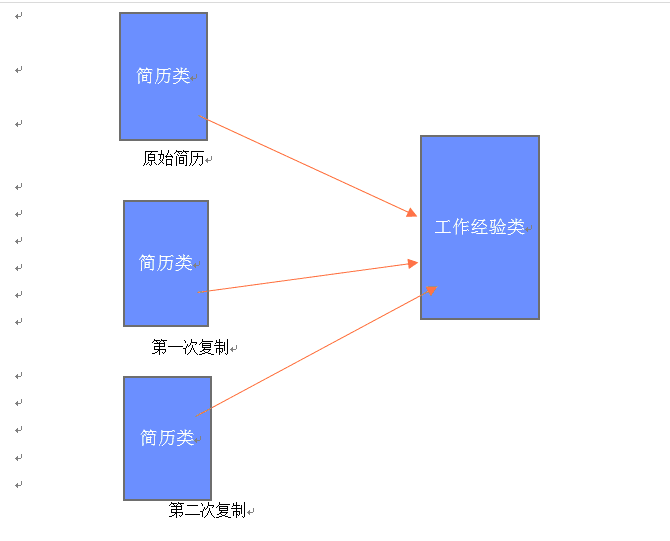
我们从代码中就可以看到,Clone()这个方法是在简历类里面出现的,所以当我们在客户端调用的时候,每次
调用Clone()这个方法都会新建一个简历类,但是不会新建一个工作经验类,每次复制出来的类里面对工作经验类
的引用同时指向了同一个工作经验类,所以这样我们每次修改的都是同一个类,这样我们在最后输出的时候就将最后
一次修改的内容输出,所以就得到了上面的结果。
详解深复制:
深复制代码:工作经验类
public class WorkExperience : ICloneable //让工作经历实现ICloneable接口
{
private string workDate;
public string WorkDate //定义一个属性
{
get { return workDate; }
set { workDate = value; }
}
private string company;
public string Company
{
get { return company; }
set { company = value; }
}
<strong><span style="color:#ff0000;">public object Clone() //工作经历类,实现克隆方法
{
return (object)this.MemberwiseClone();
}</span></strong>
}
简历类:
//简历类
public class Resume : ICloneable
{
private string name;
private string sex;
private string age;
private WorkExperience work; //引用工作经历对象
public Resume(string name) //构造函数 并且在类实例化是同时实例化工作经历
{
this.name = name;
work = new WorkExperience();
}
//提供Clone 方法调用的私有构造函数,以便克隆工作经历 的数据
<strong><span style="color:#ff0000;"> private Resume(WorkExperience work)
{
this.work = (WorkExperience)work.Clone();
}</span></strong>
//设置个人信息
public void SetPersonalInfo(string sex, string age)
{
this.sex = sex;
this.age = age;
}
//设置工作经历
public void SetWorkExperience(string workDate, string company)
{
work.WorkDate = workDate;
work.Company = company;
}
//显示
public void Display()
{
Console.WriteLine("{0} {1} {2}", name, sex, age);
Console.WriteLine("{0} {1}", work.WorkDate, work.Company);
}
//调用私有的构造方法,让 工作经历 克隆完成,然后在给这个简历 对象的相关字段赋值
//最终返回一个深赋值的简历对象
<strong><span style="color:#ff0000;"> public object Clone()
{
Resume obj = new Resume(this.work);
obj.name = this.name;
obj.sex = sex;
obj.age = age;
return obj;
}</span></strong>
}
首先我们应该观察到深复制和浅复制的代码的差别在什么地方,见代码中的红色部分,在深复制代码中在工作
经验类和简历类中都有了Clone()这个方法,并且在简历这个类中有了一个私有的构造函数,这个构造函数是在
Clone()方法里面用到的,下面结合内存的变化给大家分析深复制:
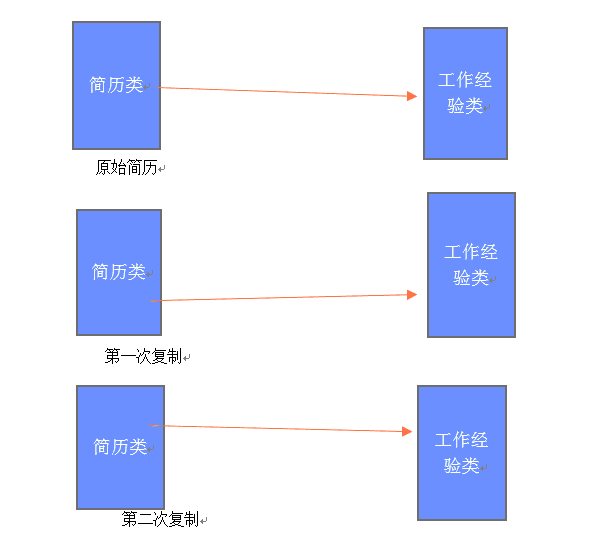
我们来分析代码,当我们在客户端实例化一个简历类的时候,就会创建一个简历类和工作经验类(看代码),
然后在第一次调用简历类里面的Clone()方法的时候,会在重新创建一个简历类,然后进入私有的简历类构造函
数,在这个构造函数中调用工作经验类里面的Clone()方法,这时候又创建了一个新的工作经验类,所以这样我们
就形成了上图这样的内存布局,所以当我们修改工作经验类里面的内容的时候,不会影响别的类里面的内容,就得出
了上面的运行结果。
小结
深复制和浅复制是我们必须掌握的知识,因为如果我们的编码过程中一旦用到了这个知识,在查错的时候非常
的不容易,因为逻辑和代码有不会有明显的错误,但是结果就是得不到我们想要的结果,这样就会大量的浪费我们的
时间,所以我们一定要掌握这两者的区别,希望这篇博客能给读者一点帮助!!

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











