






jupyter notebook(python 3.12.7) + WordCloud
1.安装必要的包:
pip install wordcloud matplotlib jieba检查是否安装成功:
import jieba
print("安装成功!" if jieba.__version__ else "失败")
2.用示例文本运行代码:
# -*- coding: utf-8 -*-
import os
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
from matplotlib import font_manager
# ===== 1. 中文环境初始化 =====
def init_chinese_font():
"""检测并配置中文字体"""
try:
# Windows/Mac/Linux通用检测逻辑
font_path = font_manager.findfont(font_manager.FontProperties(
family=['sans-serif'],
weight='normal',
style='normal'
))
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'WenQuanYi Micro Hei']
plt.rcParams['axes.unicode_minus'] = False
return font_path
except:
raise RuntimeError("中文字体配置失败,请安装SimHei字体")
# ===== 2. 示例文本处理 =====
text = """
自然语言处理是人工智能领域的重要方向,深度学习技术极大地推动了该领域的发展。
中文分词、词性标注、命名实体识别都是中文信息处理的基础任务。近年来,
基于Transformer的预训练模型如BERT、GPT等在多个NLP任务上取得了突破性进展。
研究者们正在探索更高效的模型架构和训练方法,同时关注模型的可解释性和能耗问题。
"""
# ===== 3. 智能分词处理 =====
def chinese_text_segment(text):
"""中文分词与清洗"""
# 加载停用词表
stopwords = set(line.strip() for line in open('stopwords.txt', encoding='utf-8')
if line.strip()) if os.path.exists('stopwords.txt') else {
"的", "了", "和", "是", "在", "等", "如", "基于", "个", "都", "等"
}
# 精确模式分词
words = jieba.cut(text)
return [word for word in words
if len(word) > 1
and word not in stopwords
and not word.isspace()]
# ===== 4. 生成词云 =====
try:
# 初始化字体环境
font_path = init_chinese_font()
print(f"当前使用字体:{font_path}")
# 执行分词
words = chinese_text_segment(text)
print("分词结果示例:", words[:10])
# 生成词云对象
wc = WordCloud(
font_path=font_path,
width=1200,
height=800,
background_color='white',
max_words=150,
collocations=False,
scale=3 # 提升输出分辨率
).generate(" ".join(words))
# 可视化展示
plt.figure(figsize=(15, 10))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.title("自然语言处理主题词云", pad=20, fontsize=18)
plt.savefig('nlp_wordcloud.png', dpi=300, bbox_inches='tight')
plt.show()
# 高频词统计
word_freq = Counter(words).most_common(15)
print("\n高频词TOP15:")
for idx, (word, count) in enumerate(word_freq, 1):
print(f"{idx:2d}. {word:<6} {count:>3}次")
except Exception as e:
print(f"执行出错:{str(e)}")
print("故障排除:")
print("1. 确保已安装中文字体:https://zhuanlan.zhihu.com/p/499533144")
print("2. 检查文件权限")
print("3. 更新依赖库:pip install --upgrade wordcloud jieba matplotlib")
输出结果:



3.把示例文本替换成导入桌面指定txt文档,运行新代码:
(提前在桌面创建了一个名为input.txt的文档)
# -*- coding: utf-8 -*-
import os
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
from matplotlib import font_manager
# ===== 1. 中文环境初始化 =====
def init_chinese_font():
"""检测并配置中文字体"""
try:
# Windows/Mac/Linux通用检测逻辑
font_path = font_manager.findfont(font_manager.FontProperties(
family=['sans-serif'],
weight='normal',
style='normal'
))
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'WenQuanYi Micro Hei']
plt.rcParams['axes.unicode_minus'] = False
return font_path
except:
raise RuntimeError("中文字体配置失败,请安装SimHei字体")
# ===== 2. 文件读取函数 =====
def read_desktop_file(filename="input.txt"):
"""自动读取桌面文档"""
# 获取桌面路径(跨平台兼容)
desktop_path = os.path.join(os.path.expanduser('~'), 'Desktop')
# 支持常见文本格式
file_path = os.path.join(desktop_path, filename)
# 自动尝试不同编码读取
encodings = ['utf-8', 'gbk', 'gb2312', 'gb18030']
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
return f.read()
except UnicodeDecodeError:
continue
raise UnicodeError(f"无法解码文件 {filename},请确保使用UTF-8/GBK编码")
# ===== 3. 智能分词处理 =====
def chinese_text_segment(text):
"""中文分词与清洗"""
# 加载停用词表
stopwords = set(line.strip() for line in open('stopwords.txt', encoding='utf-8')
if line.strip()) if os.path.exists('stopwords.txt') else {
"的", "了", "和", "是", "在", "等", "如", "基于", "个", "都", "等"
}
# 精确模式分词
words = jieba.cut(text)
return [word for word in words
if len(word) > 1
and word not in stopwords
and not word.isspace()]
# ===== 4. 生成词云 =====
try:
# 初始化字体环境
font_path = init_chinese_font()
print(f"当前使用字体:{font_path}")
# 读取桌面文档(自动检测常见文件名)
doc_names = ['input.txt', 'text.txt', '文档.txt', 'data.txt']
for name in doc_names:
if os.path.exists(os.path.join(os.path.expanduser('~'), 'Desktop', name)):
text = read_desktop_file(name)
print(f"成功读取文档:{name}")
break
else:
raise FileNotFoundError("未找到输入文件,请在桌面创建input.txt/text.txt/文档.txt")
# 执行分词
words = chinese_text_segment(text)
print("分词结果示例:", words[:10])
# 生成词云对象
wc = WordCloud(
font_path=font_path,
width=1200,
height=800,
background_color='white',
max_words=150,
collocations=False,
scale=3 # 提升输出分辨率
).generate(" ".join(words))
# 可视化展示
plt.figure(figsize=(15, 10))
plt.imshow(wc, interpolation='bilinear')
plt.axis("off")
plt.title("文档分析词云", pad=20, fontsize=18)
output_path = os.path.join(os.path.expanduser('~'), 'Desktop', 'wordcloud.png')
plt.savefig(output_path, dpi=300, bbox_inches='tight')
print(f"词云已保存至桌面:{output_path}")
plt.show()
# 高频词统计
word_freq = Counter(words).most_common(15)
print("\n高频词TOP15:")
for idx, (word, count) in enumerate(word_freq, 1):
print(f"{idx:2d}. {word:<6} {count:>3}次")
except Exception as e:
print(f"执行出错:{str(e)}")
print("故障排除:")
print("1. 请在桌面创建包含中文文本的input.txt/text.txt文件")
print("2. 确保文件编码为UTF-8或GBK")
print("3. 中文字体安装指南:https://zhuanlan.zhihu.com/p/499533144")
print("4. 更新依赖库:pip install --upgrade wordcloud jieba matplotlib")
输出结果: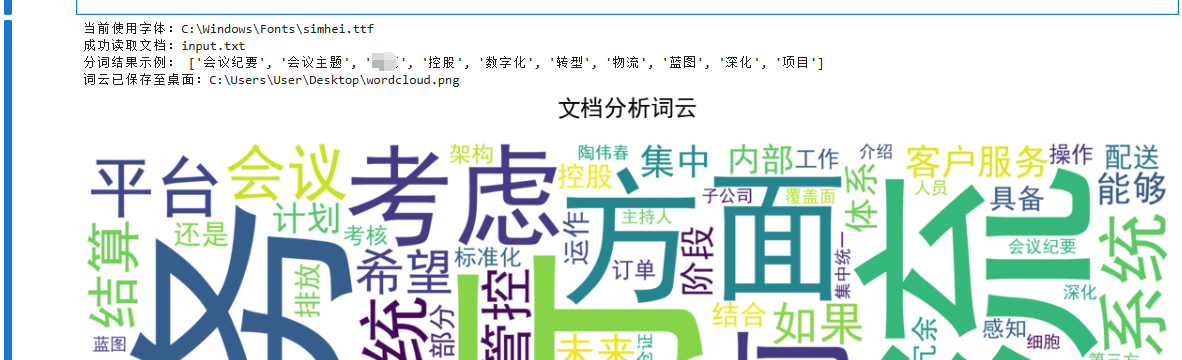
4.把指定桌面txt文档替换成指定文件夹内的txt多个文档,运行新代码:
# -*- coding: utf-8 -*-
import os
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
from collections import Counter
from matplotlib import font_manager
# ===== 1. 中文环境初始化 =====
def init_chinese_font():
"""检测并配置中文字体"""
try:
font_path = font_manager.findfont(
font_manager.FontProperties(family=['sans-serif'])
)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
return font_path
except:
raise RuntimeError("中文字体配置失败,请安装SimHei字体")
# ===== 2. 多文件读取函数 =====
def read_txt_files(folder_path):
"""批量读取指定文件夹内所有txt文件"""
# 验证路径有效性
if not os.path.exists(folder_path):
raise FileNotFoundError(f"路径不存在: {folder_path}")
if not os.path.isdir(folder_path):
raise NotADirectoryError(f"不是有效文件夹: {folder_path}")
# 获取所有txt文件
txt_files = [f for f in os.listdir(folder_path)
if f.lower().endswith('.txt')]
if not txt_files:
raise FileNotFoundError(f"文件夹内未找到txt文件: {folder_path}")
# 合并文本内容
all_text = []
for filename in txt_files:
file_path = os.path.join(folder_path, filename)
print(f"正在读取: {filename}")
# 自动检测编码
encodings = ['utf-8', 'gbk', 'gb2312', 'gb18030']
for encoding in encodings:
try:
with open(file_path, 'r', encoding=encoding) as f:
all_text.append(f.read())
break
except UnicodeDecodeError:
continue
else:
print(f"警告: {filename} 解码失败,已跳过")
return '\n'.join(all_text)
# ===== 3. 增强版分词处理 =====
def chinese_text_segment(text):
"""带停用词过滤的分词"""
# 加载停用词表
stopwords = set()
if os.path.exists('stopwords.txt'):
with open('stopwords.txt', 'r', encoding='utf-8') as f:
stopwords = {line.strip() for line in f if line.strip()}
else:
stopwords = {"的", "了", "和", "是", "在", "等", "如", "个", "都"}
# 精确模式分词 + 词性过滤
import jieba.posseg as pseg
allow_pos = {'n', 'v', 'a', 'eng'} # 保留名词、动词、形容词、英文
words = []
for word, flag in pseg.cut(text):
if (len(word) > 1 and
flag[0] in allow_pos and
word not in stopwords and
not word.isspace()):
words.append(word)
return words
# ===== 4. 主程序 =====
if __name__ == "__main__":
try:
# ==== 用户配置 ====
TARGET_FOLDER = r"D:\数据分析\文本资料" # 修改为你的文件夹路径
# 初始化字体
font_path = init_chinese_font()
print(f"字体配置成功: {font_path}")
# 读取并合并文本
combined_text = read_txt_files(TARGET_FOLDER)
print(f"共读取到{len(combined_text)}个字符")
# 执行分词
words = chinese_text_segment(combined_text)
print(f"有效词汇总数: {len(words)}")
print("示例词汇:", words[:15])
# 生成词云
wc = WordCloud(
font_path=font_path,
width=1600,
height=1200,
background_color='white',
max_words=300,
collocations=False,
scale=3
).generate(" ".join(words))
# 保存结果
output_path = os.path.join(TARGET_FOLDER, "合并分析_词云.png")
plt.figure(figsize=(18, 12))
plt.imshow(wc, interpolation="bilinear")
plt.axis("off")
plt.savefig(output_path, dpi=300, bbox_inches="tight")
print(f"\n词云已保存至: {output_path}")
# 高频词统计
counter = Counter(words).most_common(30)
print("\n高频词TOP30:")
for idx, (word, count) in enumerate(counter, 1):
print(f"{idx:2d}. {word:<8} {count:>4}次")
except Exception as e:
print(f"\n错误发生: {str(e)}")
print("排查建议:")
print("1. 检查文件夹路径是否正确(建议使用原始字符串格式)")
print("2. 确保文件夹内有.txt文件")
print("3. 尝试将文件编码统一转为UTF-8")
print("4. 安装必要字体: https://zhuanlan.zhihu.com/p/499533144")
注意把代码中的文件夹替换成自己需要的:

运行结果:


一般可以先一键运行词云,看看自动分词的效果,然后再根据业务去调整词典修正运行结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









