







HTTP和HTTPS
http协议(超文本传输协议):发布和接收HTML页面的方法。端口为80。
https=htttp+ssl
ssl(安全套接层):用于Web的安全传输协议,在传输层对网络连接进行加密。端口为443。
URL:统一资源定位符,用于完整地描述Internet上网页和其他资源的地址的一种标识方法。
基本格式:scheme://host[:post#]/path/.../[?query-string][#anchor]
- scheme:协议
- host:服务器的IP地址或者域名
- port#:服务器的端口(缺省端口80)
- query-string:参数,发送给http服务器的数据
- anchor:锚(跳到指定位置)
客户端HTTP请求
URL标识资源的位置,而HTTP是用来提交和获取资源。客户端发送一个HTTP请求到服务器的请求消息,包括以下格式:
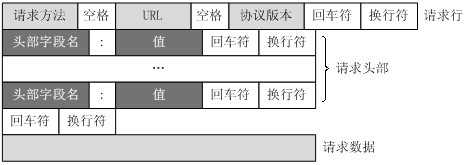
典型的HTTP请求示例:
GET https://www.damai.cn/ HTTP/1.1
Host: www.damai.cn
Connection: keep-alive
Upgrade-Insecure-Requests: 1
DNT: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8
Referer: https://www.baidu.com/link?url=ZBziBEm6R_HQVWkifpgxM7E56g_SEhz8Sl9itsjPDGW&ck=6546.1.84.243.180.237.173.239&shh=www.baidu.com&wd=&eqid=a4252bdf000d2333000000065d58eb16
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: cna=2xY7FFYLQ1QCAcpwHgTO9GjM; t=0e3ca88ab55a2a26b307d3b20bb2ec82; damai.cn_nickName=46aab95040c54dbb; UM_distinctid=16c10a654da219-0d7733fafd64c3-b781636-144000-16c10a654dbe9; cn_7415364c9dab5n09ff68_dplus=%7B%22distinct_id%22%3A%20%2216c10a654da219-0d7733fafd64c3-b781636-144000-16c10a654dbe9%22%2C%22%24_sessionid%22%3A%200%2C%22%24_sessionTime%22%3A%201563647477%2C%22%24dp%22%3A%200%2C%22%24_sessionPVTime%22%3A%201563647477%2C%22initial_view_time%22%3A%20%221563672541%22%2C%22initial_referrer%22%3A%20%22https%3A%2F%2Fwww.damai.cn%2F%22%2C%22initial_referrer_domain%22%3A%20%22www.damai.cn%22%7D; isg=BEpKIERHI9Ind68aWf20JCKsmzAsk8-QyFqnrtSAyx25h-tBvMlOpVC2k7P-cUYt; l=cB_JHyZnq_dwCNPpBOfaquI8Ly7OwMOb8rVzw4OMaICPOj1p2YiFWZelMLT9CnGVLsakR3z5HU79BDYs4yUIQwatyhumZpiM.
- GET 不包括在请求头中
- Host(主机和端口号)对应URL中的Web名称和端口号
- Connection(连接类型)keep-alive 保持连接
- Upgrade-Insecure-Requests 1表示在加载http资源时自动替换成https请求。
- User-Agent(浏览器名称)
- Accept(传输文件类型)浏览器可接受的文件类型 /:什么都可以接收。
- Referer(页面跳转处)表明产生请求的页面是来自哪里,比如上面的页面是来自百度搜索结果。
- Accept-Encoding(文件编解码格式) 指出浏览器可以接收的编码方式。
- Accept-Language(语言种类)指出浏览器可以接受的语言种类。
- Accept-Charset(字符编码)指出浏览器可以接受的字符编码
- Cookie 记载和服务器相关的用户信息
- Content-Type(POST数据类型)
urllib库
参考自
Python网络请求urllib和urllib3详解
http状态码
Python3 — 爬虫之Handler处理器和自定义Opener
from urllib import request, parse
headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36'}
url = 'https://www.damai.cn/'
#使用python3 中的urllib.request 发送GET请求
#reget = request.urlopen(url)
#html = reget.read().decode()
#print(html)
#发送POST请求
data = {"username":'AUTO', 'password':'kk12345.'}
#将data字典序列化成字符串
data_string = parse.urlencode(data)
#因post请求的数据是二进制数据,转换成二进制数据
last_data = bytes(data_string, encoding='utf-8')
repost = request.urlopen('http://httpbin.org/post', data=last_data)
html = repost.read().decode()
print(html)
#借助Request对象添加Headers
#head = request.Request(url,headers=headers)
#rehead = request.urlopen(head)
#html = rehead.read().decode()
#print(html)
#将中文字符转换成url编码格式 解码用unquote()方法
#wd = '开心d'
#print(parse.quote(wd)) #%E5%BC%80%E5%BF%83d
#对于url多参数,使用urlencode(),传入参数是一个字典
#wds = {'wd':'开心', 'code':'1', 'status':'True'}
#print(parse.urlencode(wds)) # wd=%E5%BC%80%E5%BF%83&code=1&status=True
#Handler处理器和自定义Opener,开启DeBug Log
#http_handler = request.HTTPHandler(debuglevel=1)
#https_handler = request.HTTPSHandler(debuglevel=1)#构建HTTPSHandler处理对象
#opener = request.build_opener(http_handler)
#re_hand = request.Request(url)
#response = opener.open(re_hand)
#print(response.read().decode())
#ProxyHandler处理器(代理)
#httpproxy_handler = request.ProxyHandler({"http":"60.13.42.141:9999"}) #公用免费代理
#authhttpproxy_handler = request.ProxyHandler({"http":"username:password@代理IP"}) #私密代理
#opener = request.build_opener(httpproxy_handler)
#req = request.Request(url, headers=headers)
#response = opener.open(req)
#print(response.read().decode())
csdnurl = "https://mp.csdn.net/postlist/"
#密码管理对象
#username = 'user'
#password = '123456'
#webserver = "192.168.21.52" #私密代理IP
#passwordMgr = request.HTTPPasswordMgrWithDefaultRealm()
##添加授权账号信息,第一参数是域名,没有就指定为None
#passwordMgr.add_password(None, csdnurl, username, password)
##proxyauth_handler = request.ProxyBasicAuthHandler(passwordMgr)#验证代理身份
#httpauth_handler = request.HTTPBasicAuthHandler(passwordMgr)#HTTP基础用户名/密码验证(Web客户端验证)
#opener = request.build_opener(httpauth_handler)
#request = request.Request(csdnurl, headers = headers)
#response = opener.open(request)
#print(response.read().decode())
正则表达式
参考 python3 re模块
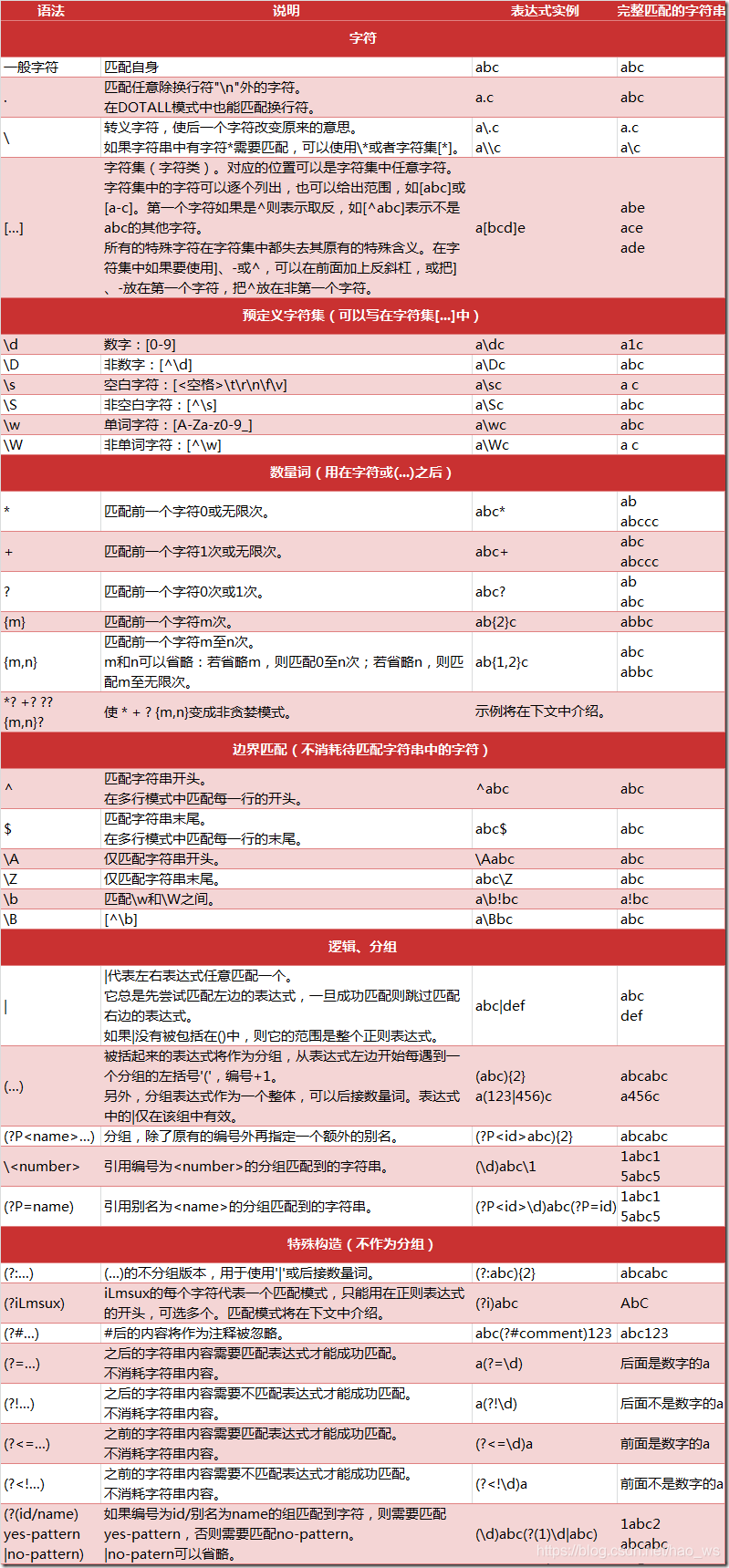
import re
#替换
phone = '2004-855-855 #这是个电话号'
#删除注释
new_phone = re.sub('#.*', '', phone)
#或者 new_phone = re.sub('\D', '', phone)
print(new_phone) #2004-855-855
def double_matched(matched):
value = int(matched.group('value'))
return str(value*2)
ss = 'A23G4KKM67U678h' #替换规则可以是函数
new_ss = re.sub('(?P<value>\d+)', double_matched, ss)
print(new_ss) #A46G8KKM134U1356h
#原生字符串
print("ke\nee\tcc")
#ke
#ee cc
print(r"ke\nee\tcc")
#ke\nee\tcc
用lxml和json获取数据
import json
import requests
from lxml import etree
url = 'https://www.qiushibaike.com/' #糗事百科首页
headers = {'User-Agent':'Mozilla/5.0 (compatible: MSIE 9.0; Windows NT 6.1; Trident/5.0;'}
response = requests.get(url,headers=headers)
#解析html dom模式
html = etree.HTML(response.text)
#获取首页每个文章的连接尾部
link = html.xpath("//a[@class='recmd-content']//@href")
for l in link:
article_url = "https://www.qiushibaike.com" + l #获取文章的url
article_response = requests.get(article_url,headers=headers)
article = etree.HTML(article_response.text)
context = article.xpath('//div[@class="content"]')[0].text
username = article.xpath("//span[@class='side-user-name']")[0].text
fun_nums = article.xpath("//i[@class='number']")[0].text
items = {
'username' : username,
'context' : context,
'fun_nums' : fun_nums
}
with open('qiushi.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(items, ensure_ascii=False) + "\n")
requests库
import requests
#get方式
data = {
'name':'gg',
'age':22
}
response_get = requests.get('http://httpbin.org/get',params=data)
print(response_get.text)
#解析json
import json
response_json = requests.get('http://httpbin.org/get')
print(response_json.json())
#获取二进制数据(图片,视频)
response_er = requests.get('https://github.com/favicon.ico')
with open('favicon.ico', 'wb') as f:
f.write(response_er.content)
#添加一个headers
headers = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64; rv:67.0) Gecko/20100101 Firefox/67.0'
}
response_headers = requests.get('https://www.zhihu.com/explore',headers=headers)
#Post请求
response_post = requests.post('http://httpbin.org/post',data=data,headers=headers)
#print(response_post.json())
#文件上传
files = {'file':open('favicon.ico','rb')}
response_files = requests.post('http://httpbin.org/post',files=files)
print(response_files.text)
#获取cookie 会话维持(模拟登陆)
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456798')
response_cookie = s.get('http://httpbin.org/cookies')
# 代理设置
proxies = {
'http':'http://user:password@218.66.253.145:8800',
'https':'https://112.111.119.232:9000',
}
from requests.exceptions import ReadTimeout
try:
response_pro = requests.get('http://www.taobao.com', proxies=None, timeout=0.05) #1秒
print(response_pro.status_code)
except ReadTimeout:
print('Timeout')















 6534
6534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









