







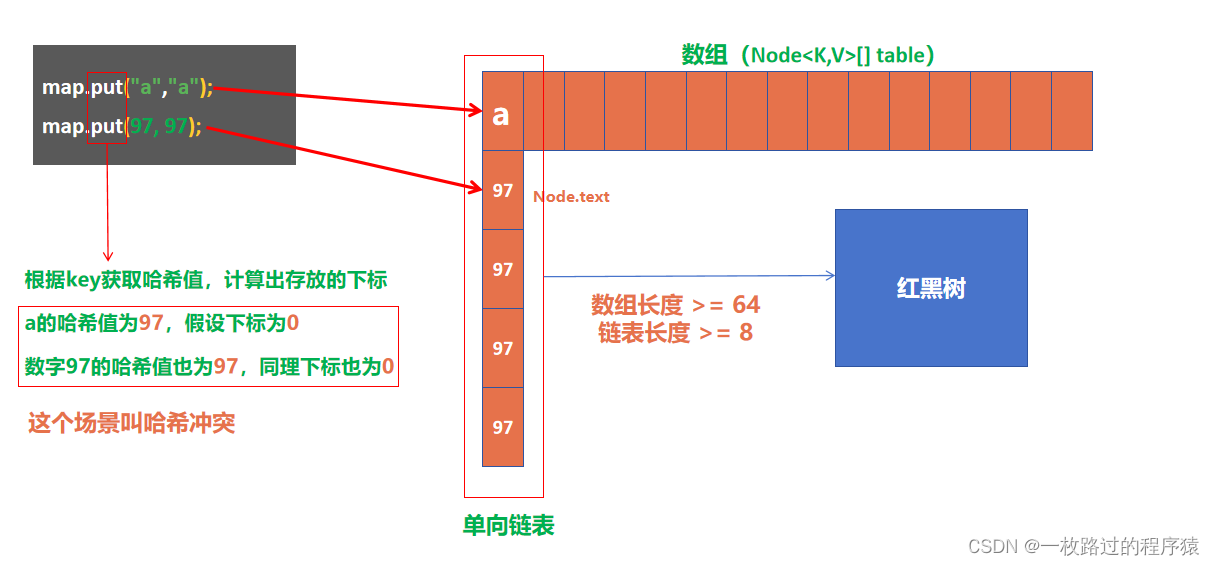
什么是ConcurrentHashMap
基于CAS和Synchronized实现的线程安全Map,key或value不允许为空,由数组+链表+红黑树实现
源码分析
1、初始化数组
sizeCtl含义:负数表示正在扩容,0表示没有初始化,正数表示扩容阈值
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0) // 小于0表示正在进行初始化,需要其余线程进行等待
Thread.yield(); // 让CPU放弃线程执行权
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { // 使用CAS限制并发执行,更新sizeCtl为-1
try {
// 二次验证数组是否为空
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
sc = n - (n >>> 2); //更新sizeCtl为扩容阈值
}
} finally {
sizeCtl = sc;
}
break;
}
}
return tab;
}
通过阅读源码,我们可以体会到设计的巧妙,利用CAS + 循环来处理线程并发问题,如果经常阅读源码,可以发现很多的位操作
2、Synchronized具体使用
链表插入、红黑树的添加和链表转红黑树都是使用Synchronized锁住哈希桶,来处理线程安全
3、扩容以及协助扩容
private final void tryPresize(int size) {
//......省略部分代码
int sc;
while ((sc = sizeCtl) >= 0) {
//......省略部分代码
else if (tab == table) {
int rs = resizeStamp(n); //获取扩容标识戳
if (sc < 0) { //小于0表示正在扩容
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) //每次协助继续扩容时,扩容标识戳+1
transfer(tab, nt);
}
//初始化扩容时使用CAS更新sizeCtl
else if (U.compareAndSwapInt(this, SIZECTL, sc, (rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
看完上面的代码,可能还是有点懵,没关系一点一点解读,这段代码里面也体现出了协助扩容
先来聊聊获取扩容标识戳方法resizeStamp(n),获取时需要传入数组的长度,这个参数说白了就是为了获取标识戳时可以有一个参照
static final int resizeStamp(int n) {
// (1 << (RESIZE_STAMP_BITS - 1)) = 32768,此数值固定为32768
return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)); //
}
Integer.numberOfLeadingZeros(n):用来获取有多少个前导零,也就是n的二进制存在多少前导零,你要是细心的话,可以发现,数组初始扩容为16,每次扩容的长度为 初始长度 << 1,用二进制表示的话,只有一位是1,其余位都为0,那么只需要获取前导零,存储起来就可以直接反向推算出来原来的数组长度
|或操作符:两个位只要有一位为1,就为1,否则为0,可以看下面的以n等于16举例
1000 0000 0000 0000 =32768
0001 1011 =27
__________________________________________
1000 0000 0001 1011 =32795
了解完如何生成扩容表示戳之后,我们直奔主题具体扩容
准备工作
- 计算扩容标识戳 rs
int rs = resizeStamp(n) - 开始扩容,使用cas设置
sizeCtl = (rs << 16)+ 2第一次扩容直接+2,每次协助扩容时+1
开始扩容
- 计算扩容步长
stride,默认16,计算公式:(NCPU > 1) ? (n >>> 3) / NCPU : n) - 设置迁移下标参数
transferIndex,默认为旧数组长度 - 计算迁移范围参数
nextIndex(开始下标), nextBound(结束下标),总体的迁移为从后往前迁移
nextBound = (nextIndex > stride ? nextIndex - stride : 0):结束下标 = 迁移下标 > 迁移步长 ? 迁移下标 - 迁移步长 : 0
nextIndex = transferIndex - 1:开始下标 = 迁移下标 - 1
这块需要注意:协助扩容的体现主要是这块,通过步长计算出每次迁移的范围,可以仔细体会一下 - 创建迁移对象(hash为-1),开始迁移,分为两种情况
旧数组i位置元素为null:使用CAS直接插入迁移对象
不为空:使用synchronized锁住当前哈希桶,开始分别迁移链表和红黑树的情况
在添加方法中可以看到这样一段代码(fh = f.hash) == MOVED用来校验是否可以协助扩容,都是前后对应 - 每当有线程迁移完自己区域之后,会使用
CAS更新sizeCtl = sizeCtl -1,上面在协助扩容的时候,每次协助扩容是+1,前后对应。 - 最后校验是否迁移完成
(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT,这段代码在源码中有体现,初始扩容时直接在扩容标识戳+2,此处-2就用来校验是否全部迁移完成,如果没有迁移完成,协助迁移的线程退出迁移逻辑,迁移完成之后,最后一条线程需要进行一遍检查
迁移逻辑到此就结束了,是不是发现没有那么难?
在源代码中有一块设计没有理解,有知道的小伙伴,可以指导一下
在初始扩容时,已经计算好了扩容标识戳,为啥要在后续操作中,要来回的位移操作进行校验呢?直接使用计算好的扩容标识戳不是更加好吗?
手写一个线程安全的Map
欢迎访问源代码仓库,里面收集了树型结构、List等源码,后续会持续更新源码系列 tryCode
import sun.misc.Unsafe;
import java.lang.reflect.Field;
import java.util.concurrent.atomic.AtomicLong;
/**
* @Description: 手动实现并发的哈希表,体现:synchronized、Unsafe、CAS
* @Author 一枚路过的程序猿
* @Date 2023/11/10 14:31
* @Version 1.0
*/
public class MyConcurrentMap<K extends Comparable<K>,V> {
/** 初始长度 */
final int DEFAULT_CAPACITY = 16;
/** 初始全局数组 */
Node<K,V>[] tab;
/** 数组长度 */
AtomicLong size = new AtomicLong(0);
/** 单个哈希桶链表长度阈值,进行转换红黑树 */
static final int TREEIFY_THRESHOLD = 8;
/** 数组长度阈值,进行转换红黑树*/
static final int MIN_TREEIFY_CAPACITY = 64;
/** 迁移的下标 */
volatile int transferIndex;
/** 扩容数组 */
volatile Node<K, V>[] nextTable;
/** 扩容标记 */
static final int MOVED = -1;
/**
* 仿照源码中表示:
* -1:正在初始化
* 0:还没有初始化
* 正数:如果已经扩容,标识扩容阈值
* */
int sizeCtl;
public void putVal(K k, V v){
if(k == null || v == null){
throw new NullPointerException("key or value not null");
}
if(tab == null){
/** 初始化数组tab */
initTable();
}
/** 根据 Key 获取哈希值 */
int hashCode = getHashCode(k);
/**
* 根据 hashCode 计算下标位置
* 使用 数组长度-1 与运算 哈希值,
*
* 这样设计的好处:与运算是确保下标范围,防止越界;提高查询节点效率,位运算的操作效率是最高的;可以体现出一部分散列分布
*
* 与用算符表示:两个操作数中位都为1,才为1,否则为0
* 例:
* 001010001 -> 81
* 111011001 -> 473
* ——————————————
* 001010001 -> 81
*
*/
int i = (tab.length - 1) & hashCode;
Node<K,V>[] t;
/**
* 此处使用死循环的目的:
* 当多个线程并发 添加 同一下标位置元素时,由于使用的是cas添加,只会有一个线程添加成功,其余线程会继续循环,重新添加,
* 如果不使用死循环,会直接导致本次添加失败,相当于重试的机制
* 为什么添加时,要使用cas添加呢?
* 我们实现的是线程安全的哈希表,如果不用cas,要是有多个线程并发添加同一下标位置元素,会存在覆盖的情况,使用cas + 死循环,
* 可以很好得处理这种并发添加
*/
other:
for (t = tab;;){
/** 获取数组对应下标的元素,使用 Unsafe.getObjectVolatile() 确保可见性 */
Node<K,V> currentNode = tabAt(t, i);
/** 创建待添加对象 */
Node<K, V> n = new Node<K, V>(hashCode, k, v, null);
/**
* 校验下标位置元素是否为空
* 为空:直接插入
* 不为空:需要检验是链表还是红黑树
* 链表:校验是否需要转换为红黑树,不需要直接添加
* 红黑树:直接进行插入
* */
if(currentNode == null){
/**
* 如果添加成功,直接退出
* 此处考虑添加失败和并发情况,使用CAS设置值,确保了一致性和安全性
* */
if (casTabAt(t, i, null, n)) {
break;
}
/** 校验当前节点是否在迁移,如果是,进行协助扩容 */
} else if (currentNode.hash == MOVED) {
t = helpTransfer(t, currentNode);
} else if(currentNode instanceof TreeNode){ /** 红黑树 */
//TODO 此处红黑树不维护原链表
synchronized (currentNode){
TreeNode<K, V> treeNode = (TreeNode<K, V>) currentNode;
treeNode.add(k, v, hashCode, null);
}
}else { /** 链表 */
/**
* 链表处理逻辑(给当前node加锁)
* 校验是不是要更新值,如果是直接更新,如果不是那就继续添加至链表尾部,然后校验是否需要转换红黑树
*/
synchronized (currentNode){
for(int binCount = 0; ;++binCount){
/** 校验是否需要更新值 */
if(currentNode.key == k || k.equals(currentNode.key)){
currentNode.value = v;
return;
}
/** 从链表中添加 */
if (currentNode.next == null) {
currentNode.next = new Node<K, V>(hashCode,k,v,null);
/** 是否满足转换红黑树条件 */
//TODO 源代码中此部分没有包含在synchronized中,因为转换红黑树单独做了线程安全处理,使用的是:synchronized + cas
if(binCount >= TREEIFY_THRESHOLD - 1){
/** 转换为红黑树 */
convertRBT(i);
}
break other;
}
currentNode = currentNode.next;
}
}
}
}
/** 计数 */
addCount();
}
/**
* 协助扩容
* @param t 数组
* @param currentNode 当前节点
*/
private Node<K, V>[] helpTransfer(Node<K, V>[] t, Node<K, V> currentNode) {
Node<K, V>[] nt;
if(t != null && currentNode instanceof ForwardingNode && (nt = ((ForwardingNode<K, V>) currentNode).nextTable) != null){
/** 获取扩容标识 */
int rs = resizeStamp(t.length);
int sc;
/** 是否可以协助扩容 */
while (nt == nextTable && t == tab && (sc = sizeCtl) < 0){
/**
* (sc >>> 16) != rs :获取扩容标识,可以理解为版本号,如果不相等表示不需要协助扩容
* transferIndex <= 0 : 迁移下标如果等于0,表示不需要协助扩容
*/
if((sc >>> 16) != rs || transferIndex <= 0){
break;
}
if (U.compareAndSwapInt(this, SIZE_CTL, sc, sc + 1)) {
transfer(tab, nt);
break;
}
}
return nt;
}
return tab;
}
/**
* 计数器、校验是否需要扩容
* */
private void addCount() {
long count = size.incrementAndGet();
int sc;
while (count >= (sc = sizeCtl)){
int n = tab.length;
Node<K, V>[] t = tab;
/**
* 计算扩容标识
* 高16位表示:区分连续的多次扩容,可理解为一个版本号
* 低16位表示:有n-1个线程正在参与扩容
*
* 对于“n = 16”,resizeStamp(n)将返回 32795
*
* */
int rs = resizeStamp(n);
/** 小于0表示其他线程正在扩容 */
if(sc < 0){
/**
* 校验扩容是否完成:迁移完成为0
* */
Node<K, V>[] nt = nextTable;
if(nt == null || transferIndex <= 0){
break;
}
if(U.compareAndSwapInt(this, SIZE_CTL, sc, sc + 1)){
transfer(t, nt);
}
/**
* 此处以 rs=32795 接着计算
* (rs << 16) + 2) = -2145714174
*
* 使用cas更新之后,并发同时只能更新成功一个,另一个会继续进入循环,从而进入{sc < 0} 进行协助扩容
* 此处 {+2} 因为后十六位表示有n-1个线程正在参与扩容,而在{sc < 0}分支内,协助扩容时每次会 +1 ,在扩容的方法中,每个线程扩容完成之后 {sc - 1},并会-2来校验是否全部扩容完成
*
* 扩容方法中可以看到{ (sc -2) != resizeStamp(n) },来表示是否扩容完成
*
* */
} else if (U.compareAndSwapInt(this, SIZE_CTL, sc, (rs << 16) + 2)) {
/** 初始调用扩容,nextTab 为 null */
transfer(t, null);
}
}
}
/**
*
* 让我们以“n = 16”为例进行详细计算:
* 1.计算二进制表示中前导零的数量:
* 16~的二进制表示:0000 0000 0000 0000 0000 0000 0001 0000
* 前导零的数量:“27” (在第一个中之前有 27 个前导零)
*
* 2.计算高位比特的移位量:
* RESIZE_STAMP_BITS通常在“ConcurrentHashMap’中是“16“
* 1 << (16 - 1): 将 1 移15”位,得到32768。
*
* 3.使用按位 OR操作符将两个值合并:
* leadingZeros | (1 << shiftAmount): 27 | 32768
* 29的二进制表示:0000 0000 0000 0000 0000 0000 0001 1011
* 32768的二进制表示:1000 0000 0000 0000
* 执行按位OR:1000 0000 0000 0000 0000 0000 0001 1011,即 32795 的十进制表示。
* 所以,对于“n = 16”,resizeStamp(n)将返回 32795
*
* @param n
* @return
*/
static final int resizeStamp(int n) {
return Integer.numberOfLeadingZeros(n) | (1 << (16 - 1));
}
/**
* 扩容
* */
private void transfer(Node<K,V>[] oldTab, Node<K,V>[] nextTab) {
/** 获取原数组长度 */
int n = oldTab.length;
/** 扩容步长默认为16 */
int stride = 16;
/** 如果数组是空的,表示第初始化进行扩容,创建扩容数组,长度为:旧数组长度2倍 */
if (nextTab == null) {
nextTable = nextTab = new Node[n << 1];
/** 赋予迁移下标 */
transferIndex = n;
}
/** 创建迁移对象,如果有其他线程正在添加,发现正在扩容,会协助扩容 */
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
/** 下标获取标记 */
boolean advance = true;
/**
* 整体迁移是从后往前进行迁移,每次迁移的长度是根据步长定的
* i:迁移的开始下标 = 旧数组长度n
* bound:迁移的结束下标 = 旧数组长度n - 迁移步长
* */
for (int i = 0, bound = 0; ; ){
/** 计算迁移下标:i 和 bound */
while (advance){
int nextIndex= transferIndex;
int nextBound = (nextIndex > stride ? nextIndex - stride : 0);
/**
* --i >= bound:从后往前依次递减
* */
if(--i >= bound){
advance = false;
/**
* 以下情况会进入下面这个分支
* 1、迁移区域已经被分配完,没有分配到迁移区域的线程。迁移区域分配完,意味着transferIndex为0
* 2、被分配到[0,stride]区域的线程,在完成数据迁移后,i 自减到 -1
* 3、没有分配到 [0,stride] 区域的线程完成了分配区域的数据迁移之后,没有空闲区域需要线程来迁移数据;这个时候会将i设置为-1
* */
}else if(nextIndex <= 0){
i = -1; /** 标记下标为-1,会进入下面校验是否迁移完成的分支,进行检查迁移情况 */
advance = false;
/**
* 更新迁移下标,考虑并发情况下多个线程同时争抢,使用CAS来设置
*
* 例:[0,16]
* TRANSFERINDEX = 0,i=15,bound=0
*
* 例:[0,32]
* 第一个线程:TRANSFERINDEX = 16,i=31,bound=16
* 第二个线程:TRAN11SFERINDEX = 0,i=15,bound=0
*
* */
}else if(U.compareAndSwapInt(this, TRANSFERINDEX, nextIndex, nextBound)){
/** 设置迁移结束下标 */
bound = nextBound;
/** 设置结束下标,nextIndex为旧数组长度,所以需要-1 */
i = nextIndex -1;
advance = false;
}
}
Node<K,V> f = null;
/** 迁移完成会进入此分支 */
if(i < 0){
int sc = sizeCtl;
if(U.compareAndSwapInt(this, SIZE_CTL, sc, sc - 1)){
/**
*
* 初始扩容:(rs << RESIZE_STAMP_SHIFT) + 2
* 结束条件:(sc - 2) != resizeStamp(n) << 16
* 其中:
* (rs << RESIZE_STAMP_SHIFT) == resizeStamp(n) << 16
* 如果他两相等表示,没有线程在扩容完成,否则正在扩容
*
* */
if ((sc - 2) != (resizeStamp(n) << 16))
return;
tab = nextTab;
nextTable = null;
sizeCtl = nextTab.length - (nextTab.length >>> 2);
return;
}
}else if((f = tabAt(oldTab, i)) == null){ /** 节点为空直接占位 */
advance = casTabAt(oldTab, i, null, fwd);
}else { /** 不为空节点:链表或红黑树 */
synchronized (f) {
/**
* 简单处理:计算扩容之后的新下标,直接赋予
* */
int newIndex = (nextTab.length - 1) & f.hash;
int oldIndex = (n - 1) & f.hash;
setTabAt(nextTab, newIndex, f);
setTabAt(oldTab, oldIndex, fwd);
advance = true;
}
}
}
}
/**
* 初始化数组
* TODO 此方法仿照源码中 initTable() 方法,主要的目的是体验初始化时巧妙的设计和CAS的使用
*/
private void initTable() {
int sc = 0;
while (tab == null || tab.length == 0){
/** 如果标记小于0,表示正在初始化 */
if(sizeCtl < 0){
Thread.yield(); //TODO 让CPU放弃线程执行权,也就是让其他线程执行,这个方法用过的人应该很少吧!
/**
* 不等于0。使用cas初始标识为正在初始化-1,达到线程安全
* 解释:第一次进来之后,sc和sizeCtl的值都为0,因为使用的是CAS,所以就算多个线程并发执行,只会有一个线程更新成功
* */
}else if(U.compareAndSwapInt(this, SIZE_CTL, sc, -1)){
/** 初始化数组,长度:16 */
tab = new Node[DEFAULT_CAPACITY];
/**
* 下面这句代码的意思:
* DEFAULT_CAPACITY - (DEFAULT_CAPACITY >>> 2) == DEFAULT_CAPACITY * 0.75
* */
sizeCtl = DEFAULT_CAPACITY - (DEFAULT_CAPACITY >>> 2);
}
}
}
/** 声明全局的 Unsafe */
private static Unsafe U = null;
/**
*
* 偏移量的定义:使用cas更新时,需要传入字段的偏移量
* sizeCtl 的偏移量
*/
static long SIZE_CTL = 0;
static long TRANSFERINDEX = 0;
private static long ABASE = 0;
private static int ASHIFT = 0;
/** 使用静态代码块来初始化 Unsafe,类似于单例的效果 */
static {
try {
U = getUnsafe();
Class<?> c = MyConcurrentMap.class;
/** 赋值偏移量 */
SIZE_CTL = U.objectFieldOffset(c.getDeclaredField("sizeCtl"));
TRANSFERINDEX = U.objectFieldOffset(c.getDeclaredField("transferIndex"));
Class<?> ak = Node[].class;
// 获取数组中第一个元素的地址
ABASE = U.arrayBaseOffset(ak);
// 获取数组中第一个元素占用的字节数
int scale = U.arrayIndexScale(ak);
// 返回无符号整型i的最高非零位前面的n个0的个数,包括符号位
ASHIFT = 31 - Integer.numberOfLeadingZeros(scale);
}catch (Exception e){
throw new Error(e);
}
}
/**
* 使用反射构建 Unsafe
* 因为:Unsafe类位于rt.jar,会对调用者的classLoader进行检查,
* 判断当前类是否由Bootstrap classLoader加载,如果不是的话那么就会抛出一个SecurityException异常
* */
public static Unsafe getUnsafe() throws IllegalAccessException, NoSuchFieldException {
Field unsafeField = Unsafe.class.getDeclaredField("theUnsafe");
//Field unsafeField = Unsafe.class.getDeclaredFields()[0]; //也可以这样,作用相同
unsafeField.setAccessible(true);
Unsafe unsafe =(Unsafe) unsafeField.get(null);
return unsafe;
}
/**
* 获取当前对象var1在该对象指定偏移量var2上的值,从而保证线程之间的可见性
* @param tab 数组
* @param i 偏移量
* @return 对应下标对象
*/
static <K,V> Node<K,V> tabAt(Node<K, V>[] tab, int i) {
return (Node<K, V>) U.getObjectVolatile(tab, ((long) i << ASHIFT) + ABASE);
}
/**
* 设置值的时候强制更新到主存,从而保证这些变更对其他线程是可见的。
* @param tab 数组
* @param i 偏移量
* @param node 待设置对象
*/
static <K, V> void setTabAt(Node<K, V>[] tab, int i, Node<K, V> node) {
U.putObjectVolatile(tab, ((long) i << ASHIFT) + ABASE, node);
}
/**
* 使用CAS设置对应位置元素,保证:一致性、安全性
* @param tab 数组
* @param i 偏移量
* @param c 期待值
* @param v 待修改值
* @return 是否成功
*/
static <K,V> boolean casTabAt(Node<K, V>[] tab, int i,
Node<K, V> c, Node<K, V> v) {
return U.compareAndSwapObject(tab, ((long) i << ASHIFT) + ABASE, c, v);
}
/**
* 转换为红黑树
* 数组长度大于等于64,并且链表长度大于等于7
*
* @param index
*/
private void convertRBT(Integer index) {
//TODO 预留 如果数组长度小于64,直接进行扩容
Node<K, V> node = tab[index];
//TODO 转换为红黑树之后不保留之前的链表结构,源代码中是有保留链表结构:
// 1. 维护两种数据结构是为了在不同负载情况下优化性能。在哈希表的生命周期内,可能会经历不同的负载阶段,有些阶段适合链表,有些阶段适合红黑树。动态地在这两者之间切换,可以在不同负载情况下兼顾时间和空间的性能。
// 2. 节点数量小于等于6的时候,会把红黑树转为链表继续存储,具体方法代码: # final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit)
/** 构建红黑树对象 */
TreeNode<K, V> treeNode = new TreeNode<K, V>();
do {
/** 插入红黑树 */
treeNode.add(node.key, node.value, node.hash, node.next);
node = node.next;
}while (node != null);
/** 更新数组指向为红黑树 */
tab[index] = treeNode;
}
/**
* 获取元素
* @param k key
* @return 值
*/
public V get(K k){
/** 校验数组是否为空 */
if (tab == null) {
return null;
}
/** 根据key获取哈希值 */
int hashCode = getHashCode(k);
/** 计算哈希桶下标 */
int i = (tab.length - 1) & hashCode;
/** 校验单个哈希桶是否为空 */
if (tab[i] != null) {
/** 获取哈希桶 */
Node<K, V> node = tab[i];
/** 校验节点是否红黑树 */
if(node instanceof TreeNode){
TreeNode<K, V> treeNode = (TreeNode<K, V>) node;
node = treeNode.getNode(k);
if (node != null) {
return node.value;
}
}else { /** 链表结构 */
do {
/** 链表结构 */
if (node.key == k || node.key.equals(k)) {
return node.value;
}
node = node.next;
}while (node != null);
}
}
return null;
}
/**
* 删除方法
* @param k key
* @return 值
*/
public V remove(K k){
/** 校验数组或者key是否为空 */
if (tab == null || k == null) {
return null;
}
/** 根据key获取哈希值 */
int hashCode = getHashCode(k);
/** 计算哈希桶下标 */
int i = (tab.length - 1) & hashCode;
if(tab[i] != null){
Node<K, V> node = tab[i];
/** 如果是红黑树,调用红黑树删除 */
if(node instanceof TreeNode){
TreeNode<K, V> treeNode = ((TreeNode) node);
treeNode.remove(k);
tab[i] = treeNode;
return node.value;
}else { /** 处理链表情况 */
if(node !=null && node.next == null){
if (node.key == k || node.key.equals(k)) {
tab[i] = null;
return node.value;
}
}
while (node != null && node.next != null) {
/** 链表结构 */
if (node.next.key == k || node.next.key.equals(k)) {
node.next = (node.next.next);
tab[i] = node;
return node.next.value;
}
node = node.next;
}
}
}
throw new IllegalArgumentException("invalid key");
}
/**
* 获取HashCode
* @param k key
* @return 哈希值
*/
private int getHashCode(K k) {
return k == null ? 0 : k.hashCode();
}
/**
* 链表
* @param <K>
* @param <V>
*/
static class Node<K,V>{
/** 哈希值 */
int hash;
/** K */
K key;
/** V */
V value;
/** 下一个 */
Node<K,V> next;
public Node() {
}
public Node(int hash, K key, V value, Node<K, V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
/**
* 扩容节点
* @param <K>
* @param <V>
*/
static final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K, V>[] nextTable) {
super(MOVED, null, null, null);
this.nextTable = nextTable;
}
}
/**
* 红黑树
* @param <K>
* @param <V>
*/
static class TreeNode<K extends Comparable<K>, V> extends Node<K,V>{
public TreeNode() {
super();
}
TreeNode(int hash, K key, V value, Node<K, V> next) {
super(hash, key, value, next);
}
boolean red;
TreeNode<K, V> parent;
TreeNode<K, V> left;
TreeNode<K, V> right;
TreeNode<K, V> root;
public void add(K k, V v, Integer hash, Node<K,V> next){
TreeNode<K, V> node = new TreeNode<K, V>(hash, k, v, next);
if (root == null) {
root = node;
}else{
node.red = true;
TreeNode<K, V> tempNode = root;
for(;;){
int i = k.compareTo(tempNode.key);
/** 小于的话从左边插入 */
if (i < 0) {
if (tempNode.left == null) {
node.parent = tempNode;
tempNode.left = node;
break;
}
tempNode = tempNode.left;
/** 大于的话从右边插入 */
}else if (i > 0){
if (tempNode.right == null) {
node.parent = tempNode;
tempNode.right = node;
break;
}
tempNode = tempNode.right;
/** 等于更新值 */
}else {
node.value = v;
return;
}
}
balanceInsertion(node);
}
}
private void balanceInsertion(TreeNode<K, V> node) {
if (node != null && node != root && node.parent.red) {
/** 校验当前是否是左子树 */
if(node.parent == node.parent.parent.left){
/**
*
* 校验是否存在叔叔节点,如果存在
* 1.父亲节点和叔叔节点变为黑色
* 2.爷爷节点变为红色
* 3.以爷爷节点进行递归插入(防止爷爷节点之上还有其余节点,导致整棵树不平衡)
*
* 3
* / \
* 1 4
* /
* 0
*
* */
if(node.parent.parent.right != null && node.parent.parent.right.red){
node.parent.red = false;
node.parent.parent.right.red = false;
node.parent.parent.red = true;
balanceInsertion(node.parent.parent);
}else { /** 不存在叔叔节点 */
/**
*
* 校验节点是否在右侧,如果是,首先以父亲节点进行一次左旋操作,变成普通左子树
*
* 3 3
* / /
* 1 2
* \ /
* 2 1
*
* */
if(node == node.parent.right){
/** 左旋 */
rotateLeft(node.parent);
}
/**
*
* 如果是普通左子树
* 1.父亲节点变为黑色
* 2.爷爷节点变为红色
* 3.然后进行右旋
* 4.以爷爷节点进行递归插入(防止爷爷节点之上还有其余节点,导致整棵树不平衡)
*
* 3 1
* / / \
* 1 0 3
* /
* 0
*
* */
/** 变色 */
node.parent.red = false;
node.parent.parent.red = true;
/** 右旋 */
rotateRight(node.parent.parent);
/** 继续向上递归 */
balanceInsertion(node.parent.parent);
}
}else { /** 右子树 */
/**
*
* 校验是否存在叔叔节点,如果存在
* 1.父亲节点和叔叔节点变为黑色
* 2.爷爷节点变为红色
* 3.以爷爷节点进行递归插入(防止爷爷节点之上还有其余节点,导致整棵树不平衡)
*
* 3
* / \
* 1 4
* \
* 0
*
* */
if(node.parent.parent.left != null && node.parent.parent.left.red){
node.parent.red = false;
node.parent.parent.left.red = false;
node.parent.parent.red = true;
balanceInsertion(node.parent.parent);
}else { /** 不存在叔叔节点 */
/**
*
* 校验节点是否在左侧,如果是,以父亲节点进行一次右旋操作,变成普通右子树
*
* 3 3
* \ \
* 1 2
* / \
* 2 1
*
* */
if(node == node.parent.left){
/** 右旋 */
rotateRight(node.parent);
}
/**
*
* 如果是普通右子树
* 1.父亲节点变为黑色
* 2.爷爷节点变为红色
* 3.然后进行左旋
* 4.以爷爷节点进行递归插入(防止爷爷节点之上还有其余节点,导致整棵树不平衡)
*
* 3 1
* \ / \
* 1 0 3
* \
* 0
*
* */
/** 变色 */
node.parent.red = false;
node.parent.parent.red = true;
/** 右旋 */
rotateLeft(node.parent.parent);
/** 继续向上递归 */
balanceInsertion(node.parent.parent);
}
}
}
root.red = false;
}
public void remove(K k){
/** 查找到节点 */
TreeNode<K, V> node = getNode(k);
if (node == null) {
return;
}
/** 第三种情况:删除结点有两个叶子节点,需要使用前驱查找或者后继查找来替换 */
if (node.left != null && node.right != null){
/** 采用前驱查找 */
TreeNode<K, V> n = precursorFind(node);
/** 修改值为待删除的值 */
node.value = n.value;
/**
* 把当前要删除的节点修改为后继查找的节点
*
* 3
* / \
* 2 10 -- 11 比如这个时候要删除 10节点,我们通过(后继查找)查找到了 11节点,
* / \ 只需要将10修改为11,然后删除 11节点即可
* 9 11 -- 删除
*
*/
node = n;
}
/** 找到需要替换的节点 */
TreeNode<K, V> n = node.left != null ? node.left : node.right;
/** 第二种情况:删除节点有一个叶子节点的,那么用叶子节点来代替 */
if(n != null){
/** 直接关联,跳过待删除节点 */
n.parent = node.parent;
/** 如果删除节点的父节点为空,表示删除之后只会存在一个节点,直接指向root */
if(node.parent == null){
root = n;
/** 如果删除节点在父节点的左边,把替换节点关联到父节点的左边 -> 双向绑定 */
}else if(node == node.parent.left){
node.parent.left = n;
/** 如果删除节点在父节点的右边,把替换节点关联到父节点的右边 -> 双向绑定 */
}else {
node.parent.right = n;
}
/** help GC */
node.right = node.left = node.parent = null;
/** 调整红黑树平衡,只有删除黑色节点时,需要调整平衡,因为其余的都是修改,不会发生树调整 */
if(!node.red){
fixTree(n);
}
/** 第一种情况:删除叶子节点,直接删除 */
}else {
/** 此处需要先进行调整平衡,然后再删除 */
if(!node.red){
fixTree(node);
}
/** 如果只有一个叶子节点,并且没有父类,删除之后,整棵树为空,置空root节点 */
if (node.parent == null) {
root = null;
/** 如果删除节点在父节点的左边,把替换节点关联到父节点的左边 -> 双向绑定 */
}else if (node == node.parent.left) {
node.parent.left = null;
/** 如果删除节点在父节点的右边,把替换节点关联到父节点的右边 -> 双向绑定 */
}else {
node.parent.right = null;
}
/** help GC */
node.parent = null;
}
}
/**
* 调整树平衡
* @param node
*/
private void fixTree(TreeNode<K, V> node) {
while (node != root && !node.red){
/** 校验节点是左节点还是右节点 */
if(node == node.parent.left){
/** 获取兄弟节点 */
TreeNode<K, V> r = node.parent.right;
// 校验是不是真的兄弟节点
if(r.red){
r.red = false;
node.parent.red = true;
rotateLeft(node.parent);
r = node.parent.right;
}
/** 当兄弟节点一个子节点都没有,或者两个子节点都是黑色 */
if (r.left == null && r.right == null || ((r.left != null && !r.left.red) && (r.right != null && !r.right.red))) {
r.red = true;
node = node.parent;
}else { /** 至少存在一个子节点 */
/**
* 如果兄弟节点的子节点是左子节点,需要变色 + 右旋
* */
if(r.right == null){ /** 如果兄弟节点的右子节点为空,左子节点肯定不为空,因为兄弟节点没有子节点的时候,只会进入上的if */
r.red = true;
r.left.red = false;
rotateRight(r);
/** 右旋之后,兄弟节点发生变化,需要重新指定 */
r = node.parent.right;
}
/** 然后根据父节点进行左旋 + 变色 */
r.red = node.parent.red;
node.parent.red = r.right.red = false;
rotateLeft(node.parent);
node = root; /** 退出循环 */
}
}else {
/** 获取兄弟节点 */
TreeNode<K, V> r = node.parent.left;
// 校验是不是真的兄弟节点
if(r.red){
r.red = false;
node.parent.red = true;
rotateRight(node.parent);
r = node.parent.left;
}
/** 当兄弟节点一个子节点都没有,或者两个子节点都是黑色 */
if (r.left == null && r.right == null || ((r.left != null && !r.left.red) && (r.right != null && !r.right.red))) {
r.red = true;
node = node.parent;
}else { /** 至少存在一个子节点 */
/**
* 如果兄弟节点的子节点是左子节点,需要变色 + 右旋
* */
if(r.left == null){ /** 如果兄弟节点的右子节点为空,左子节点肯定不为空,因为兄弟节点没有子节点的时候,只会进入上的if */
r.red = true;
r.right.red = false;
rotateLeft(r);
/** 右旋之后,兄弟节点发生变化,需要重新指定 */
r = node.parent.left;
}
/** 然后根据父节点进行左旋 + 变色 */
r.red = node.parent.red;
node.parent.red = r.left.red = false;
rotateRight(node.parent);
node = root; /** 退出循环 */
}
}
}
node.red = false;
}
public TreeNode<K, V> getNode(K k){
TreeNode<K, V> node = root;
while (node != null && k != null){
int i = k.compareTo(node.key);
if(i < 0){
node = node.left;
}else if(i > 0){
node = node.right;
}else {
return node;
}
}
return null;
}
/**
*
* 左旋:
* <p>
* 3 6
* / \ / \
* 2 6 3 7
* / \ / \
* 5 7 2 5
*/
private void rotateLeft(TreeNode<K, V> node) {
/** 获取右子节点 -> 6 */
TreeNode<K, V> r = node.right;
/** node右子节点设置为 r节点的左子节点 -> ( 3的右子节点设置为5 )*/
node.right = r.left;
/** 校验 r的左子节点 是否为空 */
if (r.left != null) {
/** 设置 r的左子节点父类为node -> ( 5的父类设置为3 ) */
r.left.parent = node;
}
/** 将6的父类设置为3的父类 */
r.parent = node.parent;
/** 校验node节点是否存在父类 */
if(node.parent == null){
/** 根节点直接设置为 r -> ( 根节点直接设置为6 ) */
root = r;
}else if (node.parent.left == node) { /** 校验 node 节点是存在父类的哪边 -> 左 */
node.parent.left = r;
}else { /** 右 */
node.parent.right = r;
}
/** 交换位置 -> (6和3交换位置) */
node.parent = r;
r.left = node;
}
/**
* 右旋:
* <p>
* 6 3
* / \ / \
* 3 7 2 6
* / \ / \
* 2 5 5 7
*
*/
private void rotateRight(TreeNode<K, V> node) {
/** 获取左子节点 -> (3) */
TreeNode<K, V> l = node.left;
/** 更新node左节点为 l的右节点 -> ( 6的左子节点更新为5 ) */
node.left = l.right;
/** 校验 l的右节点 是否为空,不为空的时候进行双向关联 -> ( 5的父类更新为6 )*/
if (l.right != null) {
l.right.parent = node;
}
/** 将3的父类设置为6的父类 */
l.parent = node.parent;
if (node.parent == null) {
/** 根节点直接设置为 r -> ( 根节点直接设置为3 ) */
root = l;
}else if (node.parent.left == node) { /** 校验 node 节点是存在父类的哪边 -> 左 */
node.parent.left = l;
}else { /** 右 */
node.parent.right = l;
}
/** 交换位置 -> (6和3交换位置) */
node.parent = l;
l.right = node;
}
/**
* 前驱节点查询
* 树右边最大的节点
* @param node
* @return
*/
private TreeNode<K, V> precursorFind(TreeNode<K, V> node){
node = node.left;
if (node == null) {
return null;
}
while (node.right != null) {
node = node.right;
}
return node;
}
/**
* 后继节点查询
* 树左边最小的节点
* @param node
* @return
*/
private TreeNode<K, V> subsequentFind(TreeNode<K, V> node){
node = node.right;
if (node == null) {
return null;
}
while (node.left != null) {
node = node.left;
}
return node;
}
}
}















 899
899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









