







1.背景介绍
1.1.问题场景
基于MinIO做二次开发,统计各个bucket的存储情况,文件类型个数。由于MinIO没有提供现成的API来获取以上的信息,因此只能先通过现有的API获取到桶及桶里的文件。将这些桶里的文件,存入集合,遍历判断每个文件是哪个类型,遍历累加每个文件的大小。
1.2.传统手段的瓶颈
bucket里面的文件如果比较少,利用传统的集合遍历的方式计算,也能得出结果,不会有太多瓶颈。但是如果bucket里面的文件非常多,几百甚至上千个文件,而且随着系统的使用,存入到bucket的文件会越来越多。再通过传统遍历的方式计算,得出一个结果可能要几十秒甚至几分钟,这显然不是我们想要的结果。因此,从软件设计的长远来看,我们要考虑新手段来应对这种场景。
2.多线程实现
2.1.实现思路
假设这个List集合元素非常多,那么我们需要有“拆分”的思想,将这个大集合拆分等分的小集合,再对每个小集合中的元素做处理。接着将每个小集合元素处理的结果进行汇总,最终得到的就是大集合中所有元素的计算总和。
我们需要用到线程池来合理分配创建的线程。使用Callable和Future来实现获取任务结果的操作,Callable用来执行任务,产生结果,而Future用来获得结果。简单一句话,利用多线程来处理多任务量实现高效计算。
2.2.实现过程
2.2.1.创建线程池
package com.calvin.tech.storage.util;
import com.google.common.util.concurrent.ThreadFactoryBuilder;
import lombok.extern.slf4j.Slf4j;
import java.util.concurrent.*;
/**
* @Author calvin
* @Date 2021/11/10 10:15
* @Description 创建线程池工具类
* @Version 1.0
*/
@Slf4j
public class ThreadFactoryUtil {
// 基于数组的阻塞队列
private static BlockingQueue<Runnable> blockingQueue = new LinkedBlockingQueue<>(100);
private ThreadFactoryUtil() {
}
public static ThreadPoolExecutor getThreadFactoryUtilInstance(int threadNum) {
ThreadFactory factory = new ThreadFactoryBuilder().setNameFormat("splitlist-pool-%d").build();
ThreadPoolExecutor pool = new ThreadPoolExecutor(threadNum, threadNum, 3L,
TimeUnit.SECONDS, blockingQueue, factory,
// 自定义策略
(r, executor) -> {
try {
if (!executor.isShutdown()) {
while (executor.getQueue().remainingCapacity() == 0) {
log.info("队列满啦,而且线程数量达到最大数量啦!");
executor.getQueue().put(r);
}
}
} catch (Exception e) {
log.info("塞入队列异常啦!发邮件报警给运维");
}
// log.info("塞进队列成功!");
});
pool.allowCoreThreadTimeOut(true);
return pool;
}
}
这里线程池的corePoolSize,maximumPoolSize可以根据任务总量/每个小集合数量计算得出。当然也可以根据实际情况自行设置。
2.2.2.编写每个task任务的逻辑
package com.calvin.tech.storage.service;
import com.calvin.tech.storage.dto.CalculateSmallListDTO;
import io.minio.messages.Item;
import java.util.List;
/**
* @Author calvin
* @Date 2021/11/10 10:20
* @Description 集合的数据拆分
* @Version 1.0
*/
public interface ThreadSplitListService {
/**
* 集合数据拆分
*
* @param items
* @return
*/
CalculateSmallListDTO execMethod(List<Item> items) throws Exception;
}
package com.calvin.tech.storage.service.impl;
import com.calvin.tech.storage.dto.CalculateSmallListDTO;
import com.calvin.tech.storage.service.ThreadSplitListService;
import com.calvin.tech.storage.util.FileHandleUtil;
import io.minio.messages.Item;
import lombok.extern.slf4j.Slf4j;
import org.springframework.stereotype.Service;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
import java.util.stream.Collectors;
/**
* @Author calvin
* @Date 2021/11/10 10:23
* @Description 集合的数据拆分
* @Version 1.0
*/
@Service
@Slf4j
public class ThreadSplitListServiceImpl implements ThreadSplitListService {
private Map<String, String> fileMap = FileHandleUtil.FILE_TYPE_MAP;
/**
* 集合数据拆分
*
* @param items
* @return
*/
@SuppressWarnings("unchecked")
@Override
public CalculateSmallListDTO execMethod(List<Item> items) throws Exception {
CalculateSmallListDTO calculateSmallListDTO = new CalculateSmallListDTO();
// 表示处理自己的业务逻辑
log.info("线程:" + Thread.currentThread().getName());
// 可以通过传递过来的参数来做自己想要处理的业务
Map<String, Integer> fileTypeMap = new ConcurrentHashMap<>();
for (Item item : items) {
// 文件名称
// 2021-02-24/CIO寄语-20210224174044.png、2021-03-16/机房综合布线标准-20200424-20210316162927.docx
String objectName = item.objectName();
String fileTyle = objectName.substring(objectName.lastIndexOf("."));
if (fileMap.get(fileTyle) != null) {
String value = fileMap.get(fileTyle);
if (fileTypeMap.get(value) == null) {
fileTypeMap.put(value, 1);
} else {
// 文件类型
Integer typeCount = fileTypeMap.get(value) == null ? 0 : fileTypeMap.get(value);
typeCount++;
fileTypeMap.put(value, typeCount);
}
} else {
if (fileTypeMap.get("other") == null) {
fileTypeMap.put("other", 1);
} else {
// 文件类型
Integer typeCount = fileTypeMap.get("other") == null ? 0 : fileTypeMap.get("other");
typeCount++;
fileTypeMap.put("other", typeCount);
}
}
}
Long hasUsedStorage = items.stream().parallel().collect(Collectors.summarizingLong(Item::objectSize)).getSum();
// 文件类型数量
calculateSmallListDTO.setFileTypeMap(fileTypeMap);
// 已使用容量
calculateSmallListDTO.setHasUsedStorage(hasUsedStorage);
return calculateSmallListDTO;
}
}
其中FileHandleUtil类表示根据文件名的后缀做相应文件类型的归类。
package com.calvin.tech.storage.util;
import java.text.DecimalFormat;
import java.text.NumberFormat;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* @Author calvin
* @Date 2021/11/10 16:00
* @Description
* @Version 1.0
*/
public class FileHandleUtil {
public final static Map<String, String> FILE_TYPE_MAP = new HashMap<>();
static {
initFileTypeMap(); // 初始化文件类型信息
}
/**
* 常用文件格式
*/
private static void initFileTypeMap() {
FILE_TYPE_MAP.put(".jpg", "picture");
FILE_TYPE_MAP.put(".gif", "picture");
FILE_TYPE_MAP.put(".png", "picture");
FILE_TYPE_MAP.put(".tif", "picture");
FILE_TYPE_MAP.put(".bmp", "picture");
FILE_TYPE_MAP.put(".doc", "word");
FILE_TYPE_MAP.put(".docx", "word");
FILE_TYPE_MAP.put(".xls", "excel");
FILE_TYPE_MAP.put(".xlsx", "excel");
FILE_TYPE_MAP.put(".ppt", "ppt");
FILE_TYPE_MAP.put(".pptx", "ppt");
FILE_TYPE_MAP.put(".pdf", "pdf");
FILE_TYPE_MAP.put(".txt", "txt");
FILE_TYPE_MAP.put(".mpeg", "video");
FILE_TYPE_MAP.put(".avi", "video");
FILE_TYPE_MAP.put(".mov", "video");
FILE_TYPE_MAP.put(".wmv", "video");
FILE_TYPE_MAP.put(".rmvb", "video");
FILE_TYPE_MAP.put(".mp4", "video");
FILE_TYPE_MAP.put(".other", "other");
}
/**
* 将字节B转为可读的MB,KB,GB
*
* @param file
* @return
*/
public static String formatFileSize(long file) {
DecimalFormat df = new DecimalFormat("#.00");
String fileSizeString = "";
if (file < 1024) {
fileSizeString = df.format((double) file) + "B";
} else if (file < 1048576) {
fileSizeString = df.format((double) file / 1024) + "K";
} else if (file < 1073741824) {
fileSizeString = df.format((double) file / 1048576) + "M";
} else {
fileSizeString = df.format((double) file / 1073741824) + "G";
}
return fileSizeString;
}
/**
* 判断str1中包含str2的个数
*
* @param input
* @param sub
* @return
*/
public static int getCount(String input, String sub) {
if (input.length() <= 0) return 0;
int count = 0;
String inputString = input.toUpperCase();
char subChar = sub.toUpperCase().charAt(0);
for (int i = 0; i < input.length(); i++) {
if (subChar == inputString.charAt(i))
count++;
}
return count;
}
/**
* 计算文件类型所占百分比
*
* @param fileTypeMap
* @param dataSize
* @return
*/
public static Map<String, String> getFilePercentage(Map<String, Integer> fileTypeMap, Integer dataSize) {
Map<String, String> filePercentageMap = new ConcurrentHashMap<>();
NumberFormat instance = NumberFormat.getInstance();
// 保留小数点后两位(四舍五入),
instance.setMaximumFractionDigits(2);
// 将总数转为Double类型
Double totalNum = Double.valueOf(dataSize);
for (String key : fileTypeMap.keySet()) {
// 文件类型数
int fileTypeNum = fileTypeMap.get(key);
String filePercentage = instance.format(fileTypeNum / totalNum * 100) + "%";
filePercentageMap.put(key, filePercentage);
}
return filePercentageMap;
}
}
计算结果定义CalculateSmallListDTO,包含已使用容量,文件类型:数量
package com.calvin.tech.storage.dto;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.util.Map;
/**
* @Author calvin
* @Date 2021/11/10 13:25
* @Description
* @Version 1.0
*/
@ApiModel(description = "计算小集合统计", value = "计算小集合统计")
@Data
public class CalculateSmallListDTO {
@ApiModelProperty(value = "已使用容量")
private Long hasUsedStorage;
@ApiModelProperty(value = "文件类型:数量")
private Map<String, Integer> fileTypeMap;
}
2.2.3.拆分集合提交task任务
package com.calvin.tech.storage.util;
import java.util.*;
import java.util.concurrent.*;
import java.util.stream.Collectors;
import com.calvin.tech.storage.dto.CalculateBucketDTO;
import com.calvin.tech.storage.dto.CalculateSmallListDTO;
import com.calvin.tech.storage.service.ThreadSplitListService;
import io.minio.Result;
import io.minio.messages.Item;
import lombok.extern.slf4j.Slf4j;
import org.apache.commons.collections4.CollectionUtils;
/**
* @Author calvin
* @Date 2021/11/10 10:30
* @Description 集合拆分工具类
* @Version 1.0
*/
@Slf4j
public class CollectionSplitUtil {
@SuppressWarnings("unchecked")
public static CalculateBucketDTO threadSplitList(ThreadSplitListService threadSplitList, Iterable<Result<Item>> it, int size) throws Exception {
CalculateBucketDTO calculateBucketDTO = new CalculateBucketDTO();
if (it == null) {
return calculateBucketDTO;
}
// 如果size为空则默认给个数值默认50条数据开启一个线程
if (size <= 0) {
size = 50;
}
List<Item> items = new ArrayList<>();
for (Result<Item> result : it) {
Item item = result.get();
items.add(item);
}
// 记录开始时间
long time = System.currentTimeMillis();
// 总数据条数
int dataSize = items.size();
// 线程数
int threadNum = dataSize / size + 1;
// 定义标记
boolean special = dataSize % size == 0;
// 创建线程池
ThreadPoolExecutor exec = ThreadFactoryUtil.getThreadFactoryUtilInstance(threadNum);
try {
// 定义任务集合
List<Callable<CalculateSmallListDTO>> tasks = new ArrayList<>();
Callable task;
List<Item> cutList;
// 分割集合数据,放入对应的线程中
for (int i = 0; i < threadNum; i++) {
// 判断是否是最后一个线程
if (i == threadNum - 1) {
if (special) {
break;
}
cutList = items.subList(size * i, dataSize);
} else {
cutList = items.subList(size * i, size * (i + 1));
}
final List<Item> tempList = cutList;
// 创建任务
task = new Callable() {
@Override
public Object call() throws Exception {
return threadSplitList.execMethod(tempList);
}
};
tasks.add(task);
}
// 获取task执行后的结果
List<Future<CalculateSmallListDTO>> futureList = exec.invokeAll(tasks);
// 定义拆分小集合的计算结果集合
List<CalculateSmallListDTO> smallList = new ArrayList<>();
for (Future<CalculateSmallListDTO> future : futureList) {
try {
// 获取结果
CalculateSmallListDTO calculateSmallListDTO = future.get();
smallList.add(calculateSmallListDTO);
} catch (ExecutionException e) {
e.printStackTrace();
}
}
if (CollectionUtils.isNotEmpty(smallList)) {
Long hasUsedStorage = smallList.stream().parallel().collect(Collectors.summarizingLong(CalculateSmallListDTO::getHasUsedStorage)).getSum();
String bucketStorageSize = FileHandleUtil.formatFileSize(hasUsedStorage);
calculateBucketDTO.setHasUsedStorage(bucketStorageSize);
calculateBucketDTO.setFileTotalNum(String.valueOf(dataSize));
// 文件类型:数量
List<Map<String, Integer>> fileTypeList = smallList.stream().map(CalculateSmallListDTO::getFileTypeMap).collect(Collectors.toList());
if (CollectionUtils.isNotEmpty(fileTypeList)) {
Map<String, Integer> fileTypeMap = new ConcurrentHashMap<>();
for (Map<String, Integer> map : fileTypeList) {
for (String fileType : map.keySet()) {
if (fileTypeMap.get(fileType) == null) {
fileTypeMap.put(fileType, map.get(fileType));
} else {
Integer count = map.get(fileType);
Integer fileCount = fileTypeMap.get(fileType);
Integer totalFileCount = count + fileCount;
fileTypeMap.put(fileType, totalFileCount);
}
}
}
// 计算文件类型所占百分比
Map<String, String> filePercentageMap = FileHandleUtil.getFilePercentage(fileTypeMap, dataSize);
calculateBucketDTO.setFilePercentageMap(filePercentageMap);
// 文件类型数量
String fileTypeNum = String.valueOf(fileTypeMap.size());
calculateBucketDTO.setFileTypeNum(fileTypeNum);
}
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
log.info("线程任务执行结束,执行任务消耗了:{}毫秒", (System.currentTimeMillis() - time));
exec.shutdown();
}
return calculateBucketDTO;
}
}
2.2.4.多线程计算结果
计算bucket相关信息
/**
* 计算Bucket桶相关信息
*
* @param bucketName
* @return
* @throws Exception
*/
public AjaxResponse<CalculateBucketDTO> getBucketAnalyse(String bucketName) throws Exception {
Iterable<Result<Item>> it = minioClient.listObjects(bucketName);
// 实际业务可以进行注入不同的接口实现类,来处理不同的业务逻辑
// 调用分割集合方法,第一个参数是处理业务逻辑的实现类,第二个是要分割的集合,第三个多少数据进行分割,后面的是处理自己业务用的参数
CalculateBucketDTO calculateBucketDTO = CollectionSplitUtil.threadSplitList(threadSplitListService, it, 50);
// log.info("多线程拆分集合后,给所有子集合元素处理汇总:{}", calculateBucketDTO);
return AjaxResponse.success(calculateBucketDTO);
}
CalculateBucketDTO源码如下:
package com.visionox.tech.storage.dto;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.util.Map;
/**
* @Author calvin
* @Date 2021/11/10 10:22
* @Description
* @Version 1.0
*/
@ApiModel(description = "计算Bucket桶相关信息", value = "计算Bucket桶相关信息")
@Data
public class CalculateBucketDTO {
@ApiModelProperty(value = "已使用容量")
private String hasUsedStorage;
@ApiModelProperty(value = "总文件数量")
private String fileTotalNum;
@ApiModelProperty(value = "文件类型数量")
private String fileTypeNum;
@ApiModelProperty(value = "文件类型名称:百分比")
private Map<String, String> filePercentageMap;
}
编写controller方法
@ApiOperation(value = "bucket桶文件概览")
@GetMapping(value = "/getBucketAnalyse")
public AjaxResponse<CalculateBucketDTO> getBucketAnalyse(@RequestParam(value = "bucketName") String bucketName) throws Exception {
return minIoManageService.getBucketAnalyse(bucketName);
}
测试结果
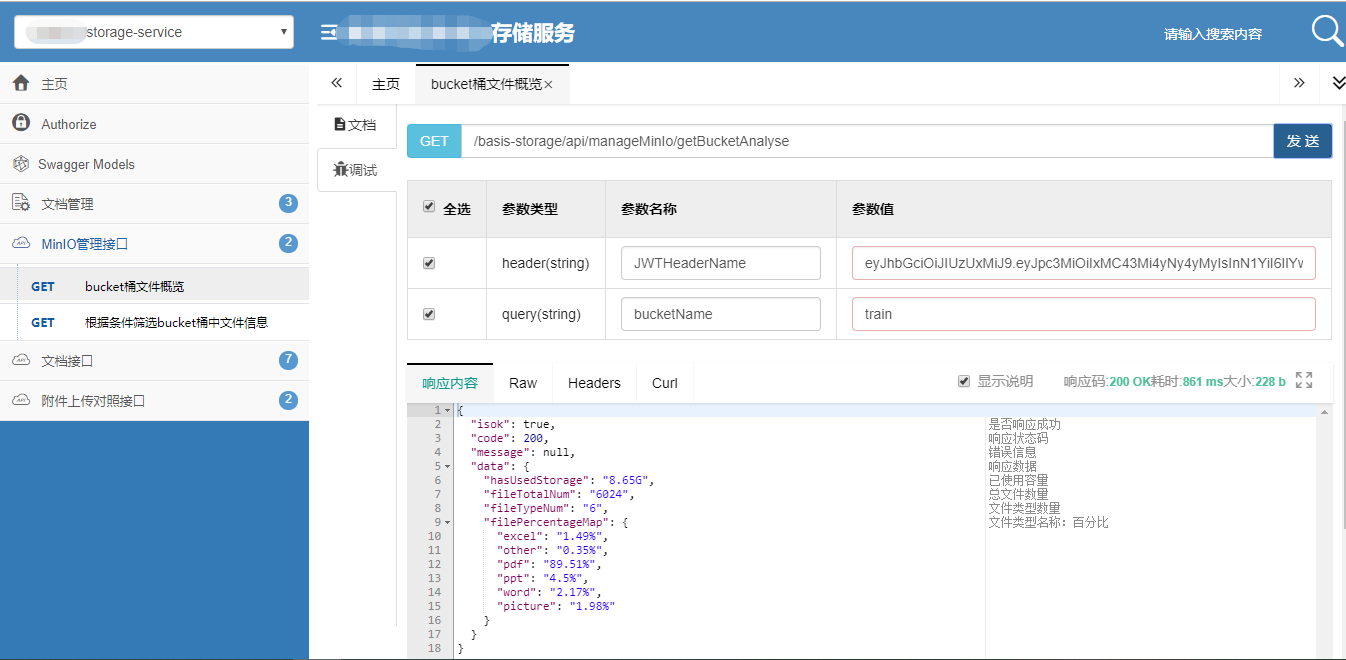
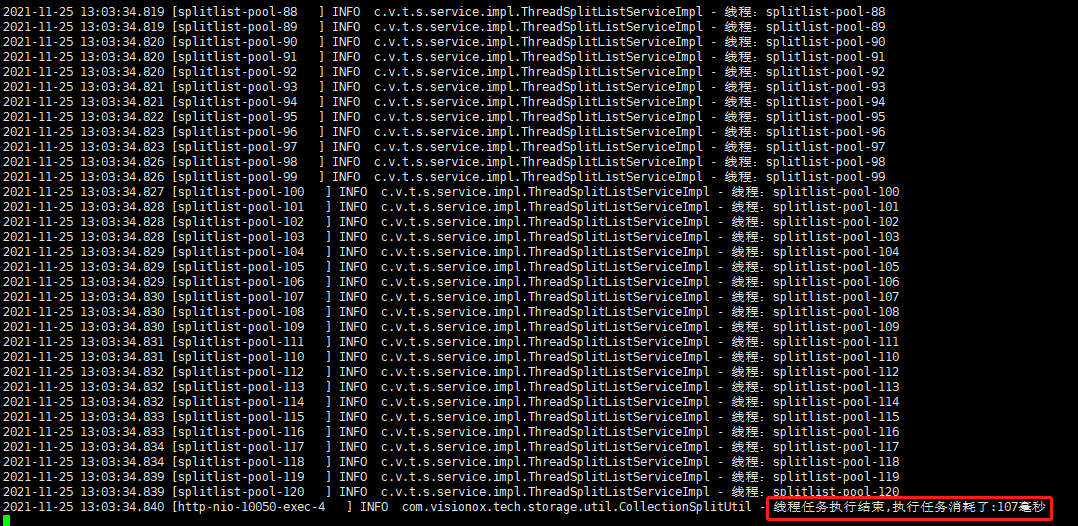
可以看到,train这个桶里面总共6024个文件,线程池创建了120个线程用来计算。任务完成一共消耗107毫秒,如果是传统的遍历一个个计算,程序可能就会直接卡死或者执行计算个几分钟,那显然不是我们想要的结果。















 2178
2178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









